This commit is contained in:
93
src/components/ArchivePanel.astro
Normal file
93
src/components/ArchivePanel.astro
Normal file
@@ -0,0 +1,93 @@
|
||||
---
|
||||
|
||||
import { getSortedPosts } from "../utils/content-utils";
|
||||
import { getPostUrlBySlug } from "../utils/url-utils";
|
||||
|
||||
interface Props {
|
||||
keyword?: string;
|
||||
}
|
||||
|
||||
let posts = await getSortedPosts();
|
||||
|
||||
const groups: { year: number; posts: typeof posts }[] = (() => {
|
||||
const groupedPosts = posts.reduce(
|
||||
(grouped: { [year: number]: typeof posts }, post) => {
|
||||
const year = post.data.published.getFullYear();
|
||||
if (!grouped[year]) {
|
||||
grouped[year] = [];
|
||||
}
|
||||
grouped[year].push(post);
|
||||
return grouped;
|
||||
},
|
||||
{},
|
||||
);
|
||||
|
||||
// convert the object to an array
|
||||
const groupedPostsArray = Object.keys(groupedPosts).map((key) => ({
|
||||
year: Number.parseInt(key),
|
||||
posts: groupedPosts[Number.parseInt(key)],
|
||||
}));
|
||||
|
||||
// sort years by latest first
|
||||
groupedPostsArray.sort((a, b) => b.year - a.year);
|
||||
return groupedPostsArray;
|
||||
})();
|
||||
|
||||
function formatDate(date: Date) {
|
||||
const month = (date.getMonth() + 1).toString().padStart(2, "0");
|
||||
const day = date.getDate().toString().padStart(2, "0");
|
||||
return `${month}-${day}`;
|
||||
}
|
||||
---
|
||||
|
||||
<div class="card-base px-8 py-6">
|
||||
{
|
||||
groups.map(group => (
|
||||
<div>
|
||||
<div class="flex flex-row w-full items-center h-[3.75rem]">
|
||||
<div class="w-[15%] md:w-[10%] transition text-2xl font-bold text-right text-75">{group.year}</div>
|
||||
<div class="w-[15%] md:w-[10%]">
|
||||
<div class="h-3 w-3 bg-none rounded-full outline outline-[var(--primary)] mx-auto -outline-offset-[2px] z-50 outline-3"></div>
|
||||
</div>
|
||||
<div class="w-[70%] md:w-[80%] transition text-left text-50">{group.posts.length} 篇文章</div>
|
||||
</div>
|
||||
{group.posts.map(post => (
|
||||
<a href={getPostUrlBySlug(post.slug)}
|
||||
aria-label={post.data.title}
|
||||
class="group btn-plain !block h-10 w-full rounded-lg hover:text-[initial]"
|
||||
>
|
||||
<div class="flex flex-row justify-start items-center h-full">
|
||||
<!-- date -->
|
||||
<div class="w-[15%] md:w-[10%] transition text-sm text-right text-50">
|
||||
{formatDate(post.data.published)}
|
||||
</div>
|
||||
<!-- dot and line -->
|
||||
<div class="w-[15%] md:w-[10%] relative dash-line h-full flex items-center">
|
||||
<div class="transition-all mx-auto w-1 h-1 rounded group-hover:h-5
|
||||
bg-[oklch(0.5_0.05_var(--hue))] group-hover:bg-[var(--primary)]
|
||||
outline outline-4 z-50
|
||||
outline-[var(--card-bg)]
|
||||
group-hover:outline-[var(--btn-plain-bg-hover)]
|
||||
group-active:outline-[var(--btn-plain-bg-active)]
|
||||
"
|
||||
></div>
|
||||
</div>
|
||||
<!-- post title -->
|
||||
<div class="w-[70%] md:max-w-[65%] md:w-[65%] text-left font-bold
|
||||
group-hover:translate-x-1 transition-all group-hover:text-[var(--primary)]
|
||||
text-75 pr-8 whitespace-nowrap overflow-ellipsis overflow-hidden"
|
||||
>
|
||||
{post.data.title}
|
||||
</div>
|
||||
<!-- tag list -->
|
||||
<div class="hidden md:block md:w-[15%] text-left text-sm transition
|
||||
whitespace-nowrap overflow-ellipsis overflow-hidden
|
||||
text-30"
|
||||
></div>
|
||||
</div>
|
||||
</a>
|
||||
))}
|
||||
</div>
|
||||
))
|
||||
}
|
||||
</div>
|
||||
37
src/components/CategoryPanel.astro
Normal file
37
src/components/CategoryPanel.astro
Normal file
@@ -0,0 +1,37 @@
|
||||
---
|
||||
import type { CollectionEntry } from "astro:content";
|
||||
import { getPostUrlBySlug } from "../utils/url-utils";
|
||||
import { formatDateToYYYYMMDD } from "../utils/date-utils";
|
||||
|
||||
interface Props {
|
||||
posts: CollectionEntry<"posts">[];
|
||||
}
|
||||
|
||||
const { posts } = Astro.props;
|
||||
---
|
||||
|
||||
<div class="flex flex-col gap-3">
|
||||
{posts.map((post) => (
|
||||
<a
|
||||
href={getPostUrlBySlug(post.slug)}
|
||||
class="card-base px-6 py-4 rounded-lg hover:border-[var(--primary)] transition-all group"
|
||||
>
|
||||
<div class="flex items-start gap-4">
|
||||
<div class="text-sm text-50 whitespace-nowrap">
|
||||
{formatDateToYYYYMMDD(post.data.published)}
|
||||
</div>
|
||||
<div class="w-px h-5 bg-[var(--line-divider)]"></div>
|
||||
<div class="flex-1 min-w-0">
|
||||
<h3 class="font-bold text-75 group-hover:text-[var(--primary)] transition-all">
|
||||
{post.data.title}
|
||||
</h3>
|
||||
{post.data.description && (
|
||||
<p class="text-sm text-50 mt-1 line-clamp-1">
|
||||
{post.data.description}
|
||||
</p>
|
||||
)}
|
||||
</div>
|
||||
</div>
|
||||
</a>
|
||||
))}
|
||||
</div>
|
||||
62
src/components/CategoryTree.astro
Normal file
62
src/components/CategoryTree.astro
Normal file
@@ -0,0 +1,62 @@
|
||||
---
|
||||
import type { CategoryNode } from "@/types/config";
|
||||
import { Icon } from "astro-icon/components";
|
||||
|
||||
interface Props {
|
||||
node: CategoryNode;
|
||||
depth?: number;
|
||||
}
|
||||
|
||||
const { node, depth = 0 } = Astro.props;
|
||||
---
|
||||
|
||||
<div class="relative transition-all">
|
||||
<div
|
||||
class:list={[
|
||||
"flex items-center justify-between rounded-lg hover:bg-[var(--btn-plain-bg-hover)] transition-all group select-none",
|
||||
depth === 0
|
||||
? "p-4 bg-[var(--card-bg)] border border-[var(--line-divider)] mb-2"
|
||||
: "p-2",
|
||||
]}
|
||||
>
|
||||
<a href={node.url} class="flex items-center gap-2 flex-1 min-w-0">
|
||||
<Icon
|
||||
name={depth === 0
|
||||
? "material-symbols:folder-open-rounded"
|
||||
: "material-symbols:folder-outline-rounded"}
|
||||
class:list={[
|
||||
"text-[var(--primary)] shrink-0",
|
||||
depth === 0 ? "text-2xl" : "text-xl",
|
||||
]}
|
||||
/>
|
||||
<span
|
||||
class:list={[
|
||||
"truncate group-hover:text-[var(--primary)] transition-all",
|
||||
depth === 0 ? "font-bold text-lg text-90" : "font-medium text-75",
|
||||
]}>{node.name}</span
|
||||
>
|
||||
</a>
|
||||
<span
|
||||
class="text-sm text-50 bg-black/5 dark:bg-white/10 px-2 py-0.5 rounded shrink-0 ml-2"
|
||||
>
|
||||
{node.count}
|
||||
</span>
|
||||
</div>
|
||||
|
||||
{
|
||||
node.children && node.children.length > 0 && (
|
||||
<div
|
||||
class:list={[
|
||||
"flex flex-col gap-1",
|
||||
depth === 0
|
||||
? "mt-1 mb-3 ml-6 pl-4 border-l-2 border-[var(--line-divider)]"
|
||||
: "ml-4 pl-4 border-l-2 border-[var(--line-divider)]",
|
||||
]}
|
||||
>
|
||||
{node.children.map((child) => (
|
||||
<Astro.self node={child} depth={depth + 1} />
|
||||
))}
|
||||
</div>
|
||||
)
|
||||
}
|
||||
</div>
|
||||
7
src/components/ConfigCarrier.astro
Normal file
7
src/components/ConfigCarrier.astro
Normal file
@@ -0,0 +1,7 @@
|
||||
---
|
||||
|
||||
import { siteConfig } from "../config";
|
||||
---
|
||||
|
||||
<div id="config-carrier" data-hue={siteConfig.themeColor.hue}>
|
||||
</div>
|
||||
170
src/components/Footer.astro
Normal file
170
src/components/Footer.astro
Normal file
@@ -0,0 +1,170 @@
|
||||
---
|
||||
import { profileConfig } from "../config";
|
||||
import { url } from "../utils/url-utils";
|
||||
import { execSync } from "child_process";
|
||||
|
||||
const currentYear = new Date().getFullYear();
|
||||
|
||||
let commitHash = "unknown";
|
||||
let buildDate = "unknown";
|
||||
|
||||
try {
|
||||
commitHash = execSync("git rev-parse --short=7 HEAD").toString().trim();
|
||||
|
||||
const date = new Date();
|
||||
const year = date.getFullYear();
|
||||
const month = (date.getMonth() + 1).toString().padStart(2, "0");
|
||||
const day = date.getDate().toString().padStart(2, "0");
|
||||
const hours = date.getHours().toString().padStart(2, "0");
|
||||
const minutes = date.getMinutes().toString().padStart(2, "0");
|
||||
const seconds = date.getSeconds().toString().padStart(2, "0");
|
||||
buildDate = `${year}-${month}-${day} ${hours}:${minutes}:${seconds}`;
|
||||
} catch (e) {
|
||||
console.warn("Failed to get git info", e);
|
||||
}
|
||||
---
|
||||
|
||||
<!--<div class="border-t border-[var(--primary)] mx-16 border-dashed py-8 max-w-[var(--page-width)] flex flex-col items-center justify-center px-6">-->
|
||||
<div
|
||||
class="transition border-t border-black/10 dark:border-white/15 my-10 border-dashed mx-4 md:mx-32"
|
||||
>
|
||||
</div>
|
||||
<div class="card-base w-fit mx-auto rounded-xl mt-4 mb-4">
|
||||
<div class="transition text-50 text-sm text-center p-6">
|
||||
© <span id="copyright-year">2024 - {currentYear}</span>
|
||||
<a
|
||||
class="transition link text-[var(--primary)] font-medium"
|
||||
target="_blank"
|
||||
href="https://space.bilibili.com/325903362"
|
||||
>
|
||||
{profileConfig.name}
|
||||
</a>,采用
|
||||
<a
|
||||
class="transition link text-[var(--primary)] font-medium"
|
||||
target="_blank"
|
||||
href="https://creativecommons.org/licenses/by-nc-sa/4.0/"
|
||||
>CC BY-NC-SA 4.0</a
|
||||
> 许可
|
||||
<br />
|
||||
<a
|
||||
class="transition link text-[var(--primary)] font-medium"
|
||||
target="_blank"
|
||||
href={url("rss.xml")}>RSS</a
|
||||
> /
|
||||
<a
|
||||
class="transition link text-[var(--primary)] font-medium"
|
||||
target="_blank"
|
||||
href={url("sitemap-index.xml")}>网站地图</a
|
||||
>
|
||||
<br />
|
||||
由
|
||||
<a
|
||||
class="transition link text-[var(--primary)] font-medium"
|
||||
target="_blank"
|
||||
href="https://astro.build">Astro</a
|
||||
> 和
|
||||
<a
|
||||
class="transition link text-[var(--primary)] font-medium"
|
||||
target="_blank"
|
||||
href="https://github.com/saicaca/fuwari">Fuwari</a
|
||||
> 强力驱动
|
||||
<br />
|
||||
本网站代码
|
||||
<a
|
||||
class="transition link text-[var(--primary)] font-medium"
|
||||
target="_blank"
|
||||
href="https://github.com/afoim/fuwari">已开源</a
|
||||
>
|
||||
<a
|
||||
class="transition link text-black/30 dark:text-white/30 hover:text-[var(--primary)] text-xs ml-1"
|
||||
target="_blank"
|
||||
href={`https://github.com/afoim/fuwari/commit/${commitHash}`}
|
||||
>({commitHash} @ {buildDate})</a
|
||||
>
|
||||
<br />
|
||||
|
||||
<a
|
||||
class="transition link text-[var(--primary)] font-medium inline-flex items-center"
|
||||
href="https://beian.miit.gov.cn/#/Integrated/index"
|
||||
target="_blank"
|
||||
><img
|
||||
alt=""
|
||||
src="/favicon/foot-icp.png"
|
||||
class="h-4 mr-1"
|
||||
/>晋ICP备2025071728号-1</a
|
||||
>
|
||||
<br />
|
||||
<div class="server-info-wrapper flex items-center justify-center">
|
||||
<span class="server-info text-black/30 dark:text-white/30 text-xs"></span>
|
||||
<img
|
||||
class="server-icon h-5 ml-1 hidden bg-white rounded p-0.5"
|
||||
alt="Server Icon"
|
||||
/>
|
||||
</div>
|
||||
|
||||
<!-- <a class="transition link text-[var(--primary)] font-medium inline-flex items-center" href="https://beian.mps.gov.cn/#/query/webSearch?code=34010302002608" target="_blank"><img alt="" src="/favicon/foot-ga.png" class="h-4 mr-1">皖公网安备34010302002608号</a>
|
||||
<br> -->
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<script>
|
||||
function updateServerInfo(server) {
|
||||
const wrappers = document.querySelectorAll(".server-info-wrapper");
|
||||
wrappers.forEach((wrapper) => {
|
||||
const serverInfo = wrapper.querySelector(".server-info");
|
||||
const serverIcon = wrapper.querySelector(".server-icon");
|
||||
if (serverInfo) {
|
||||
if (server) {
|
||||
serverInfo.innerText = `访问节点:${server}`;
|
||||
if (serverIcon) {
|
||||
const serverLower = server.toLowerCase();
|
||||
if (serverLower === "edgeone-pages") {
|
||||
serverIcon.src = "/cdn/eo.png";
|
||||
serverIcon.classList.remove("hidden");
|
||||
serverInfo.classList.add("hidden");
|
||||
} else if (serverLower === "cloudflare") {
|
||||
serverIcon.src = "/cdn/cf.svg";
|
||||
serverIcon.classList.remove("hidden");
|
||||
serverInfo.classList.add("hidden");
|
||||
} else if (serverLower === "esa") {
|
||||
serverIcon.src = "/cdn/esa.svg";
|
||||
serverIcon.classList.remove("hidden");
|
||||
serverInfo.classList.add("hidden");
|
||||
} else {
|
||||
serverIcon.classList.add("hidden");
|
||||
serverInfo.classList.remove("hidden");
|
||||
}
|
||||
}
|
||||
} else {
|
||||
serverInfo.innerText = "访问节点:未知";
|
||||
serverInfo.classList.remove("hidden");
|
||||
if (serverIcon) serverIcon.classList.add("hidden");
|
||||
}
|
||||
}
|
||||
});
|
||||
}
|
||||
|
||||
function initServerInfo() {
|
||||
const isDevMode = localStorage.getItem("dev-mode") === "true";
|
||||
if (isDevMode) {
|
||||
const devServer = localStorage.getItem("dev-server");
|
||||
updateServerInfo(devServer);
|
||||
} else {
|
||||
const url = window.location.href;
|
||||
fetch(url, { method: "HEAD" })
|
||||
.then((response) => {
|
||||
const server = response.headers.get("server");
|
||||
updateServerInfo(server);
|
||||
})
|
||||
.catch((error) => {
|
||||
console.error("Failed to fetch server info:", error);
|
||||
updateServerInfo(null);
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
initServerInfo();
|
||||
document.addEventListener("astro:after-swap", initServerInfo); // Support View Transitions if enabled
|
||||
// Support Swup if enabled (listen to content replacement)
|
||||
document.addEventListener("content:replace", initServerInfo);
|
||||
</script>
|
||||
127
src/components/Navbar.astro
Normal file
127
src/components/Navbar.astro
Normal file
@@ -0,0 +1,127 @@
|
||||
---
|
||||
import { Icon } from "astro-icon/components";
|
||||
import { navBarConfig, siteConfig } from "../config";
|
||||
import { LinkPresets } from "../constants/link-presets";
|
||||
import { LinkPreset, type NavBarLink } from "../types/config";
|
||||
import { url } from "../utils/url-utils";
|
||||
|
||||
import Search from "./Search.svelte";
|
||||
import DisplaySettings from "./widget/DisplaySettings.svelte";
|
||||
import NavMenuPanel from "./widget/NavMenuPanel.astro";
|
||||
const className = Astro.props.class;
|
||||
|
||||
let links: NavBarLink[] = navBarConfig.links.map(
|
||||
(item: NavBarLink | LinkPreset): NavBarLink => {
|
||||
if (typeof item === "number") {
|
||||
return LinkPresets[item];
|
||||
}
|
||||
return item;
|
||||
}
|
||||
);
|
||||
---
|
||||
|
||||
<div id="navbar" class="z-50 onload-animation">
|
||||
<div
|
||||
class="absolute h-8 left-0 right-0 -top-8 bg-[var(--card-bg)] transition"
|
||||
>
|
||||
</div>
|
||||
<!-- used for onload animation -->
|
||||
<div
|
||||
class:list={[
|
||||
className,
|
||||
"card-base border border-black/10 dark:border-white/10 !overflow-visible max-w-[var(--page-width)] h-[4.5rem] !rounded-t-none mx-auto flex items-center justify-between px-4",
|
||||
]}
|
||||
>
|
||||
<a
|
||||
href={url("/")}
|
||||
class="btn-plain scale-animation rounded-lg h-[3.25rem] px-5 font-bold active:scale-95"
|
||||
>
|
||||
<div class="flex flex-row text-[var(--primary)] items-center text-md">
|
||||
<Icon
|
||||
name="material-symbols:home-outline-rounded"
|
||||
class="text-[1.75rem] mb-1 mr-2"
|
||||
/>
|
||||
{siteConfig.title}
|
||||
</div>
|
||||
</a>
|
||||
<div class="hidden md:flex">
|
||||
{
|
||||
links.map((l) => {
|
||||
return (
|
||||
<a
|
||||
aria-label={l.name}
|
||||
href={l.external ? l.url : url(l.url)}
|
||||
target={l.external ? "_blank" : null}
|
||||
class="btn-plain scale-animation rounded-lg h-11 font-bold px-5 active:scale-95"
|
||||
>
|
||||
<div class="flex items-center">
|
||||
{l.name}
|
||||
{l.external && (
|
||||
<Icon
|
||||
name="fa6-solid:arrow-up-right-from-square"
|
||||
class="text-[0.875rem] transition -translate-y-[1px] ml-1 text-black/[0.2] dark:text-white/[0.2]"
|
||||
/>
|
||||
)}
|
||||
</div>
|
||||
</a>
|
||||
);
|
||||
})
|
||||
}
|
||||
</div>
|
||||
<div class="flex">
|
||||
<!--<SearchPanel client:load>-->
|
||||
<Search client:only="svelte" />
|
||||
{
|
||||
!siteConfig.themeColor.fixed && (
|
||||
<button
|
||||
aria-label="Display Settings"
|
||||
class="btn-plain scale-animation rounded-lg h-11 w-11 active:scale-90"
|
||||
id="display-settings-switch"
|
||||
>
|
||||
<Icon
|
||||
name="material-symbols:palette-outline"
|
||||
class="text-[1.25rem]"
|
||||
/>
|
||||
</button>
|
||||
)
|
||||
}
|
||||
|
||||
<button
|
||||
aria-label="Menu"
|
||||
name="Nav Menu"
|
||||
class="btn-plain scale-animation rounded-lg w-11 h-11 active:scale-90 md:!hidden"
|
||||
id="nav-menu-switch"
|
||||
>
|
||||
<Icon name="material-symbols:menu-rounded" class="text-[1.25rem]" />
|
||||
</button>
|
||||
</div>
|
||||
<NavMenuPanel links={links} />
|
||||
<DisplaySettings client:only="svelte" />
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<script>
|
||||
function loadButtonScript() {
|
||||
let settingBtn = document.getElementById("display-settings-switch");
|
||||
if (settingBtn) {
|
||||
settingBtn.onclick = function () {
|
||||
let settingPanel = document.getElementById("display-setting");
|
||||
if (settingPanel) {
|
||||
settingPanel.classList.toggle("float-panel-closed");
|
||||
}
|
||||
};
|
||||
}
|
||||
|
||||
let menuBtn = document.getElementById("nav-menu-switch");
|
||||
if (menuBtn) {
|
||||
menuBtn.onclick = function () {
|
||||
let menuPanel = document.getElementById("nav-menu-panel");
|
||||
if (menuPanel) {
|
||||
menuPanel.classList.toggle("float-panel-closed");
|
||||
}
|
||||
};
|
||||
}
|
||||
}
|
||||
|
||||
loadButtonScript();
|
||||
</script>
|
||||
112
src/components/PostCard.astro
Normal file
112
src/components/PostCard.astro
Normal file
@@ -0,0 +1,112 @@
|
||||
---
|
||||
import path from "node:path";
|
||||
import type { CollectionEntry } from "astro:content";
|
||||
import { Icon } from "astro-icon/components";
|
||||
|
||||
import { getDir } from "../utils/url-utils";
|
||||
import { formatDateToYYYYMMDD } from "../utils/date-utils";
|
||||
import PostMetadata from "./PostMeta.astro";
|
||||
import ImageWrapper from "./misc/ImageWrapper.astro";
|
||||
import { umamiConfig } from "../config";
|
||||
|
||||
interface Props {
|
||||
class?: string;
|
||||
entry: CollectionEntry<"posts">;
|
||||
title: string;
|
||||
url: string;
|
||||
published: Date;
|
||||
updated?: Date;
|
||||
image: string;
|
||||
description: string;
|
||||
draft: boolean;
|
||||
style: string;
|
||||
category?: string | string[];
|
||||
}
|
||||
const {
|
||||
entry,
|
||||
title,
|
||||
url,
|
||||
published,
|
||||
updated,
|
||||
image,
|
||||
description,
|
||||
style,
|
||||
category,
|
||||
} = Astro.props;
|
||||
|
||||
const isPinned = entry.data.pinned === true;
|
||||
const className = Astro.props.class;
|
||||
|
||||
const hasCover = image !== undefined && image !== null && image !== "";
|
||||
|
||||
const coverWidth = "28%";
|
||||
|
||||
const { remarkPluginFrontmatter } = await entry.render();
|
||||
---
|
||||
<div class:list={["card-base border border-black/10 dark:border-white/10 flex flex-col w-full rounded-[var(--radius-large)] overflow-hidden relative", className]} style={style}>
|
||||
<div class:list={["pl-9 pr-2 pt-6 pb-6 relative", {"w-[calc(100%_-_52px_-_12px)]": !hasCover, "w-[calc(100%_-_var(--coverWidth)_-_12px)]": hasCover}]}>
|
||||
<a href={url}
|
||||
class="transition group w-full block font-bold mb-2 md:mb-3 text-xl md:text-3xl text-90 relative
|
||||
hover:text-[var(--primary)] dark:hover:text-[var(--primary)]
|
||||
active:text-[var(--title-active)] dark:active:text-[var(--title-active)]
|
||||
before:w-1 before:h-5 before:rounded-md before:bg-[var(--primary)]
|
||||
before:absolute before:top-1 md:before:top-2 before:-left-[1.125rem] before:block
|
||||
">
|
||||
|
||||
{title}
|
||||
<Icon class="text-[var(--primary)] text-[2rem] transition inline absolute translate-y-0.5 opacity-0 group-hover:opacity-100 -translate-x-1 group-hover:translate-x-0" name="material-symbols:chevron-right-rounded"></Icon>
|
||||
</a>
|
||||
|
||||
<!-- description -->
|
||||
<div class:list={["transition text-75 mb-3.5 pr-4 line-clamp-1 md:line-clamp-2"]}>
|
||||
{ description || remarkPluginFrontmatter.excerpt }
|
||||
</div>
|
||||
|
||||
<!-- metadata -->
|
||||
<PostMetadata published={published} updated={updated} hideUpdateDate={true} hidePublishedDate={true} slug={entry.slug} category={category} class="mb-2 md:mb-4"></PostMetadata>
|
||||
|
||||
<!-- word count, read time and page views -->
|
||||
<div class="text-sm text-black/30 dark:text-white/30 flex gap-4 transition">
|
||||
<div>{formatDateToYYYYMMDD(published)}</div>
|
||||
<div>|</div>
|
||||
<div>{remarkPluginFrontmatter.words} 字</div>
|
||||
<div>|</div>
|
||||
<div>{remarkPluginFrontmatter.minutes} 分钟</div>
|
||||
</div>
|
||||
|
||||
</div>
|
||||
|
||||
{hasCover && <a href={url} aria-label={title}
|
||||
class:list={["group",
|
||||
"max-h-none mx-0 mt-0",
|
||||
"w-[var(--coverWidth)] absolute top-3 bottom-3 right-3 rounded-xl overflow-hidden active:scale-95"
|
||||
]} >
|
||||
<div class="absolute pointer-events-none z-10 w-full h-full group-hover:bg-black/30 group-active:bg-black/50 transition"></div>
|
||||
<!-- 封面图上的箭头 -->
|
||||
<div class="absolute pointer-events-none z-20 w-full h-full flex items-center justify-center ">
|
||||
<Icon name="material-symbols:chevron-right-rounded"
|
||||
class="transition opacity-0 group-hover:opacity-100 scale-50 group-hover:scale-100 text-white text-5xl">
|
||||
</Icon>
|
||||
</div>
|
||||
<ImageWrapper src={image} basePath={path.join("content/posts/", getDir(entry.id))} alt="Cover Image of the Post"
|
||||
class="w-full h-full">
|
||||
</ImageWrapper>
|
||||
</a>}
|
||||
|
||||
{!hasCover &&
|
||||
<a href={url} aria-label={title} class="!flex btn-regular w-[3.25rem]
|
||||
absolute right-3 top-3 bottom-3 rounded-xl bg-[var(--enter-btn-bg)]
|
||||
hover:bg-[var(--enter-btn-bg-hover)] active:bg-[var(--enter-btn-bg-active)] active:scale-95
|
||||
">
|
||||
<Icon name="material-symbols:chevron-right-rounded"
|
||||
class="transition text-[var(--primary)] text-4xl mx-auto">
|
||||
</Icon>
|
||||
</a>
|
||||
}
|
||||
</div>
|
||||
<div class="transition border-t-[1px] border-dashed mx-6 border-black/10 dark:border-white/[0.15] last:border-t-0 hidden"></div>
|
||||
|
||||
|
||||
|
||||
<style define:vars={{coverWidth}}>
|
||||
</style>
|
||||
136
src/components/PostMeta.astro
Normal file
136
src/components/PostMeta.astro
Normal file
@@ -0,0 +1,136 @@
|
||||
---
|
||||
import { Icon } from "astro-icon/components";
|
||||
|
||||
import { getDir, url } from "../utils/url-utils";
|
||||
import { formatDateToYYYYMMDD } from "../utils/date-utils";
|
||||
import { umamiConfig } from "../config";
|
||||
import { getPostCategories, getCategoryUrl, parseCategoryPath } from "../utils/category-utils";
|
||||
|
||||
interface Props {
|
||||
class: string;
|
||||
published: Date;
|
||||
updated?: Date;
|
||||
hideUpdateDate?: boolean;
|
||||
hidePublishedDate?: boolean;
|
||||
slug?: string;
|
||||
category?: string | string[];
|
||||
}
|
||||
const {
|
||||
published,
|
||||
updated,
|
||||
hideUpdateDate = false,
|
||||
hidePublishedDate = false,
|
||||
slug,
|
||||
category,
|
||||
} = Astro.props;
|
||||
const className = Astro.props.class;
|
||||
|
||||
// Process category data
|
||||
const categories = typeof category === "string"
|
||||
? [category]
|
||||
: category || [];
|
||||
---
|
||||
|
||||
<div class:list={["flex flex-wrap text-neutral-500 dark:text-neutral-400 items-center gap-4 gap-x-4 gap-y-2", className]}>
|
||||
<!-- publish date -->
|
||||
{!hidePublishedDate && (
|
||||
<div class="flex items-center">
|
||||
<div class="meta-icon">
|
||||
<Icon name="material-symbols:calendar-today-outline-rounded" class="text-xl"></Icon>
|
||||
</div>
|
||||
<span class="text-50 text-sm font-medium">{formatDateToYYYYMMDD(published)}</span>
|
||||
</div>
|
||||
)}
|
||||
|
||||
<!-- update date -->
|
||||
{!hideUpdateDate && updated && updated.getTime() !== published.getTime() && (
|
||||
<div class="flex items-center">
|
||||
<div class="meta-icon"
|
||||
>
|
||||
<Icon name="material-symbols:edit-calendar-outline-rounded" class="text-xl"></Icon>
|
||||
</div>
|
||||
<span class="text-50 text-sm font-medium">{formatDateToYYYYMMDD(updated)}</span>
|
||||
</div>
|
||||
)}
|
||||
|
||||
<!-- page views & visitors -->
|
||||
{slug && (
|
||||
<>
|
||||
<div class="flex items-center">
|
||||
<div class="meta-icon">
|
||||
<Icon name="material-symbols:visibility-outline-rounded" class="text-xl"></Icon>
|
||||
</div>
|
||||
<span class="text-50 text-sm font-medium" id={`page-views-${slug}`}>-</span>
|
||||
</div>
|
||||
<div class="flex items-center">
|
||||
<div class="meta-icon">
|
||||
<Icon name="material-symbols:person" class="text-xl"></Icon>
|
||||
</div>
|
||||
<span class="text-50 text-sm font-medium" id={`page-visitors-${slug}`}>-</span>
|
||||
</div>
|
||||
</>
|
||||
)}
|
||||
|
||||
<!-- categories -->
|
||||
{categories.length > 0 && (
|
||||
<div class="flex items-center flex-wrap gap-2">
|
||||
<div class="meta-icon">
|
||||
<Icon name="material-symbols:folder-outline-rounded" class="text-xl"></Icon>
|
||||
</div>
|
||||
{categories.map((cat, index) => {
|
||||
const catPath = parseCategoryPath(cat);
|
||||
const catUrl = getCategoryUrl(catPath);
|
||||
const catName = catPath[catPath.length - 1]; // Show last level only
|
||||
|
||||
return (
|
||||
<>
|
||||
{index > 0 && <span class="text-30">,</span>}
|
||||
<a
|
||||
href={catUrl}
|
||||
class="text-50 text-sm font-medium hover:text-[var(--primary)] transition"
|
||||
>
|
||||
{catName}
|
||||
</a>
|
||||
</>
|
||||
);
|
||||
})}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
|
||||
{slug && (
|
||||
<script define:vars={{ slug, umamiConfig }}>
|
||||
|
||||
// 获取访问量统计
|
||||
async function fetchPageViews() {
|
||||
if (!umamiConfig.enable) return;
|
||||
try {
|
||||
const statsData = await fetchUmamiStats(umamiConfig.baseUrl, umamiConfig.shareId, {
|
||||
timezone: umamiConfig.timezone,
|
||||
path: `eq./posts/${slug}/`
|
||||
});
|
||||
|
||||
const pageViews = statsData.pageviews || 0;
|
||||
const visits = statsData.visitors || 0;
|
||||
|
||||
const viewsElement = document.getElementById(`page-views-${slug}`);
|
||||
const visitorsElement = document.getElementById(`page-visitors-${slug}`);
|
||||
if (viewsElement) viewsElement.textContent = `${pageViews} 次`;
|
||||
if (visitorsElement) visitorsElement.textContent = `${visits} 人`;
|
||||
} catch (error) {
|
||||
console.error('Error fetching page views:', error);
|
||||
const viewsElement = document.getElementById(`page-views-${slug}`);
|
||||
const visitorsElement = document.getElementById(`page-visitors-${slug}`);
|
||||
if (viewsElement) viewsElement.textContent = '-';
|
||||
if (visitorsElement) visitorsElement.textContent = '-';
|
||||
}
|
||||
}
|
||||
|
||||
// 页面加载完成后获取统计数据
|
||||
if (document.readyState === 'loading') {
|
||||
document.addEventListener('DOMContentLoaded', fetchPageViews);
|
||||
} else {
|
||||
fetchPageViews();
|
||||
}
|
||||
</script>
|
||||
)}
|
||||
29
src/components/PostPage.astro
Normal file
29
src/components/PostPage.astro
Normal file
@@ -0,0 +1,29 @@
|
||||
---
|
||||
import type { CollectionEntry } from "astro:content";
|
||||
import { getPostUrlBySlug } from "@utils/url-utils";
|
||||
import PostCard from "./PostCard.astro";
|
||||
|
||||
const { page } = Astro.props;
|
||||
|
||||
let delay = 0;
|
||||
const interval = 50;
|
||||
---
|
||||
|
||||
<div class="transition flex flex-col rounded-[var(--radius-large)] bg-transparent gap-4 mb-4">
|
||||
|
||||
{page.data.map((entry: CollectionEntry<"posts">) => (
|
||||
<PostCard
|
||||
entry={entry}
|
||||
title={entry.data.title}
|
||||
published={entry.data.published}
|
||||
updated={entry.data.updated}
|
||||
url={getPostUrlBySlug(entry.slug)}
|
||||
image={entry.data.image}
|
||||
description={entry.data.description}
|
||||
draft={entry.data.draft}
|
||||
category={entry.data.category}
|
||||
class:list="onload-animation"
|
||||
style={`animation-delay: calc(var(--content-delay) + ${delay++ * interval}ms);`}
|
||||
></PostCard>
|
||||
))}
|
||||
</div>
|
||||
206
src/components/Search.svelte
Normal file
206
src/components/Search.svelte
Normal file
@@ -0,0 +1,206 @@
|
||||
<script lang="ts">
|
||||
|
||||
import Icon from "@iconify/svelte";
|
||||
import { url } from "@utils/url-utils.ts";
|
||||
import { onMount } from "svelte";
|
||||
|
||||
interface SearchResult {
|
||||
url: string;
|
||||
meta: {
|
||||
title: string;
|
||||
};
|
||||
excerpt: string;
|
||||
urlPath?: string;
|
||||
}
|
||||
|
||||
let keywordDesktop = "";
|
||||
let keywordMobile = "";
|
||||
let result: SearchResult[] = [];
|
||||
let isSearching = false;
|
||||
let posts: any[] = [];
|
||||
|
||||
const togglePanel = () => {
|
||||
const panel = document.getElementById("search-panel");
|
||||
panel?.classList.toggle("float-panel-closed");
|
||||
};
|
||||
|
||||
const setPanelVisibility = (show: boolean, isDesktop: boolean): void => {
|
||||
const panel = document.getElementById("search-panel");
|
||||
if (!panel || !isDesktop) return;
|
||||
|
||||
if (show) {
|
||||
panel.classList.remove("float-panel-closed");
|
||||
} else {
|
||||
panel.classList.add("float-panel-closed");
|
||||
}
|
||||
};
|
||||
|
||||
const highlightText = (text: string, keyword: string): string => {
|
||||
if (!keyword) return text;
|
||||
const regex = new RegExp(`(${keyword})`, "gi");
|
||||
return text.replace(regex, "<mark>$1</mark>");
|
||||
};
|
||||
|
||||
const search = async (keyword: string, isDesktop: boolean): Promise<void> => {
|
||||
if (!keyword) {
|
||||
setPanelVisibility(false, isDesktop);
|
||||
result = [];
|
||||
return;
|
||||
}
|
||||
|
||||
isSearching = true;
|
||||
|
||||
try {
|
||||
const searchResults = posts
|
||||
.filter((post) => {
|
||||
const keywordLower = keyword.toLowerCase();
|
||||
const searchText =
|
||||
`${post.title} ${post.description} ${post.content}`.toLowerCase();
|
||||
const urlPath = `/posts/${post.link}`;
|
||||
|
||||
// 支持内容搜索和URL后缀搜索
|
||||
return searchText.includes(keywordLower) ||
|
||||
urlPath.toLowerCase().includes(keywordLower) ||
|
||||
post.link.toLowerCase().includes(keywordLower);
|
||||
})
|
||||
.map((post) => {
|
||||
const contentLower = post.content.toLowerCase();
|
||||
const keywordLower = keyword.toLowerCase();
|
||||
const contentIndex = contentLower.indexOf(keywordLower);
|
||||
|
||||
let excerpt = '';
|
||||
if (contentIndex !== -1) {
|
||||
const start = Math.max(0, contentIndex - 50);
|
||||
const end = Math.min(post.content.length, contentIndex + 100);
|
||||
excerpt = post.content.substring(start, end);
|
||||
if (start > 0) excerpt = '...' + excerpt;
|
||||
if (end < post.content.length) excerpt = excerpt + '...';
|
||||
} else {
|
||||
excerpt = post.description || post.content.substring(0, 150) + '...';
|
||||
}
|
||||
|
||||
return {
|
||||
url: url(`/posts/${post.link}/`),
|
||||
meta: {
|
||||
title: post.title
|
||||
},
|
||||
excerpt: highlightText(excerpt, keyword),
|
||||
urlPath: `/posts/${post.link}`
|
||||
};
|
||||
});
|
||||
|
||||
result = searchResults;
|
||||
setPanelVisibility(result.length > 0, isDesktop);
|
||||
} catch (error) {
|
||||
console.error("Search error:", error);
|
||||
result = [];
|
||||
setPanelVisibility(false, isDesktop);
|
||||
} finally {
|
||||
isSearching = false;
|
||||
}
|
||||
};
|
||||
|
||||
onMount(async () => {
|
||||
try {
|
||||
const response = await fetch("/rss.xml");
|
||||
const text = await response.text();
|
||||
const parser = new DOMParser();
|
||||
const xml = parser.parseFromString(text, "text/xml");
|
||||
const items = xml.querySelectorAll("item");
|
||||
|
||||
posts = Array.from(items).map((item) => {
|
||||
// 尝试多种方式获取content:encoded内容
|
||||
let content = "";
|
||||
const contentEncoded =
|
||||
item.getElementsByTagNameNS("*", "encoded")[0]?.textContent ||
|
||||
item.querySelector("*|encoded")?.textContent ||
|
||||
"";
|
||||
|
||||
if (contentEncoded) {
|
||||
content = contentEncoded.replace(/<[^>]*>/g, "");
|
||||
}
|
||||
|
||||
return {
|
||||
title: item.querySelector("title")?.textContent || "",
|
||||
description: item.querySelector("description")?.textContent || "",
|
||||
content: content,
|
||||
link: item.querySelector("link")?.textContent?.replace(/.*\/posts\/(.*?)\//, "$1") || "",
|
||||
};
|
||||
});
|
||||
} catch (error) {
|
||||
console.error("Error fetching RSS:", error);
|
||||
}
|
||||
});
|
||||
|
||||
$: search(keywordDesktop, true);
|
||||
$: search(keywordMobile, false);
|
||||
</script>
|
||||
|
||||
<!-- search bar for desktop view -->
|
||||
<div id="search-bar" class="hidden lg:flex transition-all items-center h-11 mr-2 rounded-lg
|
||||
bg-black/[0.04] hover:bg-black/[0.06] focus-within:bg-black/[0.06]
|
||||
dark:bg-white/5 dark:hover:bg-white/10 dark:focus-within:bg-white/10
|
||||
">
|
||||
<Icon icon="material-symbols:search" class="absolute text-[1.25rem] pointer-events-none ml-3 transition my-auto text-black/30 dark:text-white/30"></Icon>
|
||||
<input placeholder="搜索" bind:value={keywordDesktop} on:focus={() => search(keywordDesktop, true)}
|
||||
class="transition-all pl-10 text-sm bg-transparent outline-0
|
||||
h-full w-40 active:w-60 focus:w-60 text-black/50 dark:text-white/50"
|
||||
>
|
||||
</div>
|
||||
|
||||
<!-- toggle btn for phone/tablet view -->
|
||||
<button on:click={togglePanel} aria-label="Search Panel" id="search-switch"
|
||||
class="btn-plain scale-animation lg:!hidden rounded-lg w-11 h-11 active:scale-90">
|
||||
<Icon icon="material-symbols:search" class="text-[1.25rem]"></Icon>
|
||||
</button>
|
||||
|
||||
<!-- search panel -->
|
||||
<div id="search-panel" class="float-panel float-panel-closed search-panel absolute md:w-[30rem]
|
||||
top-20 left-4 md:left-[unset] right-4 shadow-2xl rounded-2xl p-2">
|
||||
|
||||
<!-- search bar inside panel for phone/tablet -->
|
||||
<div id="search-bar-inside" class="flex relative lg:hidden transition-all items-center h-11 rounded-xl
|
||||
bg-black/[0.04] hover:bg-black/[0.06] focus-within:bg-black/[0.06]
|
||||
dark:bg-white/5 dark:hover:bg-white/10 dark:focus-within:bg-white/10
|
||||
">
|
||||
<Icon icon="material-symbols:search" class="absolute text-[1.25rem] pointer-events-none ml-3 transition my-auto text-black/30 dark:text-white/30"></Icon>
|
||||
<input placeholder="Search" bind:value={keywordMobile}
|
||||
class="pl-10 absolute inset-0 text-sm bg-transparent outline-0
|
||||
focus:w-60 text-black/50 dark:text-white/50"
|
||||
>
|
||||
</div>
|
||||
|
||||
<!-- search results -->
|
||||
{#each result as item}
|
||||
<a href={item.url}
|
||||
class="transition first-of-type:mt-2 lg:first-of-type:mt-0 group block
|
||||
rounded-xl text-lg px-3 py-2 hover:bg-[var(--btn-plain-bg-hover)] active:bg-[var(--btn-plain-bg-active)]">
|
||||
<div class="transition text-90 inline-flex font-bold group-hover:text-[var(--primary)]">
|
||||
{item.meta.title}<Icon icon="fa6-solid:chevron-right" class="transition text-[0.75rem] translate-x-1 my-auto text-[var(--primary)]"></Icon>
|
||||
</div>
|
||||
<div class="transition text-xs text-white mb-1 font-mono">
|
||||
{item.urlPath}
|
||||
</div>
|
||||
<div class="transition text-sm text-50">
|
||||
{@html item.excerpt}
|
||||
</div>
|
||||
</a>
|
||||
{/each}
|
||||
</div>
|
||||
|
||||
<style>
|
||||
input:focus {
|
||||
outline: 0;
|
||||
}
|
||||
.search-panel {
|
||||
background-color: var(--float-panel-bg-opaque);
|
||||
max-height: calc(100vh - 100px);
|
||||
overflow-y: auto;
|
||||
scrollbar-width: none; /* Firefox */
|
||||
-ms-overflow-style: none; /* IE and Edge */
|
||||
}
|
||||
|
||||
.search-panel::-webkit-scrollbar {
|
||||
display: none; /* Chrome, Safari and Opera */
|
||||
}
|
||||
</style>
|
||||
49
src/components/control/BackToTop.astro
Normal file
49
src/components/control/BackToTop.astro
Normal file
@@ -0,0 +1,49 @@
|
||||
---
|
||||
import { Icon } from "astro-icon/components";
|
||||
---
|
||||
|
||||
<!-- There can't be a filter on parent element, or it will break `fixed` -->
|
||||
<div class="back-to-top-wrapper hidden lg:block">
|
||||
<div id="back-to-top-btn" class="back-to-top-btn hide flex items-center rounded-2xl overflow-hidden transition" onclick="backToTop()">
|
||||
<button aria-label="Back to Top" class="btn-card h-[3.75rem] w-[3.75rem]">
|
||||
<Icon name="material-symbols:keyboard-arrow-up-rounded" class="mx-auto"></Icon>
|
||||
</button>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<style lang="stylus">
|
||||
.back-to-top-wrapper
|
||||
width: 3.75rem
|
||||
height: 3.75rem
|
||||
position: absolute
|
||||
right: 0
|
||||
top: 0
|
||||
pointer-events: none
|
||||
|
||||
.back-to-top-btn
|
||||
color: var(--primary)
|
||||
font-size: 2.25rem
|
||||
font-weight: bold
|
||||
border: none
|
||||
position: fixed
|
||||
bottom: 10rem
|
||||
opacity: 1
|
||||
cursor: pointer
|
||||
transform: translateX(5rem)
|
||||
pointer-events: auto
|
||||
i
|
||||
font-size: 1.75rem
|
||||
&.hide
|
||||
transform: translateX(5rem) scale(0.9)
|
||||
opacity: 0
|
||||
pointer-events: none
|
||||
&:active
|
||||
transform: translateX(5rem) scale(0.9)
|
||||
|
||||
</style>
|
||||
|
||||
<script is:raw is:inline>
|
||||
function backToTop() {
|
||||
window.scroll({ top: 0, behavior: 'smooth' });
|
||||
}
|
||||
</script>
|
||||
83
src/components/control/Pagination.astro
Normal file
83
src/components/control/Pagination.astro
Normal file
@@ -0,0 +1,83 @@
|
||||
---
|
||||
import type { Page } from "astro";
|
||||
import { Icon } from "astro-icon/components";
|
||||
import { url } from "../../utils/url-utils";
|
||||
interface Props {
|
||||
page: Page;
|
||||
class?: string;
|
||||
style?: string;
|
||||
}
|
||||
|
||||
const { page, style } = Astro.props;
|
||||
|
||||
const HIDDEN = -1;
|
||||
|
||||
const className = Astro.props.class;
|
||||
|
||||
const ADJ_DIST = 2;
|
||||
const VISIBLE = ADJ_DIST * 2 + 1;
|
||||
|
||||
// for test
|
||||
let count = 1;
|
||||
let l = page.currentPage;
|
||||
let r = page.currentPage;
|
||||
while (0 < l - 1 && r + 1 <= page.lastPage && count + 2 <= VISIBLE) {
|
||||
count += 2;
|
||||
l--;
|
||||
r++;
|
||||
}
|
||||
while (0 < l - 1 && count < VISIBLE) {
|
||||
count++;
|
||||
l--;
|
||||
}
|
||||
while (r + 1 <= page.lastPage && count < VISIBLE) {
|
||||
count++;
|
||||
r++;
|
||||
}
|
||||
|
||||
let pages: number[] = [];
|
||||
if (l > 1) pages.push(1);
|
||||
if (l === 3) pages.push(2);
|
||||
if (l > 3) pages.push(HIDDEN);
|
||||
for (let i = l; i <= r; i++) pages.push(i);
|
||||
if (r < page.lastPage - 2) pages.push(HIDDEN);
|
||||
if (r === page.lastPage - 2) pages.push(page.lastPage - 1);
|
||||
if (r < page.lastPage) pages.push(page.lastPage);
|
||||
|
||||
const getPageUrl = (p: number) => {
|
||||
if (p === 1) return "/";
|
||||
return `/${p}/`;
|
||||
};
|
||||
---
|
||||
|
||||
<div class:list={[className, "flex flex-row gap-3 justify-center"]} style={style}>
|
||||
<a href={page.url.prev || ""} aria-label={page.url.prev ? "Previous Page" : null}
|
||||
class:list={["btn-card overflow-hidden rounded-lg text-[var(--primary)] w-11 h-11",
|
||||
{"disabled": page.url.prev == undefined}
|
||||
]}
|
||||
>
|
||||
<Icon name="material-symbols:chevron-left-rounded" class="text-[1.75rem]"></Icon>
|
||||
</a>
|
||||
<div class="bg-[var(--card-bg)] flex flex-row rounded-lg items-center text-neutral-700 dark:text-neutral-300 font-bold" style="backdrop-filter: blur(12px); -webkit-backdrop-filter: blur(12px);">
|
||||
{pages.map((p) => {
|
||||
if (p == HIDDEN)
|
||||
return <Icon name="material-symbols:more-horiz" class="mx-1"/>;
|
||||
if (p == page.currentPage)
|
||||
return <div class="h-11 w-11 rounded-lg bg-[var(--primary)] flex items-center justify-center
|
||||
font-bold text-white dark:text-black/70"
|
||||
>
|
||||
{p}
|
||||
</div>
|
||||
return <a href={url(getPageUrl(p))} aria-label=`Page ${p}`
|
||||
class="transition flex items-center justify-center w-11 h-11 rounded-lg overflow-hidden active:scale-[0.85] hover:bg-[var(--btn-card-bg-hover)] active:bg-[var(--btn-card-bg-active)] text-black/75 dark:text-white/75"
|
||||
>{p}</a>
|
||||
})}
|
||||
</div>
|
||||
<a href={page.url.next || ""} aria-label={page.url.next ? "Next Page" : null}
|
||||
class:list={["btn-card overflow-hidden rounded-lg text-[var(--primary)] w-11 h-11",
|
||||
{"disabled": page.url.next == undefined}
|
||||
]}
|
||||
>
|
||||
<Icon name="material-symbols:chevron-right-rounded" class="text-[1.75rem]"></Icon>
|
||||
</a>
|
||||
</div>
|
||||
90
src/components/misc/ImageWrapper.astro
Normal file
90
src/components/misc/ImageWrapper.astro
Normal file
@@ -0,0 +1,90 @@
|
||||
---
|
||||
import path from "node:path";
|
||||
interface Props {
|
||||
id?: string;
|
||||
src: string;
|
||||
class?: string;
|
||||
alt?: string;
|
||||
position?: string;
|
||||
basePath?: string;
|
||||
}
|
||||
import { Image } from "astro:assets";
|
||||
import { url } from "../../utils/url-utils";
|
||||
import { imageFallbackConfig, siteConfig } from "../../config";
|
||||
|
||||
const { id, src, alt, position = "center", basePath = "/" } = Astro.props;
|
||||
const className = Astro.props.class;
|
||||
|
||||
const isLocal = !(
|
||||
src.startsWith("/") ||
|
||||
src.startsWith("http") ||
|
||||
src.startsWith("https") ||
|
||||
src.startsWith("data:")
|
||||
);
|
||||
const isPublic = src.startsWith("/");
|
||||
|
||||
// TODO temporary workaround for images dynamic import
|
||||
// https://github.com/withastro/astro/issues/3373
|
||||
// biome-ignore lint/suspicious/noImplicitAnyLet: <explanation>
|
||||
let img;
|
||||
if (isLocal) {
|
||||
const files = import.meta.glob<ImageMetadata>("../../**", {
|
||||
import: "default",
|
||||
});
|
||||
let normalizedPath = path
|
||||
.normalize(path.join("../../", basePath, src))
|
||||
.replace(/\\/g, "/");
|
||||
const file = files[normalizedPath];
|
||||
if (!file) {
|
||||
console.error(
|
||||
`\n[ERROR] Image file not found: ${normalizedPath.replace("../../", "src/")}`,
|
||||
);
|
||||
}
|
||||
img = await file();
|
||||
}
|
||||
|
||||
const imageClass = "w-full h-full object-cover";
|
||||
const imageStyle = `object-position: ${position}`;
|
||||
---
|
||||
<div id={id} class:list={[className, 'overflow-hidden relative image-wrapper']} style={`--theme-hue: ${siteConfig.themeColor.hue}`}>
|
||||
<!-- 加载条 -->
|
||||
<div class="loading-bar absolute top-1/2 left-1/2 transform -translate-x-1/2 -translate-y-1/2 w-32 h-1 bg-gray-200 dark:bg-gray-700 z-10 rounded-full overflow-hidden">
|
||||
<div class="loading-progress h-full w-8 bg-[oklch(0.70_0.14_var(--theme-hue))] animate-loading-progress rounded-full"></div>
|
||||
</div>
|
||||
|
||||
<!-- 图片内容 -->
|
||||
{isLocal && img && <Image src={img} alt={alt || ""} class={`${imageClass} image-content opacity-0 transition-opacity duration-500`} style={imageStyle} onload="this.style.opacity='1'; this.parentElement.querySelector('.loading-bar').style.opacity='0';"/>}
|
||||
{!isLocal && (
|
||||
imageFallbackConfig.enable && src.includes(imageFallbackConfig.originalDomain) ?
|
||||
<img src={isPublic ? url(src) : src} alt={alt || ""} class={`${imageClass} image-content opacity-0 transition-opacity duration-500`} style={imageStyle} onload="this.style.opacity='1'; this.parentElement.querySelector('.loading-bar').style.opacity='0';" onerror={`this.onerror=null; this.src='${(isPublic ? url(src) : src).replace(imageFallbackConfig.originalDomain, imageFallbackConfig.fallbackDomain)}';`}/> :
|
||||
<img src={isPublic ? url(src) : src} alt={alt || ""} class={`${imageClass} image-content opacity-0 transition-opacity duration-500`} style={imageStyle} onload="this.style.opacity='1'; this.parentElement.querySelector('.loading-bar').style.opacity='0';"/>
|
||||
)}
|
||||
</div>
|
||||
|
||||
<style>
|
||||
.loading-bar {
|
||||
transition: opacity 0.5s ease-out;
|
||||
}
|
||||
|
||||
@keyframes loading-progress {
|
||||
0% {
|
||||
transform: translateX(-100%);
|
||||
}
|
||||
100% {
|
||||
transform: translateX(400%);
|
||||
}
|
||||
}
|
||||
|
||||
.animate-loading-progress {
|
||||
animation: loading-progress 1.5s ease-in-out infinite;
|
||||
}
|
||||
|
||||
.image-content {
|
||||
transition: transform 0.3s ease-out, opacity 0.5s ease-out;
|
||||
}
|
||||
|
||||
.image-wrapper:hover .image-content {
|
||||
transform: scale(1.05);
|
||||
}
|
||||
</style>
|
||||
|
||||
60
src/components/misc/License.astro
Normal file
60
src/components/misc/License.astro
Normal file
@@ -0,0 +1,60 @@
|
||||
---
|
||||
import { Icon } from "astro-icon/components";
|
||||
import { licenseConfig, profileConfig } from "../../config";
|
||||
|
||||
import { formatDateToYYYYMMDD } from "../../utils/date-utils";
|
||||
|
||||
interface Props {
|
||||
title: string;
|
||||
slug: string;
|
||||
pubDate: Date;
|
||||
class: string;
|
||||
}
|
||||
|
||||
const { title, pubDate } = Astro.props;
|
||||
const className = Astro.props.class;
|
||||
const profileConf = profileConfig;
|
||||
const licenseConf = licenseConfig;
|
||||
const postUrl = decodeURIComponent(Astro.url.toString());
|
||||
---
|
||||
<div class=`relative transition overflow-hidden bg-[var(--license-block-bg)] py-5 px-6 ${className}`>
|
||||
<div class="transition font-bold text-black/75 dark:text-white/75">
|
||||
{title}
|
||||
</div>
|
||||
|
||||
<a id="current-link" style="display:none;" class="link text-[var(--primary)]"></a>
|
||||
|
||||
<script>
|
||||
const currentLink = document.getElementById('current-link');
|
||||
|
||||
if (currentLink) {
|
||||
console.log(`[license] old url: ${window.location.href}`);
|
||||
const url = new URL(window.location.href);
|
||||
url.search = '';
|
||||
const address = url.toString();
|
||||
console.log(`[license] new url: ${address}`);
|
||||
|
||||
currentLink.textContent = address; // 显示文本 = 当前 URL
|
||||
currentLink.href = address; // 点击跳转 = 当前 URL
|
||||
currentLink.style.display = 'inline'; // 显示出来
|
||||
}
|
||||
</script>
|
||||
|
||||
<div class="flex gap-6 mt-2">
|
||||
<div>
|
||||
<div class="transition text-black/30 dark:text-white/30 text-sm">作者</div>
|
||||
<div class="transition text-black/75 dark:text-white/75 line-clamp-2">{profileConf.name}</div>
|
||||
</div>
|
||||
<div>
|
||||
<div class="transition text-black/30 dark:text-white/30 text-sm">发布于</div>
|
||||
<div class="transition text-black/75 dark:text-white/75 line-clamp-2">{formatDateToYYYYMMDD(pubDate)}</div>
|
||||
</div>
|
||||
<div>
|
||||
<div class="transition text-black/30 dark:text-white/30 text-sm">许可协议</div>
|
||||
<a href={licenseConf.url} target="_blank" class="link text-[var(--primary)] line-clamp-2">{licenseConf.name}</a>
|
||||
</div>
|
||||
</div>
|
||||
<Icon name="fa6-brands:creative-commons" class="transition text-[15rem] absolute pointer-events-none right-6 top-1/2 -translate-y-1/2 text-black/5 dark:text-white/5"></Icon>
|
||||
</div>
|
||||
|
||||
|
||||
42
src/components/misc/Markdown.astro
Normal file
42
src/components/misc/Markdown.astro
Normal file
@@ -0,0 +1,42 @@
|
||||
---
|
||||
import "@fontsource-variable/jetbrains-mono";
|
||||
import "@fontsource-variable/jetbrains-mono/wght-italic.css";
|
||||
|
||||
interface Props {
|
||||
class: string;
|
||||
}
|
||||
const className = Astro.props.class;
|
||||
---
|
||||
<div data-pagefind-body class=`prose dark:prose-invert prose-base !max-w-none custom-md ${className}`>
|
||||
<!--<div class="prose dark:prose-invert max-w-none custom-md">-->
|
||||
<!--<div class="max-w-none custom-md">-->
|
||||
<slot/>
|
||||
</div>
|
||||
|
||||
<script>
|
||||
document.addEventListener("click", function (e: MouseEvent) {
|
||||
const target = e.target as Element | null;
|
||||
if (target && target.classList.contains("copy-btn")) {
|
||||
const preEle = target.closest("pre");
|
||||
const codeEle = preEle?.querySelector("code");
|
||||
const code = Array.from(codeEle?.querySelectorAll(".code:not(summary *)") ?? [])
|
||||
.map(el => el.textContent)
|
||||
.map(t => t === "\n" ? "" : t)
|
||||
.join("\n");
|
||||
navigator.clipboard.writeText(code);
|
||||
|
||||
const timeoutId = target.getAttribute("data-timeout-id");
|
||||
if (timeoutId) {
|
||||
clearTimeout(parseInt(timeoutId));
|
||||
}
|
||||
|
||||
target.classList.add("success");
|
||||
|
||||
// 设置新的timeout并保存ID到按钮的自定义属性中
|
||||
const newTimeoutId = setTimeout(() => {
|
||||
target.classList.remove("success");
|
||||
}, 1000);
|
||||
target.setAttribute("data-timeout-id", newTimeoutId.toString());
|
||||
}
|
||||
});
|
||||
</script>
|
||||
61
src/components/widget/CategoryDrawer.astro
Normal file
61
src/components/widget/CategoryDrawer.astro
Normal file
@@ -0,0 +1,61 @@
|
||||
---
|
||||
import type { CategoryNode } from "@/types/config";
|
||||
import { Icon } from "astro-icon/components";
|
||||
|
||||
interface Props {
|
||||
category: CategoryNode;
|
||||
depth?: number;
|
||||
}
|
||||
|
||||
const { category, depth = 0 } = Astro.props;
|
||||
const hasChildren = category.children && category.children.length > 0;
|
||||
---
|
||||
|
||||
<div class="category-drawer relative">
|
||||
<div
|
||||
class="flex items-center justify-between px-3 py-2 rounded hover:bg-[var(--btn-plain-bg-hover)] transition-all group w-full"
|
||||
>
|
||||
<div class="flex items-center gap-2 overflow-hidden w-full">
|
||||
{
|
||||
hasChildren ? (
|
||||
<button
|
||||
class="drawer-toggle text-50 hover:text-[var(--primary)] transition-colors cursor-pointer shrink-0 flex items-center justify-center h-6 w-6 rounded-md hover:bg-black/5 dark:hover:bg-white/10"
|
||||
aria-label="Toggle children"
|
||||
>
|
||||
<Icon
|
||||
name="material-symbols:chevron-right-rounded"
|
||||
class="text-xl transition-transform duration-200"
|
||||
/>
|
||||
</button>
|
||||
) : (
|
||||
<span class="w-6 shrink-0" />
|
||||
)
|
||||
}
|
||||
|
||||
<a
|
||||
href={category.url}
|
||||
class="text-75 group-hover:text-[var(--primary)] transition-all truncate flex-1"
|
||||
>
|
||||
{category.name}
|
||||
</a>
|
||||
</div>
|
||||
|
||||
<span
|
||||
class="text-sm text-50 bg-black/5 dark:bg-white/10 px-2 py-0.5 rounded shrink-0 ml-2"
|
||||
>
|
||||
{category.count}
|
||||
</span>
|
||||
</div>
|
||||
|
||||
{
|
||||
hasChildren && (
|
||||
<div class="drawer-content grid grid-rows-[0fr] transition-[grid-template-rows] duration-200 ease-out pl-3 ml-3 border-l border-[var(--line-divider)]">
|
||||
<div class="overflow-hidden">
|
||||
{category.children.map((child) => (
|
||||
<Astro.self category={child} depth={depth + 1} />
|
||||
))}
|
||||
</div>
|
||||
</div>
|
||||
)
|
||||
}
|
||||
</div>
|
||||
85
src/components/widget/CategoryList.astro
Normal file
85
src/components/widget/CategoryList.astro
Normal file
@@ -0,0 +1,85 @@
|
||||
---
|
||||
import { getSortedPosts } from "@utils/content-utils";
|
||||
import { buildCategoryTree } from "@utils/category-utils";
|
||||
import { Icon } from "astro-icon/components";
|
||||
import CategoryDrawer from "./CategoryDrawer.astro";
|
||||
|
||||
const allPosts = await getSortedPosts();
|
||||
const categoryTree = await buildCategoryTree(allPosts);
|
||||
|
||||
function getTotalCount(cat: any): number {
|
||||
let count = cat.count;
|
||||
if (cat.children) {
|
||||
for (const child of cat.children) {
|
||||
count += getTotalCount(child);
|
||||
}
|
||||
}
|
||||
return count;
|
||||
}
|
||||
|
||||
// Get only top-level categories, sort by total post count (including children), max 15
|
||||
const topCategories = Object.values(categoryTree)
|
||||
.filter((cat) => cat.path.length === 1)
|
||||
.map((cat) => ({ ...cat, totalCount: getTotalCount(cat) }))
|
||||
.sort((a, b) => b.totalCount - a.totalCount)
|
||||
.slice(0, 15);
|
||||
---
|
||||
|
||||
<div class="card-base px-6 py-5">
|
||||
<div class="flex items-center gap-2 mb-4">
|
||||
<Icon
|
||||
name="material-symbols:folder-outline-rounded"
|
||||
class="text-[var(--primary)]"
|
||||
/>
|
||||
<h2 class="text-lg font-bold text-90">分类</h2>
|
||||
</div>
|
||||
|
||||
<div class="flex flex-col gap-0">
|
||||
{topCategories.map((category) => <CategoryDrawer category={category} />)}
|
||||
</div>
|
||||
|
||||
<a
|
||||
href="/category/"
|
||||
class="mt-4 text-center text-sm text-[var(--primary)] hover:underline block"
|
||||
>
|
||||
查看全部分类 →
|
||||
</a>
|
||||
</div>
|
||||
|
||||
<script>
|
||||
function setupCategoryDrawer() {
|
||||
const toggles = document.querySelectorAll(".drawer-toggle");
|
||||
toggles.forEach((toggle) => {
|
||||
if (toggle.hasAttribute("data-bound")) return;
|
||||
toggle.setAttribute("data-bound", "true");
|
||||
|
||||
toggle.addEventListener("click", (e) => {
|
||||
e.preventDefault();
|
||||
e.stopPropagation();
|
||||
|
||||
const drawer = toggle.closest(".category-drawer");
|
||||
const content = drawer.querySelector(".drawer-content");
|
||||
const icon = toggle.querySelector("svg");
|
||||
|
||||
if (!content || !icon) return;
|
||||
|
||||
const isExpanded = content.style.gridTemplateRows === "1fr";
|
||||
|
||||
if (isExpanded) {
|
||||
content.style.gridTemplateRows = "0fr";
|
||||
icon.style.transform = "rotate(0deg)";
|
||||
} else {
|
||||
content.style.gridTemplateRows = "1fr";
|
||||
icon.style.transform = "rotate(90deg)";
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
|
||||
setupCategoryDrawer();
|
||||
|
||||
// Re-run on Swup navigation
|
||||
if (window.swup) {
|
||||
window.swup.hooks.on("content:replace", setupCategoryDrawer);
|
||||
}
|
||||
</script>
|
||||
331
src/components/widget/DisplaySettings.svelte
Normal file
331
src/components/widget/DisplaySettings.svelte
Normal file
@@ -0,0 +1,331 @@
|
||||
<script lang="ts">
|
||||
import { onMount } from "svelte";
|
||||
import Icon from "@iconify/svelte";
|
||||
import {
|
||||
getDefaultHue,
|
||||
getHue,
|
||||
setHue,
|
||||
getStoredTheme,
|
||||
setTheme,
|
||||
getRainbowMode,
|
||||
setRainbowMode,
|
||||
getRainbowSpeed,
|
||||
setRainbowSpeed,
|
||||
getBgBlur,
|
||||
setBgBlur,
|
||||
setBgHueRotate,
|
||||
getHideBg,
|
||||
setHideBg,
|
||||
getDevMode,
|
||||
setDevMode,
|
||||
getDevServer,
|
||||
setDevServer,
|
||||
} from "@utils/setting-utils";
|
||||
import { AUTO_MODE, DARK_MODE, LIGHT_MODE } from "@constants/constants";
|
||||
|
||||
let hue = getHue();
|
||||
let theme = getStoredTheme();
|
||||
let isRainbowMode = getRainbowMode();
|
||||
let rainbowSpeed = getRainbowSpeed();
|
||||
let bgBlur = getBgBlur();
|
||||
let hideBg = getHideBg();
|
||||
let isDevMode = getDevMode();
|
||||
let devServer = getDevServer();
|
||||
let animationId: number;
|
||||
let lastUpdate = 0;
|
||||
let rainbowHue = 0; // Independent hue for background rotation
|
||||
|
||||
const defaultHue = getDefaultHue();
|
||||
|
||||
function resetHue() {
|
||||
hue = getDefaultHue();
|
||||
}
|
||||
|
||||
$: if ((hue || hue === 0) && !isRainbowMode) {
|
||||
setHue(hue);
|
||||
}
|
||||
|
||||
$: {
|
||||
setBgBlur(bgBlur);
|
||||
}
|
||||
|
||||
function switchTheme(newTheme: string) {
|
||||
theme = newTheme;
|
||||
setTheme(newTheme);
|
||||
}
|
||||
|
||||
function updateRainbow() {
|
||||
if (!isRainbowMode) return;
|
||||
|
||||
hue = (hue + rainbowSpeed * 0.05) % 360;
|
||||
setHue(hue, false);
|
||||
|
||||
animationId = requestAnimationFrame(updateRainbow);
|
||||
}
|
||||
|
||||
function toggleRainbow() {
|
||||
isRainbowMode = !isRainbowMode;
|
||||
setRainbowMode(isRainbowMode);
|
||||
|
||||
if (isRainbowMode) {
|
||||
lastUpdate = performance.now();
|
||||
rainbowHue = 0; // Reset rotation start
|
||||
animationId = requestAnimationFrame(updateRainbow);
|
||||
} else {
|
||||
cancelAnimationFrame(animationId);
|
||||
// Reset background rotation to 0 when stopped
|
||||
setBgHueRotate(0);
|
||||
}
|
||||
}
|
||||
|
||||
function toggleHideBg() {
|
||||
hideBg = !hideBg;
|
||||
setHideBg(hideBg);
|
||||
}
|
||||
|
||||
function toggleDevMode() {
|
||||
isDevMode = !isDevMode;
|
||||
setDevMode(isDevMode);
|
||||
}
|
||||
|
||||
function onDevServerChange() {
|
||||
setDevServer(devServer);
|
||||
}
|
||||
|
||||
function onSpeedChange() {
|
||||
setRainbowSpeed(rainbowSpeed);
|
||||
}
|
||||
|
||||
onMount(() => {
|
||||
if (isRainbowMode) {
|
||||
updateRainbow();
|
||||
}
|
||||
return () => {
|
||||
if (animationId) cancelAnimationFrame(animationId);
|
||||
}
|
||||
});
|
||||
</script>
|
||||
|
||||
<div id="display-setting" class="float-panel float-panel-closed absolute transition-all w-80 right-4 px-4 py-4">
|
||||
<div class="flex flex-row gap-2 mb-3 items-center justify-between">
|
||||
<div class="flex gap-2 font-bold text-lg text-neutral-900 dark:text-neutral-100 transition relative ml-3
|
||||
before:w-1 before:h-4 before:rounded-md before:bg-[var(--primary)]
|
||||
before:absolute before:-left-3 before:top-[0.33rem]"
|
||||
>
|
||||
主题模式
|
||||
</div>
|
||||
<div class="flex gap-1">
|
||||
<button aria-label="Light Mode"
|
||||
class="w-10 h-7 rounded-md transition flex items-center justify-center active:scale-90
|
||||
{theme === LIGHT_MODE ? 'bg-[var(--primary)] text-white' : 'bg-[var(--btn-regular-bg)] text-[var(--btn-content)] hover:bg-[var(--btn-regular-bg-hover)]'}"
|
||||
on:click={() => switchTheme(LIGHT_MODE)}
|
||||
>
|
||||
<Icon icon="material-symbols:wb-sunny-rounded" class="text-[1.1rem]"></Icon>
|
||||
</button>
|
||||
<button aria-label="Dark Mode"
|
||||
class="w-10 h-7 rounded-md transition flex items-center justify-center active:scale-90
|
||||
{theme === DARK_MODE ? 'bg-[var(--primary)] text-white' : 'bg-[var(--btn-regular-bg)] text-[var(--btn-content)] hover:bg-[var(--btn-regular-bg-hover)]'}"
|
||||
on:click={() => switchTheme(DARK_MODE)}
|
||||
>
|
||||
<Icon icon="material-symbols:dark-mode-rounded" class="text-[1.1rem]"></Icon>
|
||||
</button>
|
||||
<button aria-label="Auto Mode"
|
||||
class="w-10 h-7 rounded-md transition flex items-center justify-center active:scale-90
|
||||
{theme === AUTO_MODE ? 'bg-[var(--primary)] text-white' : 'bg-[var(--btn-regular-bg)] text-[var(--btn-content)] hover:bg-[var(--btn-regular-bg-hover)]'}"
|
||||
on:click={() => switchTheme(AUTO_MODE)}
|
||||
>
|
||||
<Icon icon="material-symbols:hdr-auto-rounded" class="text-[1.1rem]"></Icon>
|
||||
</button>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="flex flex-row gap-2 mb-3 items-center justify-between">
|
||||
<div class="flex gap-2 font-bold text-lg text-neutral-900 dark:text-neutral-100 transition relative ml-3
|
||||
before:w-1 before:h-4 before:rounded-md before:bg-[var(--primary)]
|
||||
before:absolute before:-left-3 before:top-[0.33rem]"
|
||||
>
|
||||
主题色彩
|
||||
<button aria-label="Reset to Default" class="btn-regular w-7 h-7 rounded-md active:scale-90"
|
||||
class:opacity-0={hue === defaultHue} class:pointer-events-none={hue === defaultHue} on:click={resetHue}>
|
||||
<div class="text-[var(--btn-content)]">
|
||||
<Icon icon="fa6-solid:arrow-rotate-left" class="text-[0.875rem]"></Icon>
|
||||
</div>
|
||||
</button>
|
||||
</div>
|
||||
<div class="flex gap-1">
|
||||
<input aria-label="Hue Value" id="hueValue" type="number" min="0" max="360" value={Math.round(hue)} on:input={(e) => hue = e.currentTarget.valueAsNumber} disabled={isRainbowMode}
|
||||
class="transition bg-[var(--btn-regular-bg)] w-12 h-7 rounded-md text-center font-bold text-sm text-[var(--btn-content)] outline-none"
|
||||
/>
|
||||
</div>
|
||||
</div>
|
||||
<div class="w-full h-6 px-1 bg-[oklch(0.80_0.10_0)] dark:bg-[oklch(0.70_0.10_0)] rounded select-none mb-3">
|
||||
<input aria-label="主题色彩" type="range" min="0" max="360" bind:value={hue} disabled={isRainbowMode}
|
||||
class="slider" id="colorSlider" step="1" style="width: 100%">
|
||||
</div>
|
||||
|
||||
<div class="flex flex-row gap-2 mb-3 items-center justify-between">
|
||||
<div class="flex gap-2 font-bold text-lg text-neutral-900 dark:text-neutral-100 transition relative ml-3
|
||||
before:w-1 before:h-4 before:rounded-md before:bg-[var(--primary)]
|
||||
before:absolute before:-left-3 before:top-[0.33rem]"
|
||||
>
|
||||
禁用背景
|
||||
</div>
|
||||
<input type="checkbox" class="toggle-switch" checked={hideBg} on:change={toggleHideBg} />
|
||||
</div>
|
||||
|
||||
<div class="flex flex-row gap-2 mb-3 items-center justify-between">
|
||||
<div class="flex gap-2 font-bold text-lg text-neutral-900 dark:text-neutral-100 transition relative ml-3
|
||||
before:w-1 before:h-4 before:rounded-md before:bg-[var(--primary)]
|
||||
before:absolute before:-left-3 before:top-[0.33rem]"
|
||||
>
|
||||
彩虹模式
|
||||
</div>
|
||||
<input type="checkbox" class="toggle-switch" checked={isRainbowMode} on:change={toggleRainbow} />
|
||||
</div>
|
||||
|
||||
{#if isRainbowMode}
|
||||
<div class="flex flex-row gap-2 mb-3 items-center justify-between transition-all" >
|
||||
<div class="flex gap-2 font-bold text-lg text-neutral-900 dark:text-neutral-100 transition relative ml-3
|
||||
before:w-1 before:h-4 before:rounded-md before:bg-[var(--primary)]
|
||||
before:absolute before:-left-3 before:top-[0.33rem]"
|
||||
>
|
||||
变换速率
|
||||
</div>
|
||||
<div class="flex gap-1">
|
||||
<div class="transition bg-[var(--btn-regular-bg)] w-10 h-7 rounded-md flex justify-center
|
||||
font-bold text-sm items-center text-[var(--btn-content)]">
|
||||
{rainbowSpeed}
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<div class="w-full h-6 px-1 bg-[var(--btn-regular-bg)] rounded select-none">
|
||||
<input aria-label="变换速率" type="range" min="1" max="100" bind:value={rainbowSpeed} on:change={onSpeedChange}
|
||||
class="slider" step="1" style="width: 100%">
|
||||
</div>
|
||||
{/if}
|
||||
|
||||
<div class="flex flex-row gap-2 mb-3 mt-3 items-center justify-between">
|
||||
<div class="flex gap-2 font-bold text-lg text-neutral-900 dark:text-neutral-100 transition relative ml-3
|
||||
before:w-1 before:h-4 before:rounded-md before:bg-[var(--primary)]
|
||||
before:absolute before:-left-3 before:top-[0.33rem]"
|
||||
>
|
||||
背景模糊
|
||||
</div>
|
||||
<div class="flex gap-1">
|
||||
<div class="transition bg-[var(--btn-regular-bg)] w-10 h-7 rounded-md flex justify-center
|
||||
font-bold text-sm items-center text-[var(--btn-content)]">
|
||||
{bgBlur}px
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<div class="w-full h-6 px-1 bg-[var(--btn-regular-bg)] rounded select-none">
|
||||
<input aria-label="背景模糊" type="range" min="0" max="20" bind:value={bgBlur}
|
||||
class="slider" step="1" style="width: 100%">
|
||||
</div>
|
||||
|
||||
<div class="flex flex-row gap-2 mb-3 mt-3 items-center justify-between">
|
||||
<div class="flex gap-2 font-bold text-lg text-neutral-900 dark:text-neutral-100 transition relative ml-3
|
||||
before:w-1 before:h-4 before:rounded-md before:bg-[var(--primary)]
|
||||
before:absolute before:-left-3 before:top-[0.33rem]"
|
||||
>
|
||||
开发模式
|
||||
</div>
|
||||
<input type="checkbox" class="toggle-switch" checked={isDevMode} on:change={toggleDevMode} />
|
||||
</div>
|
||||
|
||||
{#if isDevMode}
|
||||
<div class="flex flex-row gap-2 mb-3 items-center justify-between transition-all" >
|
||||
<div class="flex gap-2 font-bold text-lg text-neutral-900 dark:text-neutral-100 transition relative ml-3
|
||||
before:w-1 before:h-4 before:rounded-md before:bg-[var(--primary)]
|
||||
before:absolute before:-left-3 before:top-[0.33rem]"
|
||||
>
|
||||
Server
|
||||
</div>
|
||||
<div class="flex gap-1">
|
||||
<input aria-label="Server Value" type="text" bind:value={devServer} on:input={onDevServerChange}
|
||||
class="transition bg-[var(--btn-regular-bg)] w-32 h-7 rounded-md text-center font-bold text-sm text-[var(--btn-content)] outline-none"
|
||||
/>
|
||||
</div>
|
||||
</div>
|
||||
{/if}
|
||||
</div>
|
||||
|
||||
|
||||
<style lang="stylus">
|
||||
#display-setting
|
||||
input[type="number"]
|
||||
-moz-appearance textfield
|
||||
&::-webkit-inner-spin-button
|
||||
&::-webkit-outer-spin-button
|
||||
-webkit-appearance none
|
||||
margin 0
|
||||
|
||||
input[type="range"]
|
||||
-webkit-appearance none
|
||||
height 1.5rem
|
||||
background-image var(--color-selection-bar)
|
||||
transition background-image 0.15s ease-in-out
|
||||
|
||||
/* Input Thumb */
|
||||
&::-webkit-slider-thumb
|
||||
-webkit-appearance none
|
||||
height 1rem
|
||||
width 0.5rem
|
||||
border-radius 0.125rem
|
||||
background rgba(255, 255, 255, 0.7)
|
||||
box-shadow none
|
||||
&:hover
|
||||
background rgba(255, 255, 255, 0.8)
|
||||
&:active
|
||||
background rgba(255, 255, 255, 0.6)
|
||||
|
||||
&::-moz-range-thumb
|
||||
-webkit-appearance none
|
||||
height 1rem
|
||||
width 0.5rem
|
||||
border-radius 0.125rem
|
||||
border-width 0
|
||||
background rgba(255, 255, 255, 0.7)
|
||||
box-shadow none
|
||||
&:hover
|
||||
background rgba(255, 255, 255, 0.8)
|
||||
&:active
|
||||
background rgba(255, 255, 255, 0.6)
|
||||
|
||||
&::-ms-thumb
|
||||
-webkit-appearance none
|
||||
height 1rem
|
||||
width 0.5rem
|
||||
border-radius 0.125rem
|
||||
background rgba(255, 255, 255, 0.7)
|
||||
box-shadow none
|
||||
&:hover
|
||||
background rgba(255, 255, 255, 0.8)
|
||||
&:active
|
||||
background rgba(255, 255, 255, 0.6)
|
||||
|
||||
.toggle-switch
|
||||
appearance none
|
||||
width 3rem
|
||||
height 1.5rem
|
||||
background var(--btn-regular-bg)
|
||||
border-radius 999px
|
||||
position relative
|
||||
cursor pointer
|
||||
transition background 0.3s
|
||||
&::after
|
||||
content ''
|
||||
position absolute
|
||||
top 0.25rem
|
||||
left 0.25rem
|
||||
width 1rem
|
||||
height 1rem
|
||||
background var(--btn-content)
|
||||
border-radius 50%
|
||||
transition transform 0.3s
|
||||
&:checked
|
||||
background var(--primary)
|
||||
&::after
|
||||
transform translateX(1.5rem)
|
||||
background white
|
||||
</style>
|
||||
32
src/components/widget/NavMenuPanel.astro
Normal file
32
src/components/widget/NavMenuPanel.astro
Normal file
@@ -0,0 +1,32 @@
|
||||
---
|
||||
import { Icon } from "astro-icon/components";
|
||||
import { type NavBarLink } from "../../types/config";
|
||||
import { url } from "../../utils/url-utils";
|
||||
|
||||
interface Props {
|
||||
links: NavBarLink[];
|
||||
}
|
||||
|
||||
const links = Astro.props.links;
|
||||
---
|
||||
<div id="nav-menu-panel" class:list={["float-panel float-panel-closed absolute transition-all fixed right-4 px-2 py-2"]}>
|
||||
{links.map((link) => (
|
||||
<a href={link.external ? link.url : url(link.url)} class="group flex justify-between items-center py-2 pl-3 pr-1 rounded-lg gap-8
|
||||
hover:bg-[var(--btn-plain-bg-hover)] active:bg-[var(--btn-plain-bg-active)] transition
|
||||
"
|
||||
target={link.external ? "_blank" : null}
|
||||
>
|
||||
<div class="transition text-black/75 dark:text-white/75 font-bold group-hover:text-[var(--primary)] group-active:text-[var(--primary)]">
|
||||
{link.name}
|
||||
</div>
|
||||
{!link.external && <Icon name="material-symbols:chevron-right-rounded"
|
||||
class="transition text-[1.25rem] text-[var(--primary)]"
|
||||
>
|
||||
</Icon>}
|
||||
{link.external && <Icon name="fa6-solid:arrow-up-right-from-square"
|
||||
class="transition text-[0.75rem] text-black/25 dark:text-white/25 -translate-x-1"
|
||||
>
|
||||
</Icon>}
|
||||
</a>
|
||||
))}
|
||||
</div>
|
||||
93
src/components/widget/Profile.astro
Normal file
93
src/components/widget/Profile.astro
Normal file
@@ -0,0 +1,93 @@
|
||||
---
|
||||
import { Icon } from "astro-icon/components";
|
||||
import { profileConfig, umamiConfig, siteConfig } from "../../config";
|
||||
|
||||
const config = profileConfig;
|
||||
---
|
||||
<div class="card-base p-3 border border-black/10 dark:border-white/10">
|
||||
<div class="relative mx-auto mt-1 lg:mx-0 lg:mt-0 mb-3 max-w-[12rem] lg:max-w-none rounded-xl overflow-hidden" style={`--theme-hue: ${siteConfig.themeColor.hue}`}>
|
||||
<div class="loading-bar absolute top-1/2 left-1/2 transform -translate-x-1/2 -translate-y-1/2 w-32 h-1 bg-gray-200 dark:bg-gray-700 z-10 rounded-full overflow-hidden">
|
||||
<div class="loading-progress h-full w-8 bg-[oklch(0.70_0.14_var(--theme-hue))] animate-loading-progress rounded-full"></div>
|
||||
</div>
|
||||
<img src={config.avatar} alt="Profile Image of the Author" class="w-full h-full object-cover opacity-0 transition-opacity duration-500" onload="this.style.opacity='1'; this.parentElement.querySelector('.loading-bar').style.opacity='0';"/>
|
||||
</div>
|
||||
<div class="px-2">
|
||||
<div class="font-bold text-xl text-center mb-1 dark:text-neutral-50 transition">{config.name}</div>
|
||||
<div class="h-1 w-5 bg-[var(--primary)] mx-auto rounded-full mb-2 transition"></div>
|
||||
<div class="text-center text-neutral-400 mb-2.5 transition">{config.bio}</div>
|
||||
<div class="flex flex-wrap gap-2 justify-center mb-1">
|
||||
{config.links.length > 1 && config.links.map(item =>
|
||||
<a rel="me" aria-label={item.name} href={item.url} target="_blank" class="btn-regular rounded-lg h-10 w-10 active:scale-90">
|
||||
<Icon name={item.icon} class="text-[1.5rem]"></Icon>
|
||||
</a>
|
||||
)}
|
||||
{config.links.length == 1 && <a rel="me" aria-label={config.links[0].name} href={config.links[0].url} target="_blank"
|
||||
class="btn-regular rounded-lg h-10 gap-2 px-3 font-bold active:scale-95">
|
||||
<Icon name={config.links[0].icon} class="text-[1.5rem]"></Icon>
|
||||
{config.links[0].name}
|
||||
</a>}
|
||||
</div>
|
||||
|
||||
<!-- 全站访问量统计 -->
|
||||
<div class="grid grid-cols-2 mt-3 pt-3 border-t border-neutral-200 dark:border-neutral-700">
|
||||
<div class="text-center">
|
||||
<div class="text-xs text-neutral-500 mb-1 flex items-center justify-center gap-1">
|
||||
<Icon name="material-symbols:visibility-outline" class="text-base"></Icon>
|
||||
<span class="text-xs">访问量</span>
|
||||
</div>
|
||||
<div id="site-views" class="font-bold text-lg text-neutral-700 dark:text-neutral-300">-</div>
|
||||
</div>
|
||||
<div class="text-center border-l border-neutral-200 dark:border-neutral-700">
|
||||
<div class="text-xs text-neutral-500 mb-1 flex items-center justify-center gap-1">
|
||||
<Icon name="material-symbols:person" class="text-base"></Icon>
|
||||
<span class="text-xs">访客数</span>
|
||||
</div>
|
||||
<div id="site-visitors" class="font-bold text-lg text-neutral-700 dark:text-neutral-300">-</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<style>
|
||||
.loading-bar {
|
||||
transition: opacity 0.5s ease-out;
|
||||
}
|
||||
|
||||
@keyframes loading-progress {
|
||||
0% {
|
||||
transform: translateX(-100%);
|
||||
}
|
||||
100% {
|
||||
transform: translateX(400%);
|
||||
}
|
||||
}
|
||||
|
||||
.animate-loading-progress {
|
||||
animation: loading-progress 1.5s ease-in-out infinite;
|
||||
}
|
||||
</style>
|
||||
|
||||
<script define:vars={{ umamiConfig}}>
|
||||
// 获取全站访问量统计
|
||||
async function loadSiteStats() {
|
||||
if (!umamiConfig.enable) return;
|
||||
try {
|
||||
const statsData = await fetchUmamiStats(umamiConfig.baseUrl, umamiConfig.shareId, {
|
||||
timezone: umamiConfig.timezone
|
||||
});
|
||||
|
||||
const pageviews = statsData.pageviews || 0;
|
||||
const visitors = statsData.visitors || 0;
|
||||
|
||||
const viewsElement = document.getElementById('site-views');
|
||||
const visitorsElement = document.getElementById('site-visitors');
|
||||
if (viewsElement) viewsElement.textContent = pageviews;
|
||||
if (visitorsElement) visitorsElement.textContent = visitors;
|
||||
} catch (error) {
|
||||
console.error('获取全站统计失败:', error);
|
||||
}
|
||||
}
|
||||
|
||||
// 页面加载完成后获取统计数据
|
||||
document.addEventListener('DOMContentLoaded', loadSiteStats);
|
||||
</script>
|
||||
24
src/components/widget/SideBar.astro
Normal file
24
src/components/widget/SideBar.astro
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
import type { MarkdownHeading } from "astro";
|
||||
|
||||
import Profile from "./Profile.astro";
|
||||
import CategoryList from "./CategoryList.astro";
|
||||
|
||||
interface Props {
|
||||
class?: string;
|
||||
headings?: MarkdownHeading[];
|
||||
}
|
||||
|
||||
const className = Astro.props.class;
|
||||
---
|
||||
<div id="sidebar" class:list={[className, "w-full"]}>
|
||||
<div class="flex flex-col w-full gap-4 mb-4">
|
||||
<Profile></Profile>
|
||||
<CategoryList />
|
||||
</div>
|
||||
<div id="sidebar-sticky" class="transition-all duration-700 flex flex-col w-full gap-4 top-4 sticky top-4">
|
||||
</div>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
268
src/components/widget/TOC.astro
Normal file
268
src/components/widget/TOC.astro
Normal file
@@ -0,0 +1,268 @@
|
||||
---
|
||||
import type { MarkdownHeading } from "astro";
|
||||
import { siteConfig } from "../../config";
|
||||
|
||||
interface Props {
|
||||
class?: string;
|
||||
headings: MarkdownHeading[];
|
||||
}
|
||||
|
||||
let { headings = [] } = Astro.props;
|
||||
|
||||
let minDepth = 10;
|
||||
for (const heading of headings) {
|
||||
minDepth = Math.min(minDepth, heading.depth);
|
||||
}
|
||||
|
||||
const className = Astro.props.class;
|
||||
|
||||
const isPostsRoute = Astro.url.pathname.startsWith("/posts/");
|
||||
|
||||
const removeTailingHash = (text: string) => {
|
||||
let lastIndexOfHash = text.lastIndexOf("#");
|
||||
if (lastIndexOfHash !== text.length - 1) {
|
||||
return text;
|
||||
}
|
||||
|
||||
return text.substring(0, lastIndexOfHash);
|
||||
};
|
||||
|
||||
let heading1Count = 1;
|
||||
|
||||
const maxLevel = siteConfig.toc.depth;
|
||||
---
|
||||
{isPostsRoute &&
|
||||
<table-of-contents class:list={[className, "group"]}>
|
||||
{headings.filter((heading) => heading.depth < minDepth + maxLevel).map((heading) =>
|
||||
<a href={`#${heading.slug}`} class="px-2 flex gap-2 relative transition w-full min-h-9 rounded-xl
|
||||
hover:bg-[var(--toc-btn-hover)] active:bg-[var(--toc-btn-active)] py-2
|
||||
">
|
||||
<div class:list={["transition w-5 h-5 shrink-0 rounded-lg text-xs flex items-center justify-center font-bold",
|
||||
{
|
||||
"bg-[var(--toc-badge-bg)] text-[var(--btn-content)]": heading.depth == minDepth,
|
||||
"ml-4": heading.depth == minDepth + 1,
|
||||
"ml-8": heading.depth == minDepth + 2,
|
||||
}
|
||||
]}
|
||||
>
|
||||
{heading.depth == minDepth && heading1Count++}
|
||||
{heading.depth == minDepth + 1 && <div class="transition w-2 h-2 rounded-[0.1875rem] bg-[var(--toc-badge-bg)]"></div>}
|
||||
{heading.depth == minDepth + 2 && <div class="transition w-1.5 h-1.5 rounded-sm bg-black/5 dark:bg-white/10"></div>}
|
||||
</div>
|
||||
<div class:list={["transition text-sm", {
|
||||
"text-50": heading.depth == minDepth || heading.depth == minDepth + 1,
|
||||
"text-30": heading.depth == minDepth + 2,
|
||||
}]}>{removeTailingHash(heading.text)}</div>
|
||||
</a>
|
||||
)}
|
||||
<div id="active-indicator" class:list={[{'hidden': headings.length == 0}, "-z-10 absolute bg-[var(--toc-btn-hover)] left-0 right-0 rounded-xl transition-all " +
|
||||
"group-hover:bg-transparent border-2 border-[var(--toc-btn-hover)] group-hover:border-[var(--toc-btn-active)] border-dashed"]}></div>
|
||||
</table-of-contents>}
|
||||
|
||||
<script>
|
||||
class TableOfContents extends HTMLElement {
|
||||
tocEl: HTMLElement | null = null;
|
||||
visibleClass = "visible";
|
||||
observer: IntersectionObserver;
|
||||
anchorNavTarget: HTMLElement | null = null;
|
||||
headingIdxMap = new Map<string, number>();
|
||||
headings: HTMLElement[] = [];
|
||||
sections: HTMLElement[] = [];
|
||||
tocEntries: HTMLAnchorElement[] = [];
|
||||
active: boolean[] = [];
|
||||
activeIndicator: HTMLElement | null = null;
|
||||
|
||||
constructor() {
|
||||
super();
|
||||
this.observer = new IntersectionObserver(
|
||||
this.markVisibleSection, { threshold: 0 }
|
||||
);
|
||||
};
|
||||
|
||||
markVisibleSection = (entries: IntersectionObserverEntry[]) => {
|
||||
entries.forEach((entry) => {
|
||||
const id = entry.target.children[0]?.getAttribute("id");
|
||||
const idx = id ? this.headingIdxMap.get(id) : undefined;
|
||||
if (idx != undefined)
|
||||
this.active[idx] = entry.isIntersecting;
|
||||
|
||||
if (entry.isIntersecting && this.anchorNavTarget == entry.target.firstChild)
|
||||
this.anchorNavTarget = null;
|
||||
});
|
||||
|
||||
if (!this.active.includes(true)) {
|
||||
// 当没有任何标题在视窗中时,隐藏 active-indicator
|
||||
this.activeIndicator?.setAttribute("style", "display: none;");
|
||||
this.fallback();
|
||||
return;
|
||||
}
|
||||
this.update();
|
||||
};
|
||||
|
||||
toggleActiveHeading = () => {
|
||||
let i = this.active.length - 1;
|
||||
let min = this.active.length - 1, max = 0;
|
||||
while (i >= 0 && !this.active[i]) {
|
||||
this.tocEntries[i].classList.remove(this.visibleClass);
|
||||
i--;
|
||||
}
|
||||
while (i >= 0 && this.active[i]) {
|
||||
this.tocEntries[i].classList.add(this.visibleClass);
|
||||
min = Math.min(min, i);
|
||||
max = Math.max(max, i);
|
||||
i--;
|
||||
}
|
||||
while (i >= 0) {
|
||||
this.tocEntries[i].classList.remove(this.visibleClass);
|
||||
i--;
|
||||
}
|
||||
let parentOffset = this.tocEl?.getBoundingClientRect().top || 0;
|
||||
let scrollOffset = this.tocEl?.scrollTop || 0;
|
||||
let top = this.tocEntries[min].getBoundingClientRect().top - parentOffset + scrollOffset;
|
||||
let bottom = this.tocEntries[max].getBoundingClientRect().bottom - parentOffset + scrollOffset;
|
||||
this.activeIndicator?.setAttribute("style", `display: block; top: ${top}px; height: ${bottom - top}px`);
|
||||
};
|
||||
|
||||
scrollToActiveHeading = () => {
|
||||
// If the TOC widget can accommodate both the topmost
|
||||
// and bottommost items, scroll to the topmost item.
|
||||
// Otherwise, scroll to the bottommost one.
|
||||
|
||||
if (this.anchorNavTarget || !this.tocEl) return;
|
||||
const activeHeading =
|
||||
document.querySelectorAll<HTMLDivElement>(`#toc .${this.visibleClass}`);
|
||||
if (!activeHeading.length) return;
|
||||
|
||||
const topmost = activeHeading[0];
|
||||
const bottommost = activeHeading[activeHeading.length - 1];
|
||||
const tocHeight = this.tocEl.clientHeight;
|
||||
|
||||
let top;
|
||||
if (bottommost.getBoundingClientRect().bottom -
|
||||
topmost.getBoundingClientRect().top < 0.9 * tocHeight)
|
||||
top = topmost.offsetTop - 32;
|
||||
else
|
||||
top = bottommost.offsetTop - tocHeight * 0.8;
|
||||
|
||||
this.tocEl.scrollTo({
|
||||
top,
|
||||
left: 0,
|
||||
behavior: "smooth",
|
||||
});
|
||||
};
|
||||
|
||||
update = () => {
|
||||
requestAnimationFrame(() => {
|
||||
this.toggleActiveHeading();
|
||||
// requestAnimationFrame(() => {
|
||||
this.scrollToActiveHeading();
|
||||
// });
|
||||
});
|
||||
};
|
||||
|
||||
fallback = () => {
|
||||
if (!this.sections.length) return;
|
||||
|
||||
for (let i = 0; i < this.sections.length; i++) {
|
||||
let offsetTop = this.sections[i].getBoundingClientRect().top;
|
||||
let offsetBottom = this.sections[i].getBoundingClientRect().bottom;
|
||||
|
||||
if (this.isInRange(offsetTop, 0, window.innerHeight)
|
||||
|| this.isInRange(offsetBottom, 0, window.innerHeight)
|
||||
|| (offsetTop < 0 && offsetBottom > window.innerHeight)) {
|
||||
this.markActiveHeading(i);
|
||||
}
|
||||
else if (offsetTop > window.innerHeight) break;
|
||||
}
|
||||
};
|
||||
|
||||
markActiveHeading = (idx: number)=> {
|
||||
this.active[idx] = true;
|
||||
};
|
||||
|
||||
handleAnchorClick = (event: Event) => {
|
||||
const anchor = event
|
||||
.composedPath()
|
||||
.find((element) => element instanceof HTMLAnchorElement);
|
||||
|
||||
if (anchor) {
|
||||
const id = decodeURIComponent(anchor.hash?.substring(1));
|
||||
const idx = this.headingIdxMap.get(id);
|
||||
if (idx !== undefined) {
|
||||
this.anchorNavTarget = this.headings[idx];
|
||||
} else {
|
||||
this.anchorNavTarget = null;
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
isInRange(value: number, min: number, max: number) {
|
||||
return min < value && value < max;
|
||||
};
|
||||
|
||||
connectedCallback() {
|
||||
// wait for the onload animation to finish, which makes the `getBoundingClientRect` return correct values
|
||||
const element = document.querySelector('.prose');
|
||||
if (element) {
|
||||
element.addEventListener('animationend', () => {
|
||||
this.init();
|
||||
}, { once: true });
|
||||
} else {
|
||||
console.debug('Animation element not found');
|
||||
}
|
||||
};
|
||||
|
||||
init() {
|
||||
this.tocEl = document.getElementById(
|
||||
"toc-inner-wrapper"
|
||||
);
|
||||
|
||||
if (!this.tocEl) return;
|
||||
|
||||
this.tocEl.addEventListener("click", this.handleAnchorClick, {
|
||||
capture: true,
|
||||
});
|
||||
|
||||
this.activeIndicator = document.getElementById("active-indicator");
|
||||
|
||||
this.tocEntries = Array.from(
|
||||
document.querySelectorAll<HTMLAnchorElement>("#toc a[href^='#']")
|
||||
);
|
||||
|
||||
if (this.tocEntries.length === 0) return;
|
||||
|
||||
this.sections = new Array(this.tocEntries.length);
|
||||
this.headings = new Array(this.tocEntries.length);
|
||||
for (let i = 0; i < this.tocEntries.length; i++) {
|
||||
const id = decodeURIComponent(this.tocEntries[i].hash?.substring(1));
|
||||
const heading = document.getElementById(id);
|
||||
const section = heading?.parentElement;
|
||||
if (heading instanceof HTMLElement && section instanceof HTMLElement) {
|
||||
this.headings[i] = heading;
|
||||
this.sections[i] = section;
|
||||
this.headingIdxMap.set(id, i);
|
||||
}
|
||||
}
|
||||
this.active = new Array(this.tocEntries.length).fill(false);
|
||||
|
||||
this.sections.forEach((section) =>
|
||||
this.observer.observe(section)
|
||||
);
|
||||
|
||||
this.fallback();
|
||||
this.update();
|
||||
};
|
||||
|
||||
disconnectedCallback() {
|
||||
this.sections.forEach((section) =>
|
||||
this.observer.unobserve(section)
|
||||
);
|
||||
this.observer.disconnect();
|
||||
this.tocEl?.removeEventListener("click", this.handleAnchorClick);
|
||||
};
|
||||
}
|
||||
|
||||
if (!customElements.get("table-of-contents")) {
|
||||
customElements.define("table-of-contents", TableOfContents);
|
||||
}
|
||||
</script>
|
||||
158
src/config.ts
Normal file
158
src/config.ts
Normal file
@@ -0,0 +1,158 @@
|
||||
import type {
|
||||
ExpressiveCodeConfig,
|
||||
GitHubEditConfig,
|
||||
ImageFallbackConfig,
|
||||
LicenseConfig,
|
||||
NavBarConfig,
|
||||
ProfileConfig,
|
||||
SiteConfig,
|
||||
UmamiConfig,
|
||||
} from "./types/config";
|
||||
import { LinkPreset } from "./types/config";
|
||||
|
||||
export const siteConfig: SiteConfig = {
|
||||
title: "MeowRain的技术博客",
|
||||
subtitle: "技术分享与实践",
|
||||
description:
|
||||
"分享软件开发、编程语言、框架和工具的技术博客,涵盖实用教程、最佳实践和行业动态,帮助开发者提升技能。",
|
||||
|
||||
keywords: [],
|
||||
lang: "zh_CN", // 'en', 'zh_CN', 'zh_TW', 'ja', 'ko', 'es', 'th'
|
||||
themeColor: {
|
||||
hue: 361, // Default hue for the theme color, from 0 to 360. e.g. red: 0, teal: 200, cyan: 250, pink: 345
|
||||
fixed: false, // Hide the theme color picker for visitors
|
||||
forceDarkMode: false, // Force dark mode and hide theme switcher
|
||||
},
|
||||
banner: {
|
||||
enable: false,
|
||||
src: "/xinghui.avif", // Relative to the /src directory. Relative to the /public directory if it starts with '/'
|
||||
|
||||
position: "center", // Equivalent to object-position, only supports 'top', 'center', 'bottom'. 'center' by default
|
||||
credit: {
|
||||
enable: true, // Display the credit text of the banner image
|
||||
text: "Pixiv @chokei", // Credit text to be displayed
|
||||
|
||||
url: "https://www.pixiv.net/artworks/122782209", // (Optional) URL link to the original artwork or artist's page
|
||||
},
|
||||
},
|
||||
background: {
|
||||
enable: true, // Enable background image
|
||||
src: "", // Background image URL (supports HTTPS)
|
||||
position: "center", // Background position: 'top', 'center', 'bottom'
|
||||
size: "cover", // Background size: 'cover', 'contain', 'auto'
|
||||
repeat: "no-repeat", // Background repeat: 'no-repeat', 'repeat', 'repeat-x', 'repeat-y'
|
||||
attachment: "fixed", // Background attachment: 'fixed', 'scroll', 'local'
|
||||
opacity: 1, // Background opacity (0-1)
|
||||
},
|
||||
toc: {
|
||||
enable: true, // Display the table of contents on the right side of the post
|
||||
depth: 2, // Maximum heading depth to show in the table, from 1 to 3
|
||||
},
|
||||
favicon: [
|
||||
// Leave this array empty to use the default favicon
|
||||
{
|
||||
src: "https://q2.qlogo.cn/headimg_dl?dst_uin=2726730791&spec=0", // Path of the favicon, relative to the /public directory
|
||||
// theme: 'light', // (Optional) Either 'light' or 'dark', set only if you have different favicons for light and dark mode
|
||||
// sizes: '32x32', // (Optional) Size of the favicon, set only if you have favicons of different sizes
|
||||
},
|
||||
],
|
||||
officialSites: [
|
||||
{ url: "https://blog.meowrain.cn", alias: "EdgeOne CN" },
|
||||
{ url: "https://blog2.meowrain.cn", alias: "Global" },
|
||||
{ url: "https://www.meowrain.cn", alias: "Global" },
|
||||
],
|
||||
};
|
||||
|
||||
export const navBarConfig: NavBarConfig = {
|
||||
links: [
|
||||
LinkPreset.Home,
|
||||
LinkPreset.Archive,
|
||||
{
|
||||
name: "分类",
|
||||
url: "/category/",
|
||||
external: false,
|
||||
},
|
||||
{
|
||||
name: "相册",
|
||||
url: "/gallery/",
|
||||
external: false,
|
||||
},
|
||||
{
|
||||
name: "友链",
|
||||
url: "/friends/", // Internal links should not include the base path, as it is automatically added
|
||||
external: false, // Show an external link icon and will open in a new tab
|
||||
},
|
||||
{
|
||||
name: "赞助",
|
||||
url: "/sponsors/", // Internal links should not include the base path, as it is automatically added
|
||||
external: false, // Show an external link icon and will open in a new tab
|
||||
},
|
||||
// {
|
||||
// name: "统计",
|
||||
// url: "https://umami.acofork.com/share/CdkXbGgZr6ECKOyK", // Internal links should not include the base path, as it is automatically added
|
||||
// external: true, // Show an external link icon and will open in a new tab
|
||||
// },
|
||||
// {
|
||||
// name: "监控",
|
||||
// url: "https://eoddos.2x.nz", // Internal links should not include the base path, as it is automatically added
|
||||
// external: true, // Show an external link icon and will open in a new tab
|
||||
// },
|
||||
],
|
||||
};
|
||||
|
||||
export const profileConfig: ProfileConfig = {
|
||||
avatar: "https://blog.meowrain.cn/api/i/2025/07/18/zn3t6t-1.webp", // Relative to the /src directory. Relative to the /public directory if it starts with '/'
|
||||
name: "MeowRain",
|
||||
bio: "A developer who loves to code and learn new things,build code for love❤️ and fun🎉",
|
||||
links: [
|
||||
{
|
||||
name: "GitHub",
|
||||
icon: "fa6-brands:github",
|
||||
url: "https://github.com/meowrain",
|
||||
},
|
||||
{
|
||||
name: "我的OpenWebUI站",
|
||||
icon: "fa6-brands:airbnb",
|
||||
url: "https://ai.meowrain.cn",
|
||||
},
|
||||
{
|
||||
name: "服务器状态监控",
|
||||
icon: "fa6-solid:server",
|
||||
url: "https://status.meowrain.cn",
|
||||
},
|
||||
{
|
||||
name: "bilibili",
|
||||
icon: "fa6-brands:bilibili",
|
||||
url: "https://space.bilibili.com/386388600",
|
||||
},
|
||||
],
|
||||
};
|
||||
export const licenseConfig: LicenseConfig = {
|
||||
enable: true,
|
||||
name: "CC BY-NC-SA 4.0",
|
||||
url: "https://creativecommons.org/licenses/by-nc-sa/4.0/",
|
||||
};
|
||||
|
||||
export const imageFallbackConfig: ImageFallbackConfig = {
|
||||
enable: false,
|
||||
originalDomain: "https://eopfapi.acofork.com/pic?img=ua",
|
||||
fallbackDomain: "https://eopfapi.acofork.com/pic?img=ua",
|
||||
};
|
||||
|
||||
export const umamiConfig: UmamiConfig = {
|
||||
enable: true,
|
||||
baseUrl: "https://umami.acofork.com",
|
||||
shareId: "CdkXbGgZr6ECKOyK",
|
||||
timezone: "Asia/Shanghai",
|
||||
};
|
||||
|
||||
export const expressiveCodeConfig: ExpressiveCodeConfig = {
|
||||
theme: "github-dark",
|
||||
};
|
||||
|
||||
export const gitHubEditConfig: GitHubEditConfig = {
|
||||
enable: true,
|
||||
baseUrl: "https://github.com/afoim/fuwari/blob/main/src/content/posts",
|
||||
};
|
||||
|
||||
// todoConfig removed from here
|
||||
17
src/constants/constants.ts
Normal file
17
src/constants/constants.ts
Normal file
@@ -0,0 +1,17 @@
|
||||
export const PAGE_SIZE = 8;
|
||||
|
||||
export const LIGHT_MODE = "light",
|
||||
DARK_MODE = "dark",
|
||||
AUTO_MODE = "auto";
|
||||
export const DEFAULT_THEME = AUTO_MODE;
|
||||
|
||||
// Banner height unit: vh
|
||||
export const BANNER_HEIGHT = 35;
|
||||
export const BANNER_HEIGHT_EXTEND = 30;
|
||||
export const BANNER_HEIGHT_HOME = BANNER_HEIGHT + BANNER_HEIGHT_EXTEND;
|
||||
|
||||
// The height the main panel overlaps the banner, unit: rem
|
||||
export const MAIN_PANEL_OVERLAPS_BANNER_HEIGHT = 3.5;
|
||||
|
||||
// Page width: rem
|
||||
export const PAGE_WIDTH = 75;
|
||||
44
src/constants/icon.ts
Normal file
44
src/constants/icon.ts
Normal file
@@ -0,0 +1,44 @@
|
||||
import type { Favicon } from "@/types/config.ts";
|
||||
|
||||
export const defaultFavicons: Favicon[] = [
|
||||
{
|
||||
src: "/favicon/favicon-light-32.png",
|
||||
theme: "light",
|
||||
sizes: "32x32",
|
||||
},
|
||||
{
|
||||
src: "/favicon/favicon-light-128.png",
|
||||
theme: "light",
|
||||
sizes: "128x128",
|
||||
},
|
||||
{
|
||||
src: "/favicon/favicon-light-180.png",
|
||||
theme: "light",
|
||||
sizes: "180x180",
|
||||
},
|
||||
{
|
||||
src: "/favicon/favicon-light-192.png",
|
||||
theme: "light",
|
||||
sizes: "192x192",
|
||||
},
|
||||
{
|
||||
src: "/favicon/favicon-dark-32.png",
|
||||
theme: "dark",
|
||||
sizes: "32x32",
|
||||
},
|
||||
{
|
||||
src: "/favicon/favicon-dark-128.png",
|
||||
theme: "dark",
|
||||
sizes: "128x128",
|
||||
},
|
||||
{
|
||||
src: "/favicon/favicon-dark-180.png",
|
||||
theme: "dark",
|
||||
sizes: "180x180",
|
||||
},
|
||||
{
|
||||
src: "/favicon/favicon-dark-192.png",
|
||||
theme: "dark",
|
||||
sizes: "192x192",
|
||||
},
|
||||
];
|
||||
13
src/constants/link-presets.ts
Normal file
13
src/constants/link-presets.ts
Normal file
@@ -0,0 +1,13 @@
|
||||
import { LinkPreset, type NavBarLink } from "@/types/config";
|
||||
|
||||
|
||||
export const LinkPresets: { [key in LinkPreset]: NavBarLink } = {
|
||||
[LinkPreset.Home]: {
|
||||
name: "首页",
|
||||
url: "/",
|
||||
},
|
||||
[LinkPreset.Archive]: {
|
||||
name: "归档",
|
||||
url: "/archive/",
|
||||
},
|
||||
};
|
||||
6
src/content/.obsidian/app.json
vendored
Normal file
6
src/content/.obsidian/app.json
vendored
Normal file
@@ -0,0 +1,6 @@
|
||||
{
|
||||
"attachmentFolderPath": "assets/images",
|
||||
"newLinkFormat": "relative",
|
||||
"useMarkdownLinks": true,
|
||||
"uriCallbacks": false
|
||||
}
|
||||
1
src/content/.obsidian/appearance.json
vendored
Normal file
1
src/content/.obsidian/appearance.json
vendored
Normal file
@@ -0,0 +1 @@
|
||||
{}
|
||||
3
src/content/.obsidian/community-plugins.json
vendored
Normal file
3
src/content/.obsidian/community-plugins.json
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
[
|
||||
"obsidian-paste-image-rename"
|
||||
]
|
||||
33
src/content/.obsidian/core-plugins.json
vendored
Normal file
33
src/content/.obsidian/core-plugins.json
vendored
Normal file
@@ -0,0 +1,33 @@
|
||||
{
|
||||
"file-explorer": true,
|
||||
"global-search": true,
|
||||
"switcher": true,
|
||||
"graph": true,
|
||||
"backlink": true,
|
||||
"canvas": true,
|
||||
"outgoing-link": true,
|
||||
"tag-pane": true,
|
||||
"footnotes": false,
|
||||
"properties": false,
|
||||
"page-preview": true,
|
||||
"daily-notes": true,
|
||||
"templates": true,
|
||||
"note-composer": true,
|
||||
"command-palette": true,
|
||||
"slash-command": false,
|
||||
"editor-status": true,
|
||||
"bookmarks": true,
|
||||
"markdown-importer": false,
|
||||
"zk-prefixer": false,
|
||||
"random-note": false,
|
||||
"outline": true,
|
||||
"word-count": true,
|
||||
"slides": false,
|
||||
"audio-recorder": false,
|
||||
"workspaces": false,
|
||||
"file-recovery": true,
|
||||
"publish": false,
|
||||
"sync": true,
|
||||
"bases": true,
|
||||
"webviewer": false
|
||||
}
|
||||
10
src/content/.obsidian/plugins/obsidian-paste-image-rename/data.json
vendored
Normal file
10
src/content/.obsidian/plugins/obsidian-paste-image-rename/data.json
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
{
|
||||
"imageNamePattern": "{{fileName}}",
|
||||
"dupNumberAtStart": false,
|
||||
"dupNumberDelimiter": "-",
|
||||
"dupNumberAlways": false,
|
||||
"autoRename": true,
|
||||
"handleAllAttachments": false,
|
||||
"excludeExtensionPattern": "",
|
||||
"disableRenameNotice": false
|
||||
}
|
||||
944
src/content/.obsidian/plugins/obsidian-paste-image-rename/main.js
vendored
Normal file
944
src/content/.obsidian/plugins/obsidian-paste-image-rename/main.js
vendored
Normal file
@@ -0,0 +1,944 @@
|
||||
/* THIS IS A GENERATED/BUNDLED FILE BY ESBUILD */
|
||||
var __defProp = Object.defineProperty;
|
||||
var __defProps = Object.defineProperties;
|
||||
var __getOwnPropDesc = Object.getOwnPropertyDescriptor;
|
||||
var __getOwnPropDescs = Object.getOwnPropertyDescriptors;
|
||||
var __getOwnPropNames = Object.getOwnPropertyNames;
|
||||
var __getOwnPropSymbols = Object.getOwnPropertySymbols;
|
||||
var __hasOwnProp = Object.prototype.hasOwnProperty;
|
||||
var __propIsEnum = Object.prototype.propertyIsEnumerable;
|
||||
var __defNormalProp = (obj, key, value) => key in obj ? __defProp(obj, key, { enumerable: true, configurable: true, writable: true, value }) : obj[key] = value;
|
||||
var __spreadValues = (a, b) => {
|
||||
for (var prop in b || (b = {}))
|
||||
if (__hasOwnProp.call(b, prop))
|
||||
__defNormalProp(a, prop, b[prop]);
|
||||
if (__getOwnPropSymbols)
|
||||
for (var prop of __getOwnPropSymbols(b)) {
|
||||
if (__propIsEnum.call(b, prop))
|
||||
__defNormalProp(a, prop, b[prop]);
|
||||
}
|
||||
return a;
|
||||
};
|
||||
var __spreadProps = (a, b) => __defProps(a, __getOwnPropDescs(b));
|
||||
var __commonJS = (cb, mod) => function __require() {
|
||||
return mod || (0, cb[__getOwnPropNames(cb)[0]])((mod = { exports: {} }).exports, mod), mod.exports;
|
||||
};
|
||||
var __export = (target, all) => {
|
||||
for (var name in all)
|
||||
__defProp(target, name, { get: all[name], enumerable: true });
|
||||
};
|
||||
var __copyProps = (to, from, except, desc) => {
|
||||
if (from && typeof from === "object" || typeof from === "function") {
|
||||
for (let key of __getOwnPropNames(from))
|
||||
if (!__hasOwnProp.call(to, key) && key !== except)
|
||||
__defProp(to, key, { get: () => from[key], enumerable: !(desc = __getOwnPropDesc(from, key)) || desc.enumerable });
|
||||
}
|
||||
return to;
|
||||
};
|
||||
var __toCommonJS = (mod) => __copyProps(__defProp({}, "__esModule", { value: true }), mod);
|
||||
var __async = (__this, __arguments, generator) => {
|
||||
return new Promise((resolve, reject) => {
|
||||
var fulfilled = (value) => {
|
||||
try {
|
||||
step(generator.next(value));
|
||||
} catch (e) {
|
||||
reject(e);
|
||||
}
|
||||
};
|
||||
var rejected = (value) => {
|
||||
try {
|
||||
step(generator.throw(value));
|
||||
} catch (e) {
|
||||
reject(e);
|
||||
}
|
||||
};
|
||||
var step = (x) => x.done ? resolve(x.value) : Promise.resolve(x.value).then(fulfilled, rejected);
|
||||
step((generator = generator.apply(__this, __arguments)).next());
|
||||
});
|
||||
};
|
||||
|
||||
// package.json
|
||||
var require_package = __commonJS({
|
||||
"package.json"(exports, module2) {
|
||||
module2.exports = {
|
||||
name: "obsidian-paste-image-rename",
|
||||
version: "1.6.1",
|
||||
main: "main.js",
|
||||
scripts: {
|
||||
start: "node esbuild.config.mjs",
|
||||
build: "tsc -noEmit -skipLibCheck && BUILD_ENV=production node esbuild.config.mjs && cp manifest.json build",
|
||||
version: "node version-bump.mjs && git add manifest.json versions.json",
|
||||
release: "npm run build && gh release create ${npm_package_version} build/*"
|
||||
},
|
||||
keywords: [],
|
||||
author: "Reorx",
|
||||
license: "MIT",
|
||||
devDependencies: {
|
||||
"@types/node": "^18.11.18",
|
||||
"@typescript-eslint/eslint-plugin": "^5.49.0",
|
||||
"@typescript-eslint/parser": "^5.49.0",
|
||||
"builtin-modules": "^3.3.0",
|
||||
esbuild: "0.16.17",
|
||||
obsidian: "^1.1.1",
|
||||
tslib: "2.5.0",
|
||||
typescript: "4.9.4"
|
||||
},
|
||||
dependencies: {
|
||||
"cash-dom": "^8.1.2"
|
||||
}
|
||||
};
|
||||
}
|
||||
});
|
||||
|
||||
// src/main.ts
|
||||
var main_exports = {};
|
||||
__export(main_exports, {
|
||||
default: () => PasteImageRenamePlugin
|
||||
});
|
||||
module.exports = __toCommonJS(main_exports);
|
||||
var import_obsidian2 = require("obsidian");
|
||||
|
||||
// src/batch.ts
|
||||
var import_obsidian = require("obsidian");
|
||||
|
||||
// src/utils.ts
|
||||
var DEBUG = false;
|
||||
if (DEBUG)
|
||||
console.log("DEBUG is enabled");
|
||||
function debugLog(...args) {
|
||||
if (DEBUG) {
|
||||
console.log(new Date().toISOString().slice(11, 23), ...args);
|
||||
}
|
||||
}
|
||||
function createElementTree(rootEl, opts) {
|
||||
const result = {
|
||||
el: rootEl.createEl(opts.tag, opts),
|
||||
children: []
|
||||
};
|
||||
const children = opts.children || [];
|
||||
for (const child of children) {
|
||||
result.children.push(createElementTree(result.el, child));
|
||||
}
|
||||
return result;
|
||||
}
|
||||
var path = {
|
||||
// Credit: @creationix/path.js
|
||||
join(...partSegments) {
|
||||
let parts = [];
|
||||
for (let i = 0, l = partSegments.length; i < l; i++) {
|
||||
parts = parts.concat(partSegments[i].split("/"));
|
||||
}
|
||||
const newParts = [];
|
||||
for (let i = 0, l = parts.length; i < l; i++) {
|
||||
const part = parts[i];
|
||||
if (!part || part === ".")
|
||||
continue;
|
||||
else
|
||||
newParts.push(part);
|
||||
}
|
||||
if (parts[0] === "")
|
||||
newParts.unshift("");
|
||||
return newParts.join("/");
|
||||
},
|
||||
// returns the last part of a path, e.g. 'foo.jpg'
|
||||
basename(fullpath) {
|
||||
const sp = fullpath.split("/");
|
||||
return sp[sp.length - 1];
|
||||
},
|
||||
// return extension without dot, e.g. 'jpg'
|
||||
extension(fullpath) {
|
||||
const positions = [...fullpath.matchAll(new RegExp("\\.", "gi"))].map((a) => a.index);
|
||||
return fullpath.slice(positions[positions.length - 1] + 1);
|
||||
}
|
||||
};
|
||||
var filenameNotAllowedChars = /[^\p{L}0-9~`!@$&*()\-_=+{};'",<.>? ]/ug;
|
||||
var sanitizer = {
|
||||
filename(s) {
|
||||
return s.replace(filenameNotAllowedChars, "").trim();
|
||||
},
|
||||
delimiter(s) {
|
||||
s = this.filename(s);
|
||||
if (!s)
|
||||
s = "-";
|
||||
return s;
|
||||
}
|
||||
};
|
||||
function escapeRegExp(s) {
|
||||
return s.replace(/[.*+?^${}()|[\]\\]/g, "\\$&");
|
||||
}
|
||||
function lockInputMethodComposition(el) {
|
||||
const state = {
|
||||
lock: false
|
||||
};
|
||||
el.addEventListener("compositionstart", () => {
|
||||
state.lock = true;
|
||||
});
|
||||
el.addEventListener("compositionend", () => {
|
||||
state.lock = false;
|
||||
});
|
||||
return state;
|
||||
}
|
||||
|
||||
// src/batch.ts
|
||||
var ImageBatchRenameModal = class extends import_obsidian.Modal {
|
||||
constructor(app, activeFile, renameFunc, onClose) {
|
||||
super(app);
|
||||
this.activeFile = activeFile;
|
||||
this.renameFunc = renameFunc;
|
||||
this.onCloseExtra = onClose;
|
||||
this.state = {
|
||||
namePattern: "",
|
||||
extPattern: "",
|
||||
nameReplace: "",
|
||||
renameTasks: []
|
||||
};
|
||||
}
|
||||
onOpen() {
|
||||
this.containerEl.addClass("image-rename-modal");
|
||||
const { contentEl, titleEl } = this;
|
||||
titleEl.setText("Batch rename embeded files");
|
||||
const namePatternSetting = new import_obsidian.Setting(contentEl).setName("Name pattern").setDesc("Please input the name pattern to match files (regex)").addText((text) => text.setValue(this.state.namePattern).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
this.state.namePattern = value;
|
||||
})
|
||||
));
|
||||
const npInputEl = namePatternSetting.controlEl.children[0];
|
||||
npInputEl.focus();
|
||||
const npInputState = lockInputMethodComposition(npInputEl);
|
||||
npInputEl.addEventListener("keydown", (e) => __async(this, null, function* () {
|
||||
if (e.key === "Enter" && !npInputState.lock) {
|
||||
e.preventDefault();
|
||||
if (!this.state.namePattern) {
|
||||
errorEl.innerText = 'Error: "Name pattern" could not be empty';
|
||||
errorEl.style.display = "block";
|
||||
return;
|
||||
}
|
||||
this.matchImageNames(tbodyEl);
|
||||
}
|
||||
}));
|
||||
const extPatternSetting = new import_obsidian.Setting(contentEl).setName("Extension pattern").setDesc("Please input the extension pattern to match files (regex)").addText((text) => text.setValue(this.state.extPattern).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
this.state.extPattern = value;
|
||||
})
|
||||
));
|
||||
const extInputEl = extPatternSetting.controlEl.children[0];
|
||||
extInputEl.addEventListener("keydown", (e) => __async(this, null, function* () {
|
||||
if (e.key === "Enter") {
|
||||
e.preventDefault();
|
||||
this.matchImageNames(tbodyEl);
|
||||
}
|
||||
}));
|
||||
const nameReplaceSetting = new import_obsidian.Setting(contentEl).setName("Name replace").setDesc("Please input the string to replace the matched name (use $1, $2 for regex groups)").addText((text) => text.setValue(this.state.nameReplace).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
this.state.nameReplace = value;
|
||||
})
|
||||
));
|
||||
const nrInputEl = nameReplaceSetting.controlEl.children[0];
|
||||
const nrInputState = lockInputMethodComposition(nrInputEl);
|
||||
nrInputEl.addEventListener("keydown", (e) => __async(this, null, function* () {
|
||||
if (e.key === "Enter" && !nrInputState.lock) {
|
||||
e.preventDefault();
|
||||
this.matchImageNames(tbodyEl);
|
||||
}
|
||||
}));
|
||||
const matchedContainer = contentEl.createDiv({
|
||||
cls: "matched-container"
|
||||
});
|
||||
const tableET = createElementTree(matchedContainer, {
|
||||
tag: "table",
|
||||
children: [
|
||||
{
|
||||
tag: "thead",
|
||||
children: [
|
||||
{
|
||||
tag: "tr",
|
||||
children: [
|
||||
{
|
||||
tag: "td",
|
||||
text: "Original path"
|
||||
},
|
||||
{
|
||||
tag: "td",
|
||||
text: "Renamed Name"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
tag: "tbody"
|
||||
}
|
||||
]
|
||||
});
|
||||
const tbodyEl = tableET.children[1].el;
|
||||
const errorEl = contentEl.createDiv({
|
||||
cls: "error",
|
||||
attr: {
|
||||
style: "display: none;"
|
||||
}
|
||||
});
|
||||
new import_obsidian.Setting(contentEl).addButton((button) => {
|
||||
button.setButtonText("Rename all").setClass("mod-cta").onClick(() => {
|
||||
new ConfirmModal(
|
||||
this.app,
|
||||
"Confirm rename all",
|
||||
`Are you sure? This will rename all the ${this.state.renameTasks.length} images matched the pattern.`,
|
||||
() => {
|
||||
this.renameAll();
|
||||
this.close();
|
||||
}
|
||||
).open();
|
||||
});
|
||||
}).addButton((button) => {
|
||||
button.setButtonText("Cancel").onClick(() => {
|
||||
this.close();
|
||||
});
|
||||
});
|
||||
}
|
||||
onClose() {
|
||||
const { contentEl } = this;
|
||||
contentEl.empty();
|
||||
this.onCloseExtra();
|
||||
}
|
||||
renameAll() {
|
||||
return __async(this, null, function* () {
|
||||
debugLog("renameAll", this.state);
|
||||
for (const task of this.state.renameTasks) {
|
||||
yield this.renameFunc(task.file, task.name);
|
||||
}
|
||||
});
|
||||
}
|
||||
matchImageNames(tbodyEl) {
|
||||
const { state } = this;
|
||||
const renameTasks = [];
|
||||
tbodyEl.empty();
|
||||
const fileCache = this.app.metadataCache.getFileCache(this.activeFile);
|
||||
if (!fileCache || !fileCache.embeds)
|
||||
return;
|
||||
const namePatternRegex = new RegExp(state.namePattern, "g");
|
||||
const extPatternRegex = new RegExp(state.extPattern);
|
||||
fileCache.embeds.forEach((embed) => {
|
||||
const file = this.app.metadataCache.getFirstLinkpathDest(embed.link, this.activeFile.path);
|
||||
if (!file) {
|
||||
console.warn("file not found", embed.link);
|
||||
return;
|
||||
}
|
||||
if (state.extPattern) {
|
||||
const m0 = extPatternRegex.exec(file.extension);
|
||||
if (!m0)
|
||||
return;
|
||||
}
|
||||
const stem = file.basename;
|
||||
namePatternRegex.lastIndex = 0;
|
||||
const m1 = namePatternRegex.exec(stem);
|
||||
if (!m1)
|
||||
return;
|
||||
let renamedName = file.name;
|
||||
if (state.nameReplace) {
|
||||
namePatternRegex.lastIndex = 0;
|
||||
renamedName = stem.replace(namePatternRegex, state.nameReplace);
|
||||
renamedName = `${renamedName}.${file.extension}`;
|
||||
}
|
||||
renameTasks.push({
|
||||
file,
|
||||
name: renamedName
|
||||
});
|
||||
createElementTree(tbodyEl, {
|
||||
tag: "tr",
|
||||
children: [
|
||||
{
|
||||
tag: "td",
|
||||
children: [
|
||||
{
|
||||
tag: "span",
|
||||
text: file.name
|
||||
},
|
||||
{
|
||||
tag: "div",
|
||||
text: file.path,
|
||||
attr: {
|
||||
class: "file-path"
|
||||
}
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
tag: "td",
|
||||
children: [
|
||||
{
|
||||
tag: "span",
|
||||
text: renamedName
|
||||
},
|
||||
{
|
||||
tag: "div",
|
||||
text: path.join(file.parent.path, renamedName),
|
||||
attr: {
|
||||
class: "file-path"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
});
|
||||
});
|
||||
debugLog("new renameTasks", renameTasks);
|
||||
state.renameTasks = renameTasks;
|
||||
}
|
||||
};
|
||||
var ConfirmModal = class extends import_obsidian.Modal {
|
||||
constructor(app, title, message, onConfirm) {
|
||||
super(app);
|
||||
this.title = title;
|
||||
this.message = message;
|
||||
this.onConfirm = onConfirm;
|
||||
}
|
||||
onOpen() {
|
||||
const { contentEl, titleEl } = this;
|
||||
titleEl.setText(this.title);
|
||||
contentEl.createEl("p", {
|
||||
text: this.message
|
||||
});
|
||||
new import_obsidian.Setting(contentEl).addButton((button) => {
|
||||
button.setButtonText("Yes").setClass("mod-warning").onClick(() => {
|
||||
this.onConfirm();
|
||||
this.close();
|
||||
});
|
||||
}).addButton((button) => {
|
||||
button.setButtonText("No").onClick(() => {
|
||||
this.close();
|
||||
});
|
||||
});
|
||||
}
|
||||
};
|
||||
|
||||
// src/template.ts
|
||||
var dateTmplRegex = /{{DATE:([^}]+)}}/gm;
|
||||
var frontmatterTmplRegex = /{{frontmatter:([^}]+)}}/gm;
|
||||
var replaceDateVar = (s, date) => {
|
||||
const m = dateTmplRegex.exec(s);
|
||||
if (!m)
|
||||
return s;
|
||||
return s.replace(m[0], date.format(m[1]));
|
||||
};
|
||||
var replaceFrontmatterVar = (s, frontmatter) => {
|
||||
if (!frontmatter)
|
||||
return s;
|
||||
const m = frontmatterTmplRegex.exec(s);
|
||||
if (!m)
|
||||
return s;
|
||||
return s.replace(m[0], frontmatter[m[1]] || "");
|
||||
};
|
||||
var renderTemplate = (tmpl, data, frontmatter) => {
|
||||
const now = window.moment();
|
||||
let text = tmpl;
|
||||
let newtext;
|
||||
while ((newtext = replaceDateVar(text, now)) != text) {
|
||||
text = newtext;
|
||||
}
|
||||
while ((newtext = replaceFrontmatterVar(text, frontmatter)) != text) {
|
||||
text = newtext;
|
||||
}
|
||||
text = text.replace(/{{imageNameKey}}/gm, data.imageNameKey).replace(/{{fileName}}/gm, data.fileName).replace(/{{dirName}}/gm, data.dirName).replace(/{{firstHeading}}/gm, data.firstHeading);
|
||||
return text;
|
||||
};
|
||||
|
||||
// src/main.ts
|
||||
var DEFAULT_SETTINGS = {
|
||||
imageNamePattern: "{{fileName}}",
|
||||
dupNumberAtStart: false,
|
||||
dupNumberDelimiter: "-",
|
||||
dupNumberAlways: false,
|
||||
autoRename: false,
|
||||
handleAllAttachments: false,
|
||||
excludeExtensionPattern: "",
|
||||
disableRenameNotice: false
|
||||
};
|
||||
var PASTED_IMAGE_PREFIX = "Pasted image ";
|
||||
var PasteImageRenamePlugin = class extends import_obsidian2.Plugin {
|
||||
constructor() {
|
||||
super(...arguments);
|
||||
this.modals = [];
|
||||
}
|
||||
onload() {
|
||||
return __async(this, null, function* () {
|
||||
const pkg = require_package();
|
||||
console.log(`Plugin loading: ${pkg.name} ${pkg.version} BUILD_ENV=${"production"}`);
|
||||
yield this.loadSettings();
|
||||
this.registerEvent(
|
||||
this.app.vault.on("create", (file) => {
|
||||
if (!(file instanceof import_obsidian2.TFile))
|
||||
return;
|
||||
const timeGapMs = new Date().getTime() - file.stat.ctime;
|
||||
if (timeGapMs > 1e3)
|
||||
return;
|
||||
if (isMarkdownFile(file))
|
||||
return;
|
||||
if (isPastedImage(file)) {
|
||||
debugLog("pasted image created", file);
|
||||
this.startRenameProcess(file, this.settings.autoRename);
|
||||
} else {
|
||||
if (this.settings.handleAllAttachments) {
|
||||
debugLog("handleAllAttachments for file", file);
|
||||
if (this.testExcludeExtension(file)) {
|
||||
debugLog("excluded file by ext", file);
|
||||
return;
|
||||
}
|
||||
this.startRenameProcess(file, this.settings.autoRename);
|
||||
}
|
||||
}
|
||||
})
|
||||
);
|
||||
const startBatchRenameProcess = () => {
|
||||
this.openBatchRenameModal();
|
||||
};
|
||||
this.addCommand({
|
||||
id: "batch-rename-embeded-files",
|
||||
name: "Batch rename embeded files (in the current file)",
|
||||
callback: startBatchRenameProcess
|
||||
});
|
||||
if (DEBUG) {
|
||||
this.addRibbonIcon("wand-glyph", "Batch rename embeded files", startBatchRenameProcess);
|
||||
}
|
||||
const batchRenameAllImages = () => {
|
||||
this.batchRenameAllImages();
|
||||
};
|
||||
this.addCommand({
|
||||
id: "batch-rename-all-images",
|
||||
name: "Batch rename all images instantly (in the current file)",
|
||||
callback: batchRenameAllImages
|
||||
});
|
||||
if (DEBUG) {
|
||||
this.addRibbonIcon("wand-glyph", "Batch rename all images instantly (in the current file)", batchRenameAllImages);
|
||||
}
|
||||
this.addSettingTab(new SettingTab(this.app, this));
|
||||
});
|
||||
}
|
||||
startRenameProcess(file, autoRename = false) {
|
||||
return __async(this, null, function* () {
|
||||
const activeFile = this.getActiveFile();
|
||||
if (!activeFile) {
|
||||
new import_obsidian2.Notice("Error: No active file found.");
|
||||
return;
|
||||
}
|
||||
const { stem, newName, isMeaningful } = this.generateNewName(file, activeFile);
|
||||
debugLog("generated newName:", newName, isMeaningful);
|
||||
if (!isMeaningful || !autoRename) {
|
||||
this.openRenameModal(file, isMeaningful ? stem : "", activeFile.path);
|
||||
return;
|
||||
}
|
||||
this.renameFile(file, newName, activeFile.path, true);
|
||||
});
|
||||
}
|
||||
renameFile(file, inputNewName, sourcePath, replaceCurrentLine) {
|
||||
return __async(this, null, function* () {
|
||||
const { name: newName } = yield this.deduplicateNewName(inputNewName, file);
|
||||
debugLog("deduplicated newName:", newName);
|
||||
const originName = file.name;
|
||||
const linkText = this.app.fileManager.generateMarkdownLink(file, sourcePath);
|
||||
const newPath = path.join(file.parent.path, newName);
|
||||
try {
|
||||
yield this.app.fileManager.renameFile(file, newPath);
|
||||
} catch (err) {
|
||||
new import_obsidian2.Notice(`Failed to rename ${newName}: ${err}`);
|
||||
throw err;
|
||||
}
|
||||
if (!replaceCurrentLine) {
|
||||
return;
|
||||
}
|
||||
const newLinkText = this.app.fileManager.generateMarkdownLink(file, sourcePath);
|
||||
debugLog("replace text", linkText, newLinkText);
|
||||
const editor = this.getActiveEditor();
|
||||
if (!editor) {
|
||||
new import_obsidian2.Notice(`Failed to rename ${newName}: no active editor`);
|
||||
return;
|
||||
}
|
||||
const cursor = editor.getCursor();
|
||||
const line = editor.getLine(cursor.line);
|
||||
const replacedLine = line.replace(linkText, newLinkText);
|
||||
debugLog("current line -> replaced line", line, replacedLine);
|
||||
editor.transaction({
|
||||
changes: [
|
||||
{
|
||||
from: __spreadProps(__spreadValues({}, cursor), { ch: 0 }),
|
||||
to: __spreadProps(__spreadValues({}, cursor), { ch: line.length }),
|
||||
text: replacedLine
|
||||
}
|
||||
]
|
||||
});
|
||||
if (!this.settings.disableRenameNotice) {
|
||||
new import_obsidian2.Notice(`Renamed ${originName} to ${newName}`);
|
||||
}
|
||||
});
|
||||
}
|
||||
openRenameModal(file, newName, sourcePath) {
|
||||
const modal = new ImageRenameModal(
|
||||
this.app,
|
||||
file,
|
||||
newName,
|
||||
(confirmedName) => {
|
||||
debugLog("confirmedName:", confirmedName);
|
||||
this.renameFile(file, confirmedName, sourcePath, true);
|
||||
},
|
||||
() => {
|
||||
this.modals.splice(this.modals.indexOf(modal), 1);
|
||||
}
|
||||
);
|
||||
this.modals.push(modal);
|
||||
modal.open();
|
||||
debugLog("modals count", this.modals.length);
|
||||
}
|
||||
openBatchRenameModal() {
|
||||
const activeFile = this.getActiveFile();
|
||||
const modal = new ImageBatchRenameModal(
|
||||
this.app,
|
||||
activeFile,
|
||||
(file, name) => __async(this, null, function* () {
|
||||
yield this.renameFile(file, name, activeFile.path);
|
||||
}),
|
||||
() => {
|
||||
this.modals.splice(this.modals.indexOf(modal), 1);
|
||||
}
|
||||
);
|
||||
this.modals.push(modal);
|
||||
modal.open();
|
||||
}
|
||||
batchRenameAllImages() {
|
||||
return __async(this, null, function* () {
|
||||
const activeFile = this.getActiveFile();
|
||||
const fileCache = this.app.metadataCache.getFileCache(activeFile);
|
||||
if (!fileCache || !fileCache.embeds)
|
||||
return;
|
||||
const extPatternRegex = /jpe?g|png|gif|tiff|webp/i;
|
||||
for (const embed of fileCache.embeds) {
|
||||
const file = this.app.metadataCache.getFirstLinkpathDest(embed.link, activeFile.path);
|
||||
if (!file) {
|
||||
console.warn("file not found", embed.link);
|
||||
return;
|
||||
}
|
||||
const m0 = extPatternRegex.exec(file.extension);
|
||||
if (!m0)
|
||||
return;
|
||||
const { newName, isMeaningful } = this.generateNewName(file, activeFile);
|
||||
debugLog("generated newName:", newName, isMeaningful);
|
||||
if (!isMeaningful) {
|
||||
new import_obsidian2.Notice("Failed to batch rename images: the generated name is not meaningful");
|
||||
break;
|
||||
}
|
||||
yield this.renameFile(file, newName, activeFile.path, false);
|
||||
}
|
||||
});
|
||||
}
|
||||
// returns a new name for the input file, with extension
|
||||
generateNewName(file, activeFile) {
|
||||
let imageNameKey = "";
|
||||
let firstHeading = "";
|
||||
let frontmatter;
|
||||
const fileCache = this.app.metadataCache.getFileCache(activeFile);
|
||||
if (fileCache) {
|
||||
debugLog("frontmatter", fileCache.frontmatter);
|
||||
frontmatter = fileCache.frontmatter;
|
||||
imageNameKey = (frontmatter == null ? void 0 : frontmatter.imageNameKey) || "";
|
||||
firstHeading = getFirstHeading(fileCache.headings);
|
||||
} else {
|
||||
console.warn("could not get file cache from active file", activeFile.name);
|
||||
}
|
||||
const stem = renderTemplate(
|
||||
this.settings.imageNamePattern,
|
||||
{
|
||||
imageNameKey,
|
||||
fileName: activeFile.basename,
|
||||
dirName: activeFile.parent.name,
|
||||
firstHeading
|
||||
},
|
||||
frontmatter
|
||||
);
|
||||
const meaninglessRegex = new RegExp(`[${this.settings.dupNumberDelimiter}\\s]`, "gm");
|
||||
return {
|
||||
stem,
|
||||
newName: stem + "." + file.extension,
|
||||
isMeaningful: stem.replace(meaninglessRegex, "") !== ""
|
||||
};
|
||||
}
|
||||
// newName: foo.ext
|
||||
deduplicateNewName(newName, file) {
|
||||
return __async(this, null, function* () {
|
||||
const dir = file.parent.path;
|
||||
const listed = yield this.app.vault.adapter.list(dir);
|
||||
debugLog("sibling files", listed);
|
||||
const newNameExt = path.extension(newName), newNameStem = newName.slice(0, newName.length - newNameExt.length - 1), newNameStemEscaped = escapeRegExp(newNameStem), delimiter = this.settings.dupNumberDelimiter, delimiterEscaped = escapeRegExp(delimiter);
|
||||
let dupNameRegex;
|
||||
if (this.settings.dupNumberAtStart) {
|
||||
dupNameRegex = new RegExp(
|
||||
`^(?<number>\\d+)${delimiterEscaped}(?<name>${newNameStemEscaped})\\.${newNameExt}$`
|
||||
);
|
||||
} else {
|
||||
dupNameRegex = new RegExp(
|
||||
`^(?<name>${newNameStemEscaped})${delimiterEscaped}(?<number>\\d+)\\.${newNameExt}$`
|
||||
);
|
||||
}
|
||||
debugLog("dupNameRegex", dupNameRegex);
|
||||
const dupNameNumbers = [];
|
||||
let isNewNameExist = false;
|
||||
for (let sibling of listed.files) {
|
||||
sibling = path.basename(sibling);
|
||||
if (sibling == newName) {
|
||||
isNewNameExist = true;
|
||||
continue;
|
||||
}
|
||||
const m = dupNameRegex.exec(sibling);
|
||||
if (!m)
|
||||
continue;
|
||||
dupNameNumbers.push(parseInt(m.groups.number));
|
||||
}
|
||||
if (isNewNameExist || this.settings.dupNumberAlways) {
|
||||
const newNumber = dupNameNumbers.length > 0 ? Math.max(...dupNameNumbers) + 1 : 1;
|
||||
if (this.settings.dupNumberAtStart) {
|
||||
newName = `${newNumber}${delimiter}${newNameStem}.${newNameExt}`;
|
||||
} else {
|
||||
newName = `${newNameStem}${delimiter}${newNumber}.${newNameExt}`;
|
||||
}
|
||||
}
|
||||
return {
|
||||
name: newName,
|
||||
stem: newName.slice(0, newName.length - newNameExt.length - 1),
|
||||
extension: newNameExt
|
||||
};
|
||||
});
|
||||
}
|
||||
getActiveFile() {
|
||||
const view = this.app.workspace.getActiveViewOfType(import_obsidian2.MarkdownView);
|
||||
const file = view == null ? void 0 : view.file;
|
||||
debugLog("active file", file == null ? void 0 : file.path);
|
||||
return file;
|
||||
}
|
||||
getActiveEditor() {
|
||||
const view = this.app.workspace.getActiveViewOfType(import_obsidian2.MarkdownView);
|
||||
return view == null ? void 0 : view.editor;
|
||||
}
|
||||
onunload() {
|
||||
this.modals.map((modal) => modal.close());
|
||||
}
|
||||
testExcludeExtension(file) {
|
||||
const pattern = this.settings.excludeExtensionPattern;
|
||||
if (!pattern)
|
||||
return false;
|
||||
return new RegExp(pattern).test(file.extension);
|
||||
}
|
||||
loadSettings() {
|
||||
return __async(this, null, function* () {
|
||||
this.settings = Object.assign({}, DEFAULT_SETTINGS, yield this.loadData());
|
||||
});
|
||||
}
|
||||
saveSettings() {
|
||||
return __async(this, null, function* () {
|
||||
yield this.saveData(this.settings);
|
||||
});
|
||||
}
|
||||
};
|
||||
function getFirstHeading(headings) {
|
||||
if (headings && headings.length > 0) {
|
||||
for (const heading of headings) {
|
||||
if (heading.level === 1) {
|
||||
return heading.heading;
|
||||
}
|
||||
}
|
||||
}
|
||||
return "";
|
||||
}
|
||||
function isPastedImage(file) {
|
||||
if (file instanceof import_obsidian2.TFile) {
|
||||
if (file.name.startsWith(PASTED_IMAGE_PREFIX)) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
function isMarkdownFile(file) {
|
||||
if (file instanceof import_obsidian2.TFile) {
|
||||
if (file.extension === "md") {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
var ImageRenameModal = class extends import_obsidian2.Modal {
|
||||
constructor(app, src, stem, renameFunc, onClose) {
|
||||
super(app);
|
||||
this.src = src;
|
||||
this.stem = stem;
|
||||
this.renameFunc = renameFunc;
|
||||
this.onCloseExtra = onClose;
|
||||
}
|
||||
onOpen() {
|
||||
this.containerEl.addClass("image-rename-modal");
|
||||
const { contentEl, titleEl } = this;
|
||||
titleEl.setText("Rename image");
|
||||
const imageContainer = contentEl.createDiv({
|
||||
cls: "image-container"
|
||||
});
|
||||
imageContainer.createEl("img", {
|
||||
attr: {
|
||||
src: this.app.vault.getResourcePath(this.src)
|
||||
}
|
||||
});
|
||||
let stem = this.stem;
|
||||
const ext = this.src.extension;
|
||||
const getNewName = (stem2) => stem2 + "." + ext;
|
||||
const getNewPath = (stem2) => path.join(this.src.parent.path, getNewName(stem2));
|
||||
const infoET = createElementTree(contentEl, {
|
||||
tag: "ul",
|
||||
cls: "info",
|
||||
children: [
|
||||
{
|
||||
tag: "li",
|
||||
children: [
|
||||
{
|
||||
tag: "span",
|
||||
text: "Origin path"
|
||||
},
|
||||
{
|
||||
tag: "span",
|
||||
text: this.src.path
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
tag: "li",
|
||||
children: [
|
||||
{
|
||||
tag: "span",
|
||||
text: "New path"
|
||||
},
|
||||
{
|
||||
tag: "span",
|
||||
text: getNewPath(stem)
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
});
|
||||
const doRename = () => __async(this, null, function* () {
|
||||
debugLog("doRename", `stem=${stem}`);
|
||||
this.renameFunc(getNewName(stem));
|
||||
});
|
||||
const nameSetting = new import_obsidian2.Setting(contentEl).setName("New name").setDesc("Please input the new name for the image (without extension)").addText((text) => text.setValue(stem).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
stem = sanitizer.filename(value);
|
||||
infoET.children[1].children[1].el.innerText = getNewPath(stem);
|
||||
})
|
||||
));
|
||||
const nameInputEl = nameSetting.controlEl.children[0];
|
||||
nameInputEl.focus();
|
||||
const nameInputState = lockInputMethodComposition(nameInputEl);
|
||||
nameInputEl.addEventListener("keydown", (e) => __async(this, null, function* () {
|
||||
if (e.key === "Enter" && !nameInputState.lock) {
|
||||
e.preventDefault();
|
||||
if (!stem) {
|
||||
errorEl.innerText = 'Error: "New name" could not be empty';
|
||||
errorEl.style.display = "block";
|
||||
return;
|
||||
}
|
||||
doRename();
|
||||
this.close();
|
||||
}
|
||||
}));
|
||||
const errorEl = contentEl.createDiv({
|
||||
cls: "error",
|
||||
attr: {
|
||||
style: "display: none;"
|
||||
}
|
||||
});
|
||||
new import_obsidian2.Setting(contentEl).addButton((button) => {
|
||||
button.setButtonText("Rename").onClick(() => {
|
||||
doRename();
|
||||
this.close();
|
||||
});
|
||||
}).addButton((button) => {
|
||||
button.setButtonText("Cancel").onClick(() => {
|
||||
this.close();
|
||||
});
|
||||
});
|
||||
}
|
||||
onClose() {
|
||||
const { contentEl } = this;
|
||||
contentEl.empty();
|
||||
this.onCloseExtra();
|
||||
}
|
||||
};
|
||||
var imageNamePatternDesc = `
|
||||
The pattern indicates how the new name should be generated.
|
||||
|
||||
Available variables:
|
||||
- {{fileName}}: name of the active file, without ".md" extension.
|
||||
- {{imageNameKey}}: this variable is read from the markdown file's frontmatter, from the same key "imageNameKey".
|
||||
- {{DATE:$FORMAT}}: use "$FORMAT" to format the current date, "$FORMAT" must be a Moment.js format string, e.g. {{DATE:YYYY-MM-DD}}.
|
||||
|
||||
Here are some examples from pattern to image names (repeat in sequence), variables: fileName = "My note", imageNameKey = "foo":
|
||||
- {{fileName}}: My note, My note-1, My note-2
|
||||
- {{imageNameKey}}: foo, foo-1, foo-2
|
||||
- {{imageNameKey}}-{{DATE:YYYYMMDD}}: foo-20220408, foo-20220408-1, foo-20220408-2
|
||||
`;
|
||||
var SettingTab = class extends import_obsidian2.PluginSettingTab {
|
||||
constructor(app, plugin) {
|
||||
super(app, plugin);
|
||||
this.plugin = plugin;
|
||||
}
|
||||
display() {
|
||||
const { containerEl } = this;
|
||||
containerEl.empty();
|
||||
new import_obsidian2.Setting(containerEl).setName("Image name pattern").setDesc(imageNamePatternDesc).setClass("long-description-setting-item").addText((text) => text.setPlaceholder("{{imageNameKey}}").setValue(this.plugin.settings.imageNamePattern).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
this.plugin.settings.imageNamePattern = value;
|
||||
yield this.plugin.saveSettings();
|
||||
})
|
||||
));
|
||||
new import_obsidian2.Setting(containerEl).setName("Duplicate number at start (or end)").setDesc(`If enabled, duplicate number will be added at the start as prefix for the image name, otherwise it will be added at the end as suffix for the image name.`).addToggle((toggle) => toggle.setValue(this.plugin.settings.dupNumberAtStart).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
this.plugin.settings.dupNumberAtStart = value;
|
||||
yield this.plugin.saveSettings();
|
||||
})
|
||||
));
|
||||
new import_obsidian2.Setting(containerEl).setName("Duplicate number delimiter").setDesc(`The delimiter to generate the number prefix/suffix for duplicated names. For example, if the value is "-", the suffix will be like "-1", "-2", "-3", and the prefix will be like "1-", "2-", "3-". Only characters that are valid in file names are allowed.`).addText((text) => text.setValue(this.plugin.settings.dupNumberDelimiter).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
this.plugin.settings.dupNumberDelimiter = sanitizer.delimiter(value);
|
||||
yield this.plugin.saveSettings();
|
||||
})
|
||||
));
|
||||
new import_obsidian2.Setting(containerEl).setName("Always add duplicate number").setDesc(`If enabled, duplicate number will always be added to the image name. Otherwise, it will only be added when the name is duplicated.`).addToggle((toggle) => toggle.setValue(this.plugin.settings.dupNumberAlways).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
this.plugin.settings.dupNumberAlways = value;
|
||||
yield this.plugin.saveSettings();
|
||||
})
|
||||
));
|
||||
new import_obsidian2.Setting(containerEl).setName("Auto rename").setDesc(`By default, the rename modal will always be shown to confirm before renaming, if this option is set, the image will be auto renamed after pasting.`).addToggle((toggle) => toggle.setValue(this.plugin.settings.autoRename).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
this.plugin.settings.autoRename = value;
|
||||
yield this.plugin.saveSettings();
|
||||
})
|
||||
));
|
||||
new import_obsidian2.Setting(containerEl).setName("Handle all attachments").setDesc(`By default, the plugin only handles images that starts with "Pasted image " in name,
|
||||
which is the prefix Obsidian uses to create images from pasted content.
|
||||
If this option is set, the plugin will handle all attachments that are created in the vault.`).addToggle((toggle) => toggle.setValue(this.plugin.settings.handleAllAttachments).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
this.plugin.settings.handleAllAttachments = value;
|
||||
yield this.plugin.saveSettings();
|
||||
})
|
||||
));
|
||||
new import_obsidian2.Setting(containerEl).setName("Exclude extension pattern").setDesc(`This option is only useful when "Handle all attachments" is enabled.
|
||||
Write a Regex pattern to exclude certain extensions from being handled. Only the first line will be used.`).setClass("single-line-textarea").addTextArea((text) => text.setPlaceholder("docx?|xlsx?|pptx?|zip|rar").setValue(this.plugin.settings.excludeExtensionPattern).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
this.plugin.settings.excludeExtensionPattern = value;
|
||||
yield this.plugin.saveSettings();
|
||||
})
|
||||
));
|
||||
new import_obsidian2.Setting(containerEl).setName("Disable rename notice").setDesc(`Turn off this option if you don't want to see the notice when renaming images.
|
||||
Note that Obsidian may display a notice when a link has changed, this option cannot disable that.`).addToggle((toggle) => toggle.setValue(this.plugin.settings.disableRenameNotice).onChange(
|
||||
(value) => __async(this, null, function* () {
|
||||
this.plugin.settings.disableRenameNotice = value;
|
||||
yield this.plugin.saveSettings();
|
||||
})
|
||||
));
|
||||
}
|
||||
};
|
||||
|
||||
/* nosourcemap */
|
||||
10
src/content/.obsidian/plugins/obsidian-paste-image-rename/manifest.json
vendored
Normal file
10
src/content/.obsidian/plugins/obsidian-paste-image-rename/manifest.json
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
{
|
||||
"id": "obsidian-paste-image-rename",
|
||||
"name": "Paste image rename",
|
||||
"version": "1.6.1",
|
||||
"minAppVersion": "0.12.0",
|
||||
"description": "Rename pasted images and all the other attchments added to the vault",
|
||||
"author": "Reorx",
|
||||
"authorUrl": "https://github.com/reorx",
|
||||
"isDesktopOnly": false
|
||||
}
|
||||
79
src/content/.obsidian/plugins/obsidian-paste-image-rename/styles.css
vendored
Normal file
79
src/content/.obsidian/plugins/obsidian-paste-image-rename/styles.css
vendored
Normal file
@@ -0,0 +1,79 @@
|
||||
/* src/styles.css */
|
||||
:root {
|
||||
--shadow-color: 0deg 0% 0%;
|
||||
--shadow-elevation-medium:
|
||||
0.5px 0.5px 0.7px hsl(var(--shadow-color) / 0.14),
|
||||
1.1px 1.1px 1.5px -0.9px hsl(var(--shadow-color) / 0.12),
|
||||
2.4px 2.5px 3.3px -1.8px hsl(var(--shadow-color) / 0.1),
|
||||
5.3px 5.6px 7.3px -2.7px hsl(var(--shadow-color) / 0.09),
|
||||
11px 11.4px 15.1px -3.6px hsl(var(--shadow-color) / 0.07);
|
||||
}
|
||||
.image-rename-modal .modal {
|
||||
width: 65%;
|
||||
min-width: 600px;
|
||||
}
|
||||
.image-rename-modal .modal-content {
|
||||
padding: 10px 5px;
|
||||
}
|
||||
.image-rename-modal .image-container {
|
||||
display: flex;
|
||||
justify-content: center;
|
||||
}
|
||||
.image-rename-modal .info {
|
||||
padding: 10px 0;
|
||||
color: var(--text-muted);
|
||||
user-select: text;
|
||||
}
|
||||
.image-rename-modal .info li > span:nth-of-type(1) {
|
||||
display: inline-block;
|
||||
width: 6em;
|
||||
margin-right: .5em;
|
||||
}
|
||||
.image-rename-modal .info li > span:nth-of-type(1):after {
|
||||
content: ":";
|
||||
float: right;
|
||||
}
|
||||
.image-rename-modal .image-container img {
|
||||
display: block;
|
||||
max-height: 300px;
|
||||
box-shadow: var(--shadow-elevation-medium);
|
||||
}
|
||||
.image-rename-modal .setting-item-control input {
|
||||
min-width: 300px;
|
||||
}
|
||||
.image-rename-modal .error {
|
||||
border: 1px solid rgb(201, 90, 90);
|
||||
color: rgb(134, 22, 22);
|
||||
padding: 10px;
|
||||
}
|
||||
.image-rename-modal table {
|
||||
font-size: .9em;
|
||||
line-height: 1.8;
|
||||
margin-bottom: 1.5em;
|
||||
user-select: text;
|
||||
}
|
||||
.image-rename-modal table td {
|
||||
padding-right: 1em;
|
||||
}
|
||||
.image-rename-modal table thead td {
|
||||
font-weight: 700;
|
||||
}
|
||||
.image-rename-modal table tbody td .file-path {
|
||||
font-size: .8em;
|
||||
color: var(--text-faint);
|
||||
line-height: 1;
|
||||
}
|
||||
.long-description-setting-item {
|
||||
flex-wrap: wrap;
|
||||
}
|
||||
.long-description-setting-item .setting-item-description {
|
||||
white-space: pre-wrap;
|
||||
line-height: 1.3em;
|
||||
}
|
||||
.long-description-setting-item .setting-item-control {
|
||||
padding-top: 10px;
|
||||
}
|
||||
.long-description-setting-item .setting-item-control input {
|
||||
min-width: 300px;
|
||||
width: 50%;
|
||||
}
|
||||
181
src/content/.obsidian/workspace-mobile.json
vendored
Normal file
181
src/content/.obsidian/workspace-mobile.json
vendored
Normal file
@@ -0,0 +1,181 @@
|
||||
{
|
||||
"main": {
|
||||
"id": "11c40c0eff369230",
|
||||
"type": "split",
|
||||
"children": [
|
||||
{
|
||||
"id": "a3b78448b99fd05e",
|
||||
"type": "tabs",
|
||||
"children": [
|
||||
{
|
||||
"id": "a48cfb809f321ac1",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "markdown",
|
||||
"state": {
|
||||
"file": "posts/mobile-git.md",
|
||||
"mode": "source",
|
||||
"source": false
|
||||
},
|
||||
"icon": "lucide-file",
|
||||
"title": "mobile-git"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"direction": "vertical"
|
||||
},
|
||||
"left": {
|
||||
"id": "084d99fc7dfae6d5",
|
||||
"type": "mobile-drawer",
|
||||
"children": [
|
||||
{
|
||||
"id": "913290ce74f3c790",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "file-explorer",
|
||||
"state": {
|
||||
"sortOrder": "alphabetical",
|
||||
"autoReveal": false
|
||||
},
|
||||
"icon": "lucide-folder-closed",
|
||||
"title": "文件列表"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "715c6bf7efb3af34",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "search",
|
||||
"state": {
|
||||
"query": "",
|
||||
"matchingCase": false,
|
||||
"explainSearch": false,
|
||||
"collapseAll": false,
|
||||
"extraContext": false,
|
||||
"sortOrder": "alphabetical"
|
||||
},
|
||||
"icon": "lucide-search",
|
||||
"title": "搜索"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "1867f88e0e5be91e",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "tag",
|
||||
"state": {
|
||||
"sortOrder": "frequency",
|
||||
"useHierarchy": true,
|
||||
"showSearch": false,
|
||||
"searchQuery": ""
|
||||
},
|
||||
"icon": "lucide-tags",
|
||||
"title": "标签"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "c81497cc77ac87dc",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "bookmarks",
|
||||
"state": {},
|
||||
"icon": "lucide-bookmark",
|
||||
"title": "书签"
|
||||
}
|
||||
}
|
||||
],
|
||||
"currentTab": 0
|
||||
},
|
||||
"right": {
|
||||
"id": "00f2d94402e22f34",
|
||||
"type": "mobile-drawer",
|
||||
"children": [
|
||||
{
|
||||
"id": "c18847a8fc329542",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "backlink",
|
||||
"state": {
|
||||
"collapseAll": false,
|
||||
"extraContext": false,
|
||||
"sortOrder": "alphabetical",
|
||||
"showSearch": false,
|
||||
"searchQuery": "",
|
||||
"backlinkCollapsed": false,
|
||||
"unlinkedCollapsed": true
|
||||
},
|
||||
"icon": "links-coming-in",
|
||||
"title": "反向链接"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "a0983a2e5ea8f256",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "outgoing-link",
|
||||
"state": {
|
||||
"linksCollapsed": false,
|
||||
"unlinkedCollapsed": true
|
||||
},
|
||||
"icon": "links-going-out",
|
||||
"title": "出链"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "289ab02c28f6d4b5",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "outline",
|
||||
"state": {
|
||||
"followCursor": false,
|
||||
"showSearch": false,
|
||||
"searchQuery": ""
|
||||
},
|
||||
"icon": "lucide-list",
|
||||
"title": "大纲"
|
||||
}
|
||||
}
|
||||
],
|
||||
"currentTab": 0
|
||||
},
|
||||
"left-ribbon": {
|
||||
"hiddenItems": {
|
||||
"switcher:打开快速切换": false,
|
||||
"graph:查看关系图谱": false,
|
||||
"canvas:新建白板": false,
|
||||
"daily-notes:打开/创建今天的日记": false,
|
||||
"templates:插入模板": false,
|
||||
"command-palette:打开命令面板": false,
|
||||
"bases:创建新数据库": false
|
||||
}
|
||||
},
|
||||
"active": "a48cfb809f321ac1",
|
||||
"lastOpenFiles": [
|
||||
"posts/163-free-domain-email.md",
|
||||
"posts/acg-randompic-api.md",
|
||||
"posts/mobile-git.md",
|
||||
"posts/warden-worker.md",
|
||||
"posts/record.md",
|
||||
"assets/images/Screenshot_2025-11-24-07-56-33-62_a2e3670364a4153bdb03dad30c8d4108.jpg",
|
||||
"assets/images/Screenshot_2025-11-24-07-56-23-48_a2e3670364a4153bdb03dad30c8d4108 1.jpg",
|
||||
"assets/images/Screenshot_2025-11-24-07-55-54-35_df198e732186825c8df26e3c5a10d7cd 1.jpg",
|
||||
"assets/images/Screenshot_2025-11-24-07-56-23-48_a2e3670364a4153bdb03dad30c8d4108.jpg",
|
||||
"assets/images/Screenshot_2025-11-24-07-55-54-35_df198e732186825c8df26e3c5a10d7cd.jpg",
|
||||
"posts/wx-zfb-card.md",
|
||||
"assets/images/Screenshot_2025-11-11-14-18-53-34_51606159b24eff83e24a54116878fe3e.jpg",
|
||||
"assets/images/Screenshot_2025-11-11-14-17-32-08_51606159b24eff83e24a54116878fe3e.jpg",
|
||||
"assets/images/Screenshot_2025-11-11-14-15-59-46_51606159b24eff83e24a54116878fe3e.jpg",
|
||||
"assets/images/Screenshot_2025-11-11-14-15-01-63_b5a5c5cb02ca09c784c5d88160e2ec24.jpg",
|
||||
"assets/images/Screenshot_2025-11-11-14-13-03-99_a2e3670364a4153bdb03dad30c8d4108.jpg",
|
||||
"posts/check-notebook.md",
|
||||
"未命名.md",
|
||||
"posts/zte-f450-bridge.md",
|
||||
"posts/unknown-upload.md",
|
||||
"posts/rvc.md",
|
||||
"posts/index-tts2.md",
|
||||
"posts/hook-steam-drm.md",
|
||||
"posts/first-pc.md"
|
||||
]
|
||||
}
|
||||
211
src/content/.obsidian/workspace.json
vendored
Normal file
211
src/content/.obsidian/workspace.json
vendored
Normal file
@@ -0,0 +1,211 @@
|
||||
{
|
||||
"main": {
|
||||
"id": "c6989ce27d23c45d",
|
||||
"type": "split",
|
||||
"children": [
|
||||
{
|
||||
"id": "7f06a11af95175a9",
|
||||
"type": "tabs",
|
||||
"children": [
|
||||
{
|
||||
"id": "96b79d1156396696",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "markdown",
|
||||
"state": {
|
||||
"file": "posts/random-url-gen.md",
|
||||
"mode": "source",
|
||||
"source": false
|
||||
},
|
||||
"icon": "lucide-file",
|
||||
"title": "random-url-gen"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"direction": "vertical"
|
||||
},
|
||||
"left": {
|
||||
"id": "adad91cfb262dcee",
|
||||
"type": "split",
|
||||
"children": [
|
||||
{
|
||||
"id": "03f1023b2d857cdc",
|
||||
"type": "tabs",
|
||||
"children": [
|
||||
{
|
||||
"id": "7be4ba729d2aae5a",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "file-explorer",
|
||||
"state": {
|
||||
"sortOrder": "alphabetical",
|
||||
"autoReveal": false
|
||||
},
|
||||
"icon": "lucide-folder-closed",
|
||||
"title": "文件列表"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "5174a9cd87b0f8f9",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "search",
|
||||
"state": {
|
||||
"query": "",
|
||||
"matchingCase": false,
|
||||
"explainSearch": false,
|
||||
"collapseAll": false,
|
||||
"extraContext": false,
|
||||
"sortOrder": "alphabetical"
|
||||
},
|
||||
"icon": "lucide-search",
|
||||
"title": "搜索"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "f33d418216a86348",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "bookmarks",
|
||||
"state": {},
|
||||
"icon": "lucide-bookmark",
|
||||
"title": "书签"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"direction": "horizontal",
|
||||
"width": 300
|
||||
},
|
||||
"right": {
|
||||
"id": "f6608acce08382a1",
|
||||
"type": "split",
|
||||
"children": [
|
||||
{
|
||||
"id": "c4b67f4636c6ac01",
|
||||
"type": "tabs",
|
||||
"children": [
|
||||
{
|
||||
"id": "a6b54f415fc99d0e",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "backlink",
|
||||
"state": {
|
||||
"file": "posts/obsidian.md",
|
||||
"collapseAll": false,
|
||||
"extraContext": false,
|
||||
"sortOrder": "alphabetical",
|
||||
"showSearch": false,
|
||||
"searchQuery": "",
|
||||
"backlinkCollapsed": false,
|
||||
"unlinkedCollapsed": true
|
||||
},
|
||||
"icon": "links-coming-in",
|
||||
"title": "obsidian 的反向链接列表"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "630fd596ceed61e1",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "outgoing-link",
|
||||
"state": {
|
||||
"file": "posts/obsidian.md",
|
||||
"linksCollapsed": false,
|
||||
"unlinkedCollapsed": true
|
||||
},
|
||||
"icon": "links-going-out",
|
||||
"title": "obsidian 的出链列表"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "52896168f27b3092",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "tag",
|
||||
"state": {
|
||||
"sortOrder": "frequency",
|
||||
"useHierarchy": true,
|
||||
"showSearch": false,
|
||||
"searchQuery": ""
|
||||
},
|
||||
"icon": "lucide-tags",
|
||||
"title": "标签"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "6f2f79f39b3c9de9",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "outline",
|
||||
"state": {
|
||||
"file": "posts/obsidian.md",
|
||||
"followCursor": false,
|
||||
"showSearch": false,
|
||||
"searchQuery": ""
|
||||
},
|
||||
"icon": "lucide-list",
|
||||
"title": "obsidian 的大纲"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"direction": "horizontal",
|
||||
"width": 300,
|
||||
"collapsed": true
|
||||
},
|
||||
"left-ribbon": {
|
||||
"hiddenItems": {
|
||||
"switcher:打开快速切换": false,
|
||||
"graph:查看关系图谱": false,
|
||||
"canvas:新建白板": false,
|
||||
"daily-notes:打开/创建今天的日记": false,
|
||||
"templates:插入模板": false,
|
||||
"command-palette:打开命令面板": false,
|
||||
"bases:创建新数据库": false
|
||||
}
|
||||
},
|
||||
"active": "96b79d1156396696",
|
||||
"lastOpenFiles": [
|
||||
"assets/images/random-url-gen-11.png",
|
||||
"assets/images/random-url-gen-10.png",
|
||||
"assets/images/random-url-gen-9.png",
|
||||
"assets/images/random-url-gen-8.png",
|
||||
"assets/images/random-url-gen-7.png",
|
||||
"assets/images/random-url-gen-6.png",
|
||||
"assets/images/random-url-gen-5.png",
|
||||
"assets/images/random-url-gen-4.png",
|
||||
"assets/images/random-url-gen-3.png",
|
||||
"assets/images/random-url-gen-2.png",
|
||||
"assets/images/random-url-gen-1.png",
|
||||
"posts/eo-umami.md",
|
||||
"posts/fuwari.md",
|
||||
"posts/ddos-6t.md",
|
||||
"posts/py-uploadserver.md",
|
||||
"posts/umami-migration.md",
|
||||
"posts/serverless-function.md",
|
||||
"posts/pin.md",
|
||||
"posts/anuneko.md",
|
||||
"posts/win11-to-win10.md",
|
||||
"posts/remote.md",
|
||||
"posts/warden-worker.md",
|
||||
"posts/expressive-code.md",
|
||||
"posts/lskypro-local.md",
|
||||
"posts/ms-e3.md",
|
||||
"posts/onedrive-index.md",
|
||||
"posts/why-not-icp.md",
|
||||
"posts/ipfs.md",
|
||||
"posts/swup-js.md",
|
||||
"posts/static-view.md",
|
||||
"posts/oci.md",
|
||||
"posts/wx-zfb-card.md",
|
||||
"posts/mobile-git.md",
|
||||
"posts/check-notebook.md",
|
||||
"posts/unknown-upload.md",
|
||||
"posts/zte-f450-bridge.md"
|
||||
]
|
||||
}
|
||||
38
src/content/config.ts
Normal file
38
src/content/config.ts
Normal file
@@ -0,0 +1,38 @@
|
||||
import { defineCollection, z } from "astro:content";
|
||||
|
||||
const postsCollection = defineCollection({
|
||||
schema: z.object({
|
||||
title: z.string(),
|
||||
published: z.date(),
|
||||
updated: z.date().optional(),
|
||||
draft: z.boolean().optional().default(false),
|
||||
description: z.string().optional().default(""),
|
||||
image: z.string().optional().default(""),
|
||||
tags: z.array(z.string()).optional().default([]),
|
||||
category: z.union([
|
||||
z.string(),
|
||||
z.array(z.string()),
|
||||
]).optional(),
|
||||
lang: z.string().optional().default(""),
|
||||
pinned: z.boolean().optional().default(false),
|
||||
|
||||
/* For internal use */
|
||||
prevTitle: z.string().default(""),
|
||||
prevSlug: z.string().default(""),
|
||||
nextTitle: z.string().default(""),
|
||||
nextSlug: z.string().default(""),
|
||||
}),
|
||||
});
|
||||
|
||||
const assetsCollection = defineCollection({
|
||||
type: 'data',
|
||||
schema: z.object({
|
||||
title: z.string().optional(),
|
||||
description: z.string().optional(),
|
||||
}),
|
||||
});
|
||||
|
||||
export const collections = {
|
||||
posts: postsCollection,
|
||||
assets: assetsCollection,
|
||||
};
|
||||
1969
src/content/posts/Golang/Gin框架快速入门.md
Normal file
1969
src/content/posts/Golang/Gin框架快速入门.md
Normal file
File diff suppressed because it is too large
Load Diff
326
src/content/posts/Golang/Go_map底层结构.md
Normal file
326
src/content/posts/Golang/Go_map底层结构.md
Normal file
@@ -0,0 +1,326 @@
|
||||
---
|
||||
title: Go_map底层结构
|
||||
published: 2025-07-19
|
||||
description: ''
|
||||
image: 'https://blog.meowrain.cn/api/i/2025/07/19/uje4vo-1.webp'
|
||||
tags: [切片, Golang, Go]
|
||||
category: 'Go'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# Golang map底层数据结构
|
||||
|
||||
<https://golang.design/go-questions/map/principal/>
|
||||
|
||||
[Golang map 实现原理](https://mp.weixin.qq.com/s?__biz=MzkxMjQzMjA0OQ==&mid=2247483868&idx=1&sn=6e954af8e5e98ec0a9d9fc5c8ceb9072&chksm=c10c4f02f67bc614ff40a152a848508aa1631008eb5a600006c7552915d187179c08d4adf8d7&scene=0&xtrack=1&subscene=90#rd)
|
||||
|
||||
## 概述
|
||||
|
||||
map是一种常用的数据结构,核心特征包括下面三点:
|
||||
|
||||
- 存储基于key-value对映射的模式
|
||||
- 基于key维度实现存储数据的去重
|
||||
- 读,写,删操作控制,时间复杂度O(1)
|
||||
|
||||

|
||||
|
||||
### 初始化方法
|
||||
|
||||
```go
|
||||
map1 := make(map[string]int)
|
||||
|
||||
map2 := map[string]int{
|
||||
"m1": 1,
|
||||
"m2":2,
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### key 类型要求
|
||||
|
||||
map中,key的数据类型必须是可以比较的类型,slice,chan,func,map不可比较,所以不能作为map的key
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
# 核心原理
|
||||
|
||||
map又称为hash map,算法上基于hash实现key的映射和寻址,在数据结构上基于桶数组实现key-value对的存储
|
||||
|
||||
以一组key-value对写入map的流程进行简述:
|
||||
|
||||
1. 通过哈希方法去的key的hash值‘
|
||||
2. hash值对同数组长度取模,确定它所属的桶
|
||||
3. 在桶中插入key value对
|
||||
|
||||
|
||||
|
||||
## hash
|
||||
|
||||
hash 译作散列,是一种将任意长度的输入压缩到某一固定长度的输出摘要的过程,由于这种转换属于压缩映射,输入空间远大于输出空间,因此不同输入可能会映射成相同的输出结果. 此外,hash在压缩过程中会存在部分信息的遗失,因此这种映射关系具有不可逆的特质.
|
||||
|
||||
1. hash的可重入性: 相同的key,必然产生相同的hash值
|
||||
2. hash的离散性: 只要两个key不相同,不论他们相似度的高低,产生的hash值会在整个输出域内均匀地离散化
|
||||
3. hash的单向性: 企图通过hash值反向映射会key是无迹可寻的。
|
||||
4. hash冲突: 由于输入域无穷大,输出域有限,必然存在不同key映射到相同hash值的情况,这种情况叫做哈希冲突
|
||||
|
||||
|
||||
|
||||
## 桶数组
|
||||
|
||||
map中,会通过长度为2的整数次幂的桶数组进行key-value对的存储
|
||||
|
||||
1. 每个桶固定可以存放8个key-value对
|
||||
2. 倘若超过8个key-value对打到桶数组的同一个索引当中,此时会通过创建桶链表的方式来化解这个问题。
|
||||
|
||||
|
||||
|
||||
## 拉链法解决hash冲突
|
||||
|
||||
首先,由于hash冲突的存在,不同的key可能存在相同的hash值
|
||||
|
||||
再者,hash值会对桶数组长度取模,因此不同的hash值可能被打到同一个桶中
|
||||
|
||||
综上,不同的key-value可能被映射到map的同一个桶当中。
|
||||
|
||||
拉链法中,将命中同一个桶的元素通过链表的形式进行连接,因此便于动态扩展
|
||||
|
||||
> 只有当一个桶已经满了(8 个 kv 对),并且又有新的 key 哈希到这个桶时,才会创建溢出桶,并将新的 key-value 对存储到溢出桶中,然后将该溢出桶链接到原桶的尾部。 后续再有冲突的 kv 对,也会被添加到溢出桶或者新的溢出桶中,形成一个链表。
|
||||
|
||||
|
||||
|
||||
## 开放寻址法解决hash冲突
|
||||
|
||||
> 开放寻址法是一种解决哈希冲突的方法,它在哈希表中寻找另一个空闲位置存储冲突的元素,也就是说,所有元素都直接存储在哈希表的桶中
|
||||
>
|
||||
> 开放寻址法是一种在哈希表中解决冲突的方法。当两个不同的键映射到同一个索引位置时,就会发生冲突。开放寻址法不是使用链表等额外的数据结构来存储冲突的键值对,而是尝试在哈希表本身中寻找一个空闲的位置来存储新的键值对。
|
||||
|
||||
|
||||
|
||||
常见开放寻址技术:
|
||||
|
||||
- 线性寻址: 如果在索引`i`发生冲突,线性探测会依次检查`i+1`,`i+2`,`i+3`等位置,直到找到一个空闲的槽位
|
||||
- 二次探测检查 `i + 1^2`、`i + 2^2`、`i + 3^2` 等位置。与线性探测相比,这有助于减少聚集现象。
|
||||
- 双重哈希: 双重哈希使用第二个哈希函数来确定探测的步长。如果第一个哈希函数在索引`i`导致哈希冲突,第二个哈希函数hash2(key)用于确定探测的间隔(例如,`i + hash2(key)`、`i + 2*hash2(key)`、`i + 3*hash2(key)` 等)。
|
||||
|
||||
|
||||
|
||||
我们的golang map解决哈希冲突的方式结合了拉链法和开放寻址法。
|
||||
|
||||
- 桶: map的底层数据结构是一个桶数组,每个桶严格意义上是一个单向桶链表
|
||||
- 桶的大小: 每个桶可以固定存放8个key value对
|
||||
- 当key命中一个桶的时候,首先根据开放寻址法,在桶的8个位置中寻找空位进行插入
|
||||
- 倘若8个位置都已经被占满,就基于桶的溢出桶指针,找到下一个桶(重复第三步)
|
||||
- 倘若遍历到链表尾部,还没找到空位,就用拉链法,在桶链表尾部接入新桶,并且插入key-value对
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
## 扩容性能优化
|
||||
|
||||
倘若map的桶数组长度固定不变,那么随着key-value对数量的增长,当一个桶下挂载的key-value达到一定的量级,此时操作的时间复杂度会趋于线性,无法满足诉求。
|
||||
|
||||
**桶数组长度固定不变 + key-value 对数量持续增加 => 哈希冲突加剧 => Bucket 链表变长 => 查找/插入/删除 需要遍历长链表 => 操作时间复杂度接近 O(n) (线性)**
|
||||
|
||||
因此在设计上,map桶的数组长度会随着key-value对的数量变化而实时调整。保证每个桶内的key-value对数量始终控制在常量级别。
|
||||
|
||||
扩容类型分为:
|
||||
|
||||
- 增量扩容
|
||||
- 等量扩容
|
||||
|
||||
### 增量扩容
|
||||
|
||||
触发条件: `key-value总数 / 桶数组长度 > 6.5`的时候,发生增量扩容
|
||||
|
||||
扩容方式: 桶数组长度增长为原来的`两倍`
|
||||
|
||||
目的: 减少负载因子,降低平均查找时间
|
||||
|
||||
负载因子: `key-value总数 / 桶的数量`
|
||||
|
||||

|
||||
|
||||
### 等量扩容
|
||||
|
||||
触发条件: 当桶内溢出桶数量大于等于2^B时(B 为桶数组长度的指数,B 最大取 15),发生等量扩容。)
|
||||
|
||||
扩容方式: 桶的长度保持为原来的值
|
||||
|
||||
**目的:** 解决哈希冲突严重的问题,可能由于哈希函数选择不佳导致大量 key 映射到相同的桶,即使负载因子不高,也会出现大量溢出桶。 等量扩容旨在重新组织数据,减少溢出桶的数量。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 渐进式扩容
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
# 数据结构
|
||||
|
||||
## hmap
|
||||
|
||||
```go
|
||||
type hmap struct {
|
||||
count int // map中键值对的数量
|
||||
flags uint8 // map的状态标志位,用来指示map的当前状态(正在写入,正在扩容等)
|
||||
B uint8 // buckets 数组的对数大小,2^B 是buckets数组的长度,比如B是5,那么桶数组的长度就是2^5 = 32
|
||||
noverflow uint16 //溢出桶数量的近似值 用来判断是否需要扩容
|
||||
hash0 uint32 // 哈希种子
|
||||
buckets unsafe.Pointer //指向bucket数组的指针,数组大小为2 ^ B,如果count == 0,那么buckets可能为nil
|
||||
oldbuckets unsafe.Pointer // 如果发生扩容,指向旧的buckets数组
|
||||
nevacuate uintptr // 扩容的时候,表示旧buckcet数组已经迁移到新bucket数组的数量计数器
|
||||
extra *mapextra // 可选字段,用来保存overflow buckets的信息
|
||||
}
|
||||
```
|
||||
|
||||
flags: map状态标识,其包含的主要状态为(这里面牵扯到很多概念还没有涉及,可以先大致的了解一下各自的含义)
|
||||
|
||||
- iterator(`0b0001`): 当前map可能正在被遍历
|
||||
- oldIterator(`0b0010`): 当前map的旧桶可能正在被遍历
|
||||
- hashWrting(`0b0100`): 一个goroutine正在向map中写入数据
|
||||
- sameSizeGrow(`0b1000`): 等量扩容标志字段
|
||||
|
||||
## bmap
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
> bmap就是map中的桶,可以存储8组key-value对数据,以及一个只想下一个溢出桶的指针
|
||||
|
||||

|
||||
|
||||
每一组key-value对数据包含key高8位hash值tophash,key,value三部分
|
||||
|
||||
我们来看看bmap(桶)的内存模型
|
||||
|
||||

|
||||
|
||||
如果按照 `key/value/key/value/...` 这样的模式存储,那在每一个 key/value 对之后都要额外 padding 7 个字节;而将所有的 key,value 分别绑定到一起,这种形式 `key/key/.../value/value/...`,则只需要在最后添加 padding。
|
||||
|
||||
每个 bucket 设计成最多只能放 8 个 key-value 对,如果有第 9 个 key-value 落入当前的 bucket,那就需要再构建一个 bucket ,通过 `overflow` 指针连接起来。
|
||||
|
||||
### tophash的作用?
|
||||
|
||||
是key 哈希值的高8位
|
||||
|
||||
tophash的核心作用是**判断一个键是否可能存在于当前桶中,从而优化查询效率。**
|
||||
|
||||
## 溢出桶数据结构 mapextra
|
||||
|
||||
在map初始化的时候会根据初始数据量不同,自动创建不同数量的溢出桶。在物理结构上初始的正常同和溢出桶是连续存放的,正常桶和溢出桶之间的关系是靠链表来维护的。
|
||||
|
||||
> `mapextra` 就是在扩容时提供了一批预备的 `bmap`,然后利用 `bmap.overflow` 把它们链接起来。
|
||||
|
||||
```go
|
||||
type mapextra struct {
|
||||
overflow *[]*bmap // overflow buckets 的指针数组
|
||||
oldoverflow *[]*bmap // 旧的 overflow buckets 的指针数组
|
||||
|
||||
nextOverflow *bmap // 指向空闲的 overflow bucket
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
在map初始化的时候,倘若容量过大,会提前申请好一批溢出桶,供后续使用,这部分溢出桶存放在hmap.mapextra当中:
|
||||
|
||||
mapextra.overflow 是一个指向溢出桶切片的指针,这个切片里面的溢出桶是当前使用的,用于存储hmap.buckets中的桶的溢出数据。
|
||||
|
||||
mapextra.oldoverflow 也是一个指向溢出桶切片的指针,但是它指向的是旧的桶数组的溢出桶。
|
||||
|
||||
nextOverflow指向下一个可用的溢出桶
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
# 什么是哈希种子?
|
||||
|
||||
哈希种子(hash seed)是一个随机生成的数值,被用作哈希函数的一部分,来增加哈希值的随机性和不可预测性,可以把它理解为哈希函数的“盐”
|
||||
|
||||
# go map 如何根据key的哈希值确定键值存储到哪个桶中?
|
||||
|
||||
## 哈希值的作用
|
||||
|
||||
- 首先,当你在 Go map 中插入一个键值对时,Go runtime 会对键进行哈希运算,生成一个哈希值(一个整数)。 优秀的哈希函数应该能够将不同的键尽可能均匀地映射到不同的哈希值,以减少哈希碰撞的概率。
|
||||
- 这个哈希值是确定键值对存储位置的关键。
|
||||
|
||||
## go map 数据结构中hmap 中B的作用
|
||||
|
||||
我们通过哈希值的低B位作为bucket数组的索引, 来选择键值该存储到哪个bucket中。
|
||||
|
||||
公式 `bucketIndex = hash & ((1 << B) - 1)`
|
||||
|
||||
上面的公式 用来**保留 `hash` 的低 `B` 位,并将其他位设置为 0**。
|
||||
|
||||
|
||||
|
||||
# key定位过程
|
||||
|
||||
key经过哈希计算后得到哈希值,共64个bit位,计算它到底要落在哪个桶的时候,只会用到最后B个bit位(log2BucketCount)
|
||||
|
||||
例如,现在有一个key经过哈希函数计算后,得到的哈希结果是:
|
||||
|
||||
```
|
||||
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010
|
||||
```
|
||||
|
||||
而我们的B是5,也就是有2^5 = 32个桶
|
||||
|
||||
取最后五位,也就是 **01010** 转换为10进制也就是10,也就是 **10号桶**,这个操作其实是 **取余操作**,但是取余数开销太大,就用上面的位运算代替了。
|
||||
|
||||
接下来我们再用 **hash值的高8位**找到key在 **10号桶**中的位置 **1001011转换为10进制也就是 75**.最开始桶内还没有 key,新加入的 key 会找到第一个空位,放入。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
# 流程
|
||||
|
||||
|
||||
|
||||
# 写入流程
|
||||
|
||||
写入流程:
|
||||
|
||||
- 进行hmap是否为nil的检查,如果为空,就触发panic
|
||||
- 进行并发读写的检查,倘若已经设置了并发读写标记,就抛出"concurrent map writes"异常。
|
||||
- 处理桶迁移。如果正在扩容,把key所在的旧桶数据迁移到新桶,同时迁移index位h.nevacuate的桶,迁移完成后h.nevacuate自增。更新迁移进度。如果所有桶迁移完毕,清除正在扩容的标记。
|
||||
- 查找 key 所在的位置,并记录桶链表的第一个空闲位置(若此 key 之前不存在,则将该位置作为插入位置)。
|
||||
- 若此 key 在桶链表中不存在,判断是否需要扩容,若溢出桶过多,则进行相同容量的扩容,否则进行双倍容量的扩容。
|
||||
- 若桶链表没有空闲位置,则申请溢出桶来存放 key - value 对。
|
||||
- 设置 key 和 tophash[i] 的值。
|
||||
- 返回 value 的地址。
|
||||
|
||||
# 删除流程
|
||||
|
||||
删除流程:
|
||||
|
||||
- 进行并发读写检查。
|
||||
- 处理桶迁移,如果map处于正在扩容的状态,就迁移两个桶
|
||||
- 定位key所在的位置
|
||||
- 删除kv对的占用,这里是伪删除,只有在下次扩容的时候,被删除的key所占用的同空间才会得到释放。
|
||||
- map首先会将对应位置的tophash[i]设置为emptyOne,表示该位置被删除
|
||||
- 如果tophash[i]后面还有有效的节点,就仅设置为emptyOne标志,意味着这个节点后面仍然存在有效的key-value对 ,后续在查找某个key的时候,这个节点只后仍然需要继续查找
|
||||
- 要是tophash[i]是桶链表的最后一个有效节点,那么从这个节点往前遍历,将链表最后面所有标志位emptyOne的位置,都设置为emptyRest。这样在查找某个key的时候,emptyRest之后的节点不需要继续查找。
|
||||
|
||||
> - **`emptyOne`:** 表示当前 cell 是空的,但**不能保证**后面的 cell 也是空的。
|
||||
> - **`emptyRest`:** 表示当前 cell 是空的,并且**保证**后面的所有 cell 也是空的,直到遇到一个非空 cell 或者到达桶的末尾。
|
||||
|
||||
# 迭代流程
|
||||
|
||||
在每次对 map 进行循环时,会调用 mapiterinit 函数,以确定迭代从哪个桶以及桶内的哪个位置起始。由于 mapiterinit 内部是通过随机数来决定起始位置的,所以 map 循环是无序的,每次循环所返回的 key - value 对的顺序都各不相同。
|
||||
|
||||

|
||||
189
src/content/posts/Golang/Go_slice切片原理.md
Normal file
189
src/content/posts/Golang/Go_slice切片原理.md
Normal file
@@ -0,0 +1,189 @@
|
||||
---
|
||||
title: Go_slice切片原理
|
||||
published: 2025-07-19
|
||||
description: ''
|
||||
image: 'https://blog.meowrain.cn/api/i/2025/07/19/uje4vo-1.webp'
|
||||
tags: [切片, Golang, Go]
|
||||
category: 'Go'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# slice数据结构
|
||||
|
||||
数据结构
|
||||
我们每定义一个slice变量,golang底层都会构建一个slice结构的对象。slice结构体由3个成员变量构成:
|
||||
|
||||
array表示数组指针,数组用于存储数据。
|
||||
len表示切片长度,也就是数组index从0到len-1已存储数据。
|
||||
cap表示切片容量,当切片长度超过最大容量时,需要扩容申请更大长度的数组。
|
||||
|
||||
```go
|
||||
type slice struct {
|
||||
array unsafe.Pointer // 数组指针
|
||||
len int // 切片长度
|
||||
cap int // 切片容量
|
||||
}
|
||||
```
|
||||
|
||||
# 扩容原理
|
||||
|
||||
切片的扩容流程源码位于 runtime/slice.go 文件的 growslice 方法当中,其中核心步骤如下:
|
||||
|
||||
• 倘若扩容后预期的新容量小于原切片的容量,则 panic
|
||||
|
||||
• 倘若切片元素大小为 0(元素类型为 struct{}),则直接复用一个全局的 zerobase 实例,直接返回
|
||||
|
||||
• 倘若预期的新容量超过老容量的两倍,则直接采用预期的新容量
|
||||
|
||||
• 倘若老容量小于 256,则直接采用老容量的2倍作为新容量
|
||||
|
||||
• 倘若老容量已经大于等于 256,则在老容量的基础上扩容 1/4 的比例并且累加上 192 的数值,持续这样处理,直到得到的新容量已经大于等于预期的新容量为止
|
||||
|
||||
• 结合 mallocgc 流程中,对内存分配单元 mspan 的等级制度,推算得到实际需要申请的内存空间大小
|
||||
|
||||
• 调用 mallocgc,对新切片进行内存初始化
|
||||
|
||||
• 调用 memmove 方法,将老切片中的内容拷贝到新切片中
|
||||
|
||||
• 返回扩容后的新切片
|
||||
|
||||
```go
|
||||
// nextslicecap computes the next appropriate slice length.
|
||||
func nextslicecap(newLen, oldCap int) int {
|
||||
newcap := oldCap // 将新容量初始化为旧容量
|
||||
doublecap := newcap + newcap // 计算旧容量的两倍
|
||||
|
||||
// 如果所需的新长度大于旧容量的两倍,则直接使用所需的新长度
|
||||
if newLen > doublecap {
|
||||
return newLen
|
||||
}
|
||||
|
||||
const threshold = 256 // 定义一个阈值,用于区分小切片和大切片
|
||||
|
||||
// 如果旧容量小于阈值,则直接将新容量设置为旧容量的两倍
|
||||
// 这种策略适用于小切片,可以快速扩容,减少扩容次数
|
||||
if oldCap < threshold {
|
||||
return doublecap
|
||||
}
|
||||
|
||||
// 对于大切片,使用更平滑的扩容策略,避免过度分配内存
|
||||
// 从 2 倍增长过渡到 1.25 倍增长。 此公式给出了两者之间的平滑过渡。
|
||||
for {
|
||||
// 每次循环,将新容量增加 (newcap + 3*threshold) / 4
|
||||
// 相当于 newcap 增加 1/4 的比例,再加上 3/4 的 threshold(256),即 192
|
||||
// 这样可以在一定程度上减少内存浪费,并保证切片的增长
|
||||
newcap += (newcap + 3*threshold) >> 2
|
||||
|
||||
// Check for overflow and determine if the new calculated capacity
|
||||
// is greater or equal to the required new length.
|
||||
// newLen is guaranteed to be larger than zero, hence
|
||||
// when newcap overflows then `uint(newcap) > uint(newLen)`.
|
||||
// This allows to check for both with the same comparison.
|
||||
|
||||
// 我们需要检查`newcap >= newLen`以及`newcap`是否溢出。
|
||||
// 保证 newLen 大于零,因此当 newcap 溢出时,'uint(newcap) > uint(newLen)'。
|
||||
// 这允许使用相同的比较来检查两者。
|
||||
|
||||
// 检查新容量是否大于等于所需的新长度,并且检查是否发生了溢出
|
||||
if uint(newcap) >= uint(newLen) {
|
||||
break // 如果新容量足够大,或者发生了溢出,则退出循环
|
||||
}
|
||||
}
|
||||
|
||||
// 当新容量计算溢出时,将新容量设置为请求的容量。
|
||||
// 如果计算过程中发生了溢出,则直接将新容量设置为所需的新长度,以确保切片能够容纳所有元素
|
||||
if newcap <= 0 {
|
||||
return newLen
|
||||
}
|
||||
|
||||
return newcap // 返回计算得到的新容量
|
||||
}
|
||||
```
|
||||
|
||||
# Golang 切片原理
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 扩容规律
|
||||
|
||||
|
||||
|
||||
## 切片作为参数
|
||||
|
||||
Go 语言的函数参数传递,只有值传递,没有引用传递,切片作为参数也是如此
|
||||
|
||||
我们来验证这一点
|
||||
|
||||
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
sl := []int{6, 6, 6}
|
||||
f(sl)
|
||||
fmt.Println(sl)
|
||||
}
|
||||
|
||||
func f(sl []int) {
|
||||
for i := 0; i < 3; i++ {
|
||||
sl = append(sl, i)
|
||||
}
|
||||
fmt.Println(sl)
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
可以看到,输出的 sl 的值是不一样的,也就是说,f 函数没能修改主函数中的 sl 变量,而只是修改了形参 sl 变量的内容
|
||||
|
||||
当我们传递一个切片给函数的时候,函数接收到的其实是这个切片的一个副本,但是他们的 array 字段指向的是同一个底层数组。
|
||||
|
||||
这意味着,如果我们修改底层数组,是会影响到实参和形参的。
|
||||
|
||||
我们看下面的例子:形参通过改变底层数组影响实参
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
sl := []int{6, 6, 6}
|
||||
f(sl)
|
||||
fmt.Println(sl)
|
||||
}
|
||||
|
||||
func f(sl []int) {
|
||||
sl[1] = 1
|
||||
sl[2] = 2
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 通过指针传递影响实参
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
sl := []int{6, 6, 6}
|
||||
f(&sl)
|
||||
fmt.Println(sl)
|
||||
}
|
||||
|
||||
func f(sl *[]int) {
|
||||
*sl = append(*sl, 200)
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||
244
src/content/posts/Golang/Golang垃圾回收机制.md
Normal file
244
src/content/posts/Golang/Golang垃圾回收机制.md
Normal file
@@ -0,0 +1,244 @@
|
||||
---
|
||||
title: Golang垃圾回收机制
|
||||
published: 2025-07-19
|
||||
description: ''
|
||||
image: 'https://blog.meowrain.cn/api/i/2025/07/19/uje4vo-1.webp'
|
||||
tags: [垃圾回收, Golang, GC]
|
||||
category: 'Go'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# Go GC机制
|
||||
|
||||
> [5、Golang三色标记混合写屏障GC模式全分析 (yuque.com)](https://www.yuque.com/aceld/golang/zhzanb#77fdf35b)
|
||||
|
||||
> 垃圾回收(Garbage Collection,简称GC)是编程语言中提供的自动的内存管理机制,自动释放不需要的内存对象,让出存储器资源。GC过程中无需程序员手动执行。GC机制在现代很多编程语言都支持,GC能力的性能与优劣也是不同语言之间对比度指标之一。
|
||||
|
||||
## 发展过程
|
||||
|
||||
Go V1.3之前的标记-清除(mark and sweep)算法,Go V1.3之前的标记-清扫(mark and sweep)的缺点
|
||||
|
||||
## Go V1.3之前的标记-清除(mark and sweep)算法
|
||||
|
||||

|
||||
|
||||
接下来我们来看一下在Golang1.3之前的时候主要用的普通的标记-清除算法,此算法主要有两个主要的步骤:
|
||||
|
||||
- 标记(Mark phase)
|
||||
- 清除(Sweep phase)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
> STW会对可达对象做上标记,然后对不可达对象进行GC回收
|
||||
|
||||
|
||||
|
||||
> 操作非常简单,但是有一点需要额外注意:mark and sweep算法在执行的时候,需要程序暂停!即 `STW(stop the world)`,STW的过程中,CPU不执行用户代码,全部用于垃圾回收,这个过程的影响很大,所以STW也是一些回收机制最大的难题和希望优化的点。所以在执行第三步的这段时间,程序会暂定停止任何工作,卡在那等待回收执行完毕。
|
||||
|
||||
### mark and sweep 算法 缺点
|
||||
|
||||
1. STW会让程序暂停,使程序出现卡顿(重要问题)
|
||||
2. 标记需要扫描整个heap
|
||||
3. 清除数据会产生heap碎片
|
||||
|
||||
stw暂停范围
|
||||
|
||||
|
||||
|
||||
从上图来看,全部的GC时间都是包裹在STW范围之内的,这样貌似程序暂停的时间过长,影响程序的运行性能。所以Go V1.3 做了简单的优化,将STW的步骤提前, 减少STW暂停的时间范围.如下所示
|
||||
|
||||
|
||||
|
||||
上图主要是将STW的步骤提前了一步,因为在Sweep清除的时候,可以不需要STW停止,因为这些对象已经是不可达对象了,不会出现回收写冲突等问题。
|
||||
|
||||
但是无论怎么优化,Go V1.3都面临这个一个重要问题,就是**mark-and-sweep 算法会暂停整个程序** 。
|
||||
|
||||
Go是如何面对并这个问题的呢?接下来G V1.5版本 就用**三色并发标记法**来优化这个问题.
|
||||
|
||||
## GoV1.5三色标记法
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 三色标记法无STW的问题
|
||||
|
||||
我们加入如果没有STW,那么也就不会再存在性能上的问题,那么接下来我们假设如果三色标记法不加入STW会发生什么事情?
|
||||
我们还是基于上述的三色并发标记法来说, 他是一定要依赖STW的. 因为如果不暂停程序, 程序的逻辑改变对象引用关系, 这种动作如果在标记阶段做了修改,会影响标记结果的正确性,我们来看看一个场景,如果三色标记法, 标记过程不使用STW将会发生什么事情?
|
||||
|
||||
我们把初始状态设置为已经经历了第一轮扫描,目前黑色的有对象1和对象4, 灰色的有对象2和对象7,其他的为白色对象,且对象2是通过指针p指向对象3的,如图所示。
|
||||
|
||||
|
||||
|
||||
现在如何三色标记过程不启动STW,那么在GC扫描过程中,任意的对象均可能发生读写操作,如图所示,在还没有扫描到对象2的时候,已经标记为黑色的对象4,此时创建指针q,并且指向白色的对象3。
|
||||
|
||||
|
||||
|
||||
与此同时灰色的对象2将指针p移除,那么白色的对象3实则就是被挂在了已经扫描完成的黑色的对象4下,如图所示。
|
||||
|
||||
|
||||
|
||||
然后我们正常指向三色标记的算法逻辑,将所有灰色的对象标记为黑色,那么对象2和对象7就被标记成了黑色,如图所示。
|
||||
|
||||
|
||||
|
||||
那么就执行了三色标记的最后一步,将所有白色对象当做垃圾进行回收,如图所示。
|
||||
|
||||
|
||||
|
||||
但是最后我们才发现,本来是对象4合法引用的对象3,却被GC给“误杀”回收掉了。
|
||||
|
||||
### GC误杀条件
|
||||
|
||||
可以看出,有两种情况,在三色标记法中,是不希望被发生的。
|
||||
|
||||
- 条件1: 一个白色对象被黑色对象引用**(白色被挂在黑色下)**
|
||||
- 条件2: 灰色对象与它之间的可达关系的白色对象遭到破坏**(灰色同时丢了该白色)**
|
||||
如果当以上两个条件同时满足时,就会出现对象丢失现象!
|
||||
|
||||
## 屏障机制
|
||||
|
||||
> 为了防止这种现象的发生,最简单的方式就是STW,直接禁止掉其他用户程序对对象引用关系的干扰,但是**STW的过程有明显的资源浪费,对所有的用户程序都有很大影响**。那么是否可以在保证对象不丢失的情况下合理的尽可能的提高GC效率,减少STW时间呢?答案是可以的,我们只要使用一种机制,尝试去破坏上面的两个必要条件就可以了。
|
||||
|
||||
|
||||
|
||||
### 强三色不变式
|
||||
|
||||
强制性的不允许黑色对象引用白色对象
|
||||
|
||||
> 破坏条件1
|
||||
|
||||

|
||||
|
||||
### 弱三色不变式
|
||||
|
||||
黑色对象可以引用白色对象,但是要保证白色独享存在其它灰色对象对它的引用,或者可达它的链路上游存在灰色对象
|
||||
|
||||
> 破坏条件2
|
||||
|
||||
|
||||
|
||||
为了遵循上述的两个方式,GC算法演进到两种屏障方式,他们“插入屏障”, “删除屏障”。
|
||||
|
||||

|
||||
|
||||
### 插入屏蔽
|
||||
|
||||
> 不在栈上使用
|
||||
|
||||
`具体操作`: 在A对象引用B对象的时候,B对象被标记为灰色。(将B挂在A下游,B必须被标记为灰色)
|
||||
|
||||
`满足`: **强三色不变式**. (不存在黑色对象引用白色对象的情况了, 因为白色会强制变成灰色)
|
||||
|
||||
```go
|
||||
添加下游对象(当前下游对象slot, 新下游对象ptr) {
|
||||
//1
|
||||
标记灰色(新下游对象ptr)
|
||||
|
||||
//2
|
||||
当前下游对象slot = 新下游对象ptr
|
||||
}
|
||||
```
|
||||
|
||||
这里说一下这个过程,首先因为插入屏障不在栈上使用
|
||||
|
||||
下面的图里面,已经进行了一次三色标记,外界向对象4添加对象8,对象1添加对象9,但是我们知道,对象1在栈上,所以它不会应用插入屏障,也就是说,这个时候对象 9不会按照插入屏障的规则设置为灰色,而对象4在堆上,因此它会应用插入屏障,所以会把对象8设置为灰色,然后我们进行第二次三色标记,从灰色对象出发(对象2,对象7,对象8) ,找可达对象(对象3),因此将对象3设置为灰色,然后对象2,7,8设置为黑色,接着进行第三次三色标记,从灰色对象出发(对象3),发现没有可达对象,因此设置对象3为黑色,这个时候我们有黑色对象: 对象1,对象2,对象3,对象4,对象7,对象8.
|
||||
|
||||
按照常理我们这个时候应该进行垃圾回收了对吧,其实不然,我们这个时候要把栈空间的对象全部设置为白色,然后使用STW暂停栈空间(对象1,对象2,对象3,对象9,对象5),防止外界干扰(再有对象被添加到黑色对象下)
|
||||
|
||||
然后我们对栈空间重新进行一次三色标记,直到没有灰色对象
|
||||
|
||||
过程如下:
|
||||
|
||||
从对象1出发,设置对象1为灰色,接下来看从对象1走的可达对象,发现可达对象有对象2和对象9,因此我们把对象2和对象9设置为灰色对象,把对象1设置为黑色对象,然后我们再从灰色对象出发(对象2和对象9),发现对象2可达对象3,对象9没有可达对象,因此把对象3设置为灰色对象,对象2,9设置为黑色对象,接下来从灰色对象(此时只有对象3)出发,发现对象3没有可达对象,设置对象3为黑色对象。至此栈里面已经没有灰色对象,我们先暂停STW,然后进行最后的GC回收,可以发现白色对象只有 对象5,对象6,因此对白色对象进行清除。
|
||||
|
||||
至此,GC三色标记并发情况下的插入屏障流程完毕
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
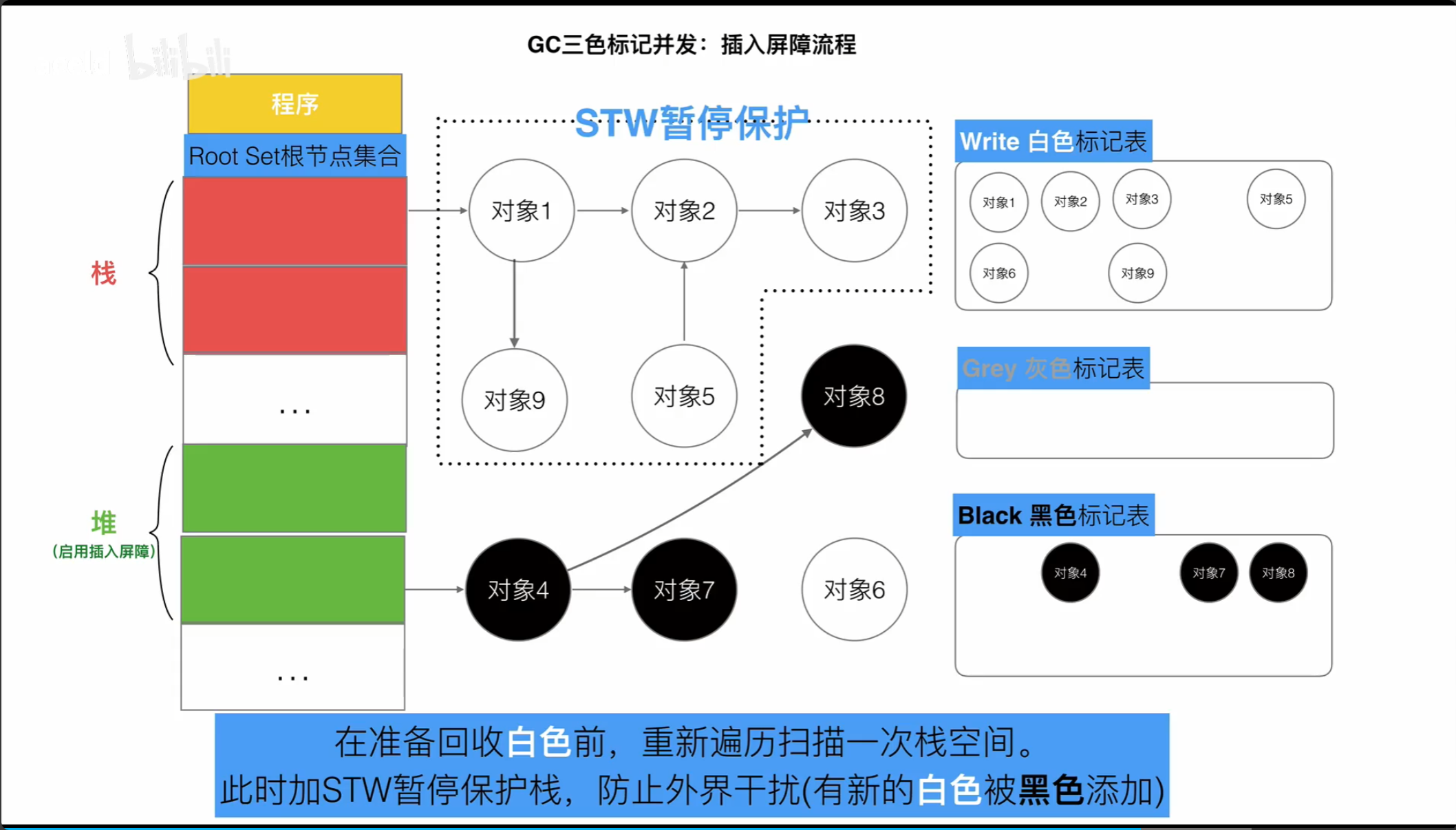
|
||||
|
||||
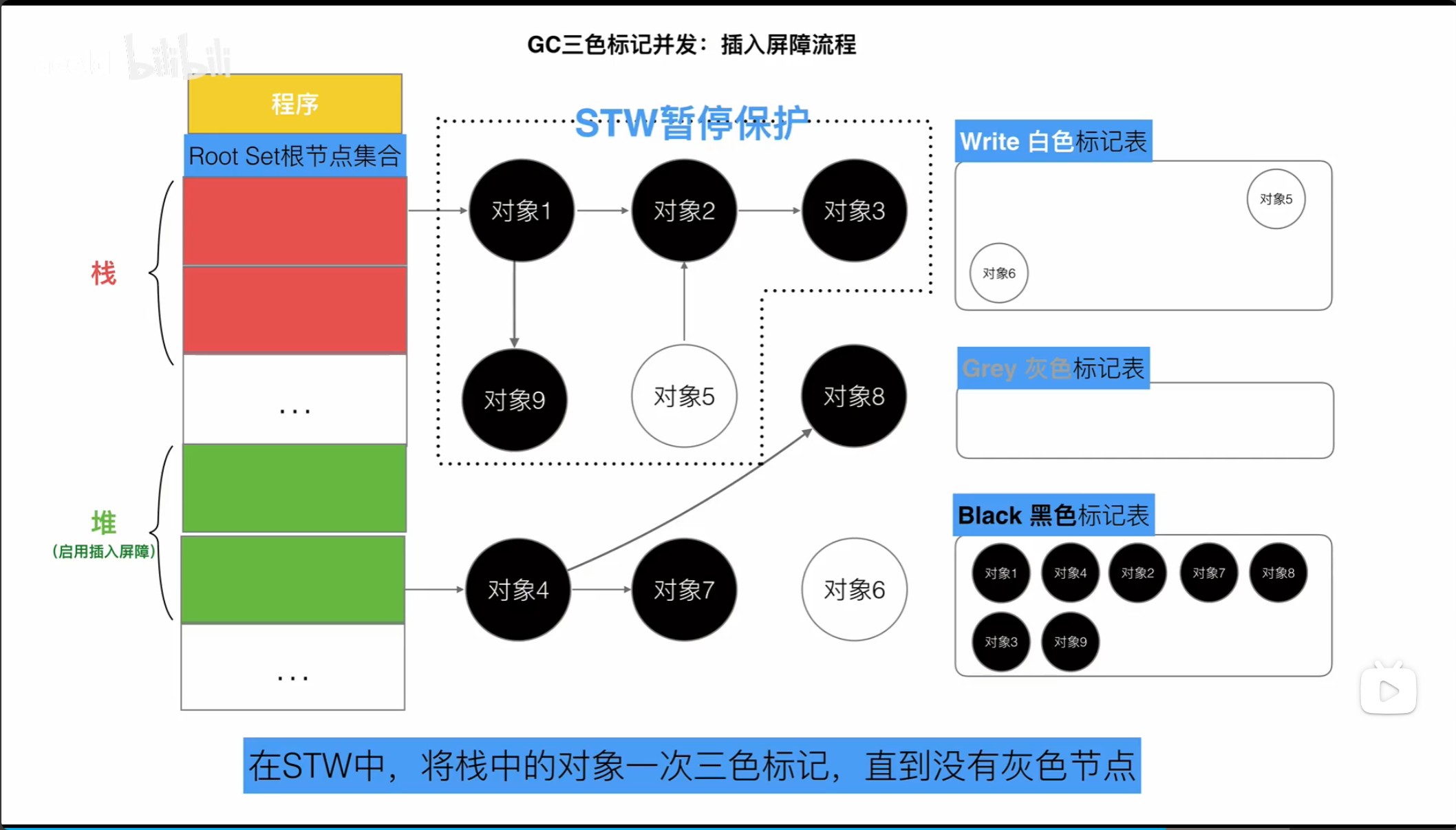
|
||||
|
||||
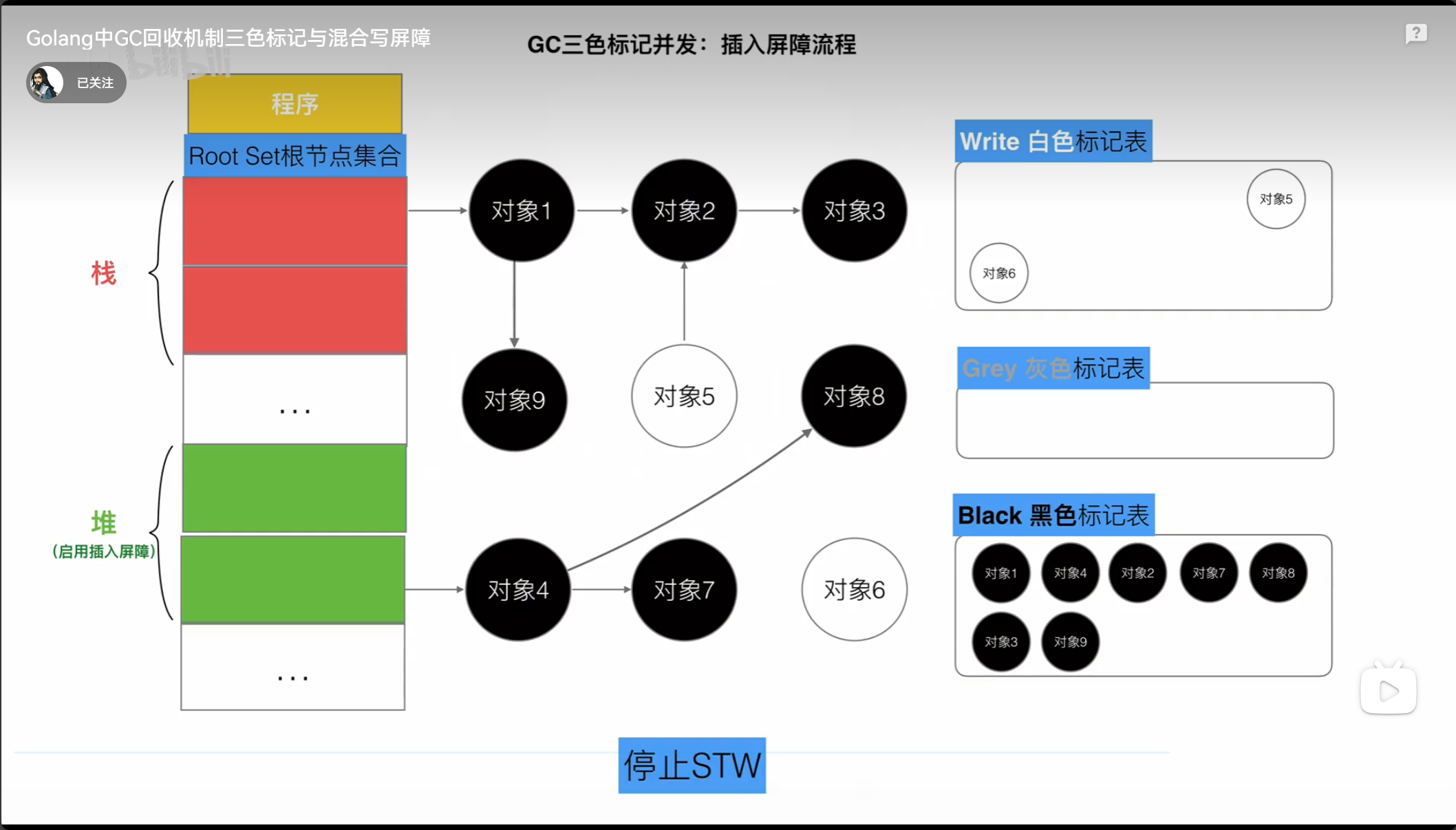
|
||||
|
||||
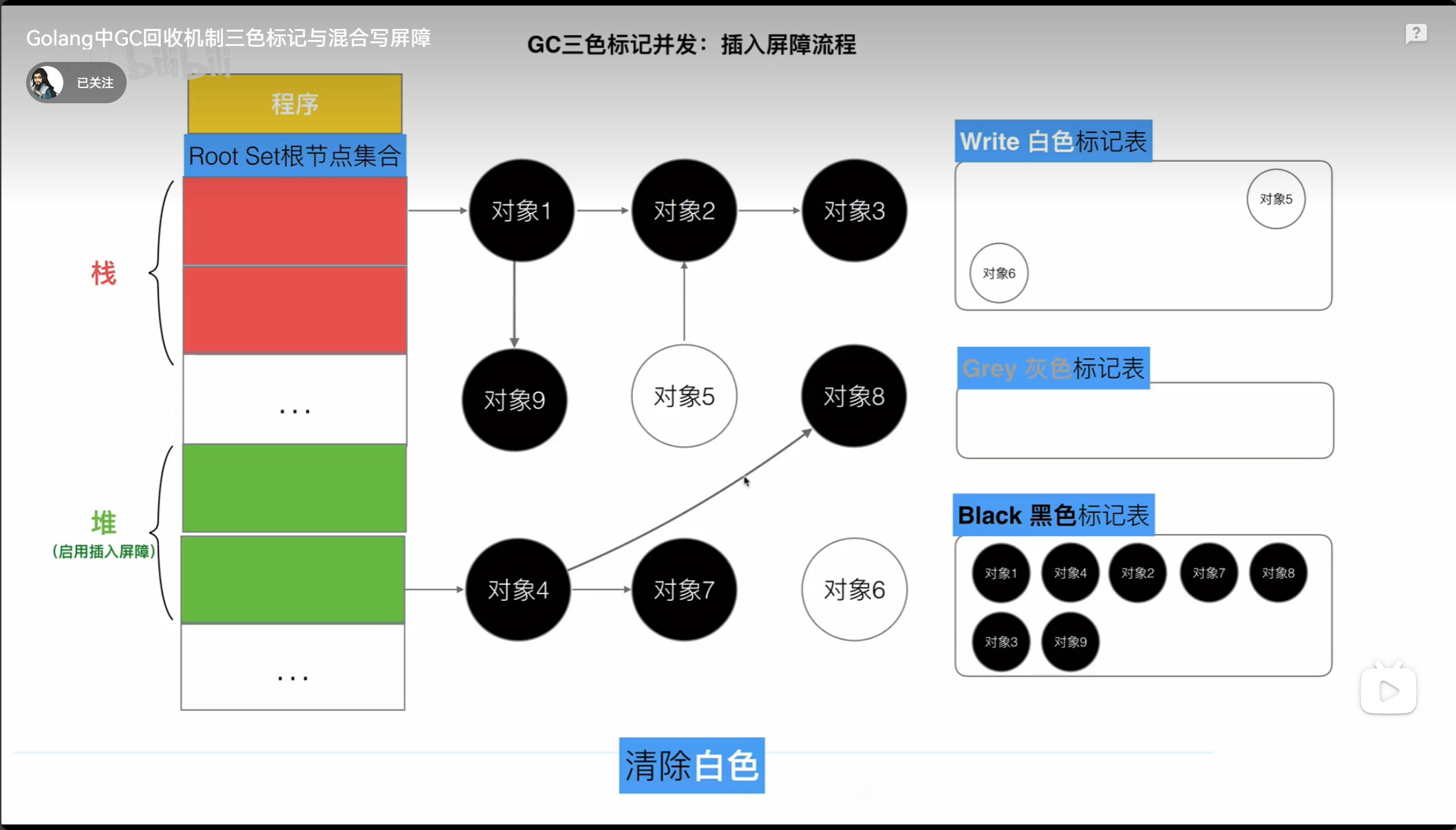
|
||||
|
||||
### 删除屏蔽
|
||||
|
||||
`具体操作`: 被删除的对象,如果自身为灰色或者白色,那么被标记为灰色。
|
||||
|
||||
`满足`: **弱三色不变式**. (保护灰色对象到白色对象的路径不会断)
|
||||
|
||||
```
|
||||
添加下游对象(当前下游对象slot, 新下游对象ptr) {
|
||||
//1
|
||||
if (当前下游对象slot是灰色 || 当前下游对象slot是白色) {
|
||||
标记灰色(当前下游对象slot) //slot为被删除对象, 标记为灰色
|
||||
}
|
||||
|
||||
//2
|
||||
当前下游对象slot = 新下游对象ptr
|
||||
}
|
||||
```
|
||||
|
||||
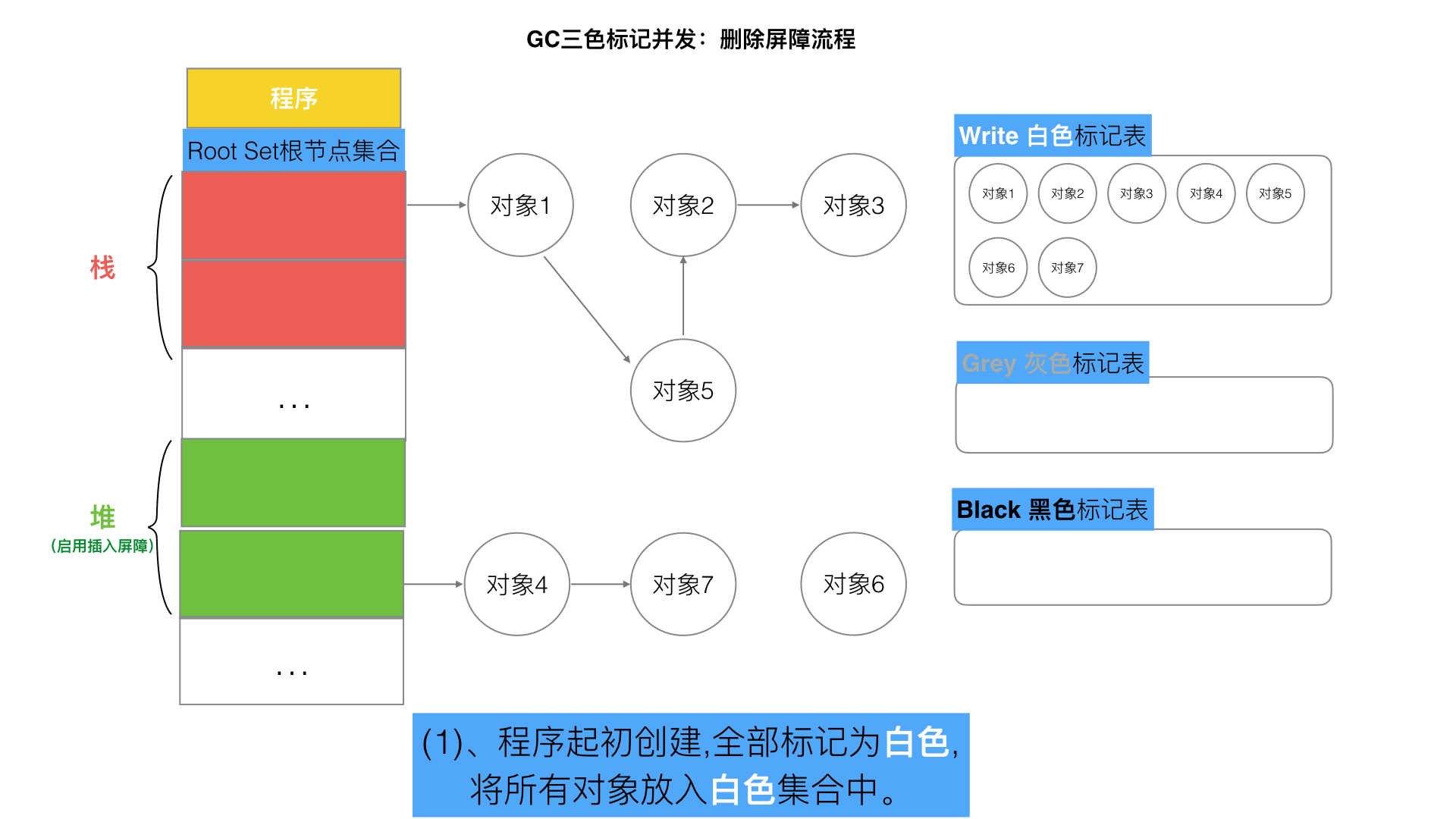
|
||||
|
||||
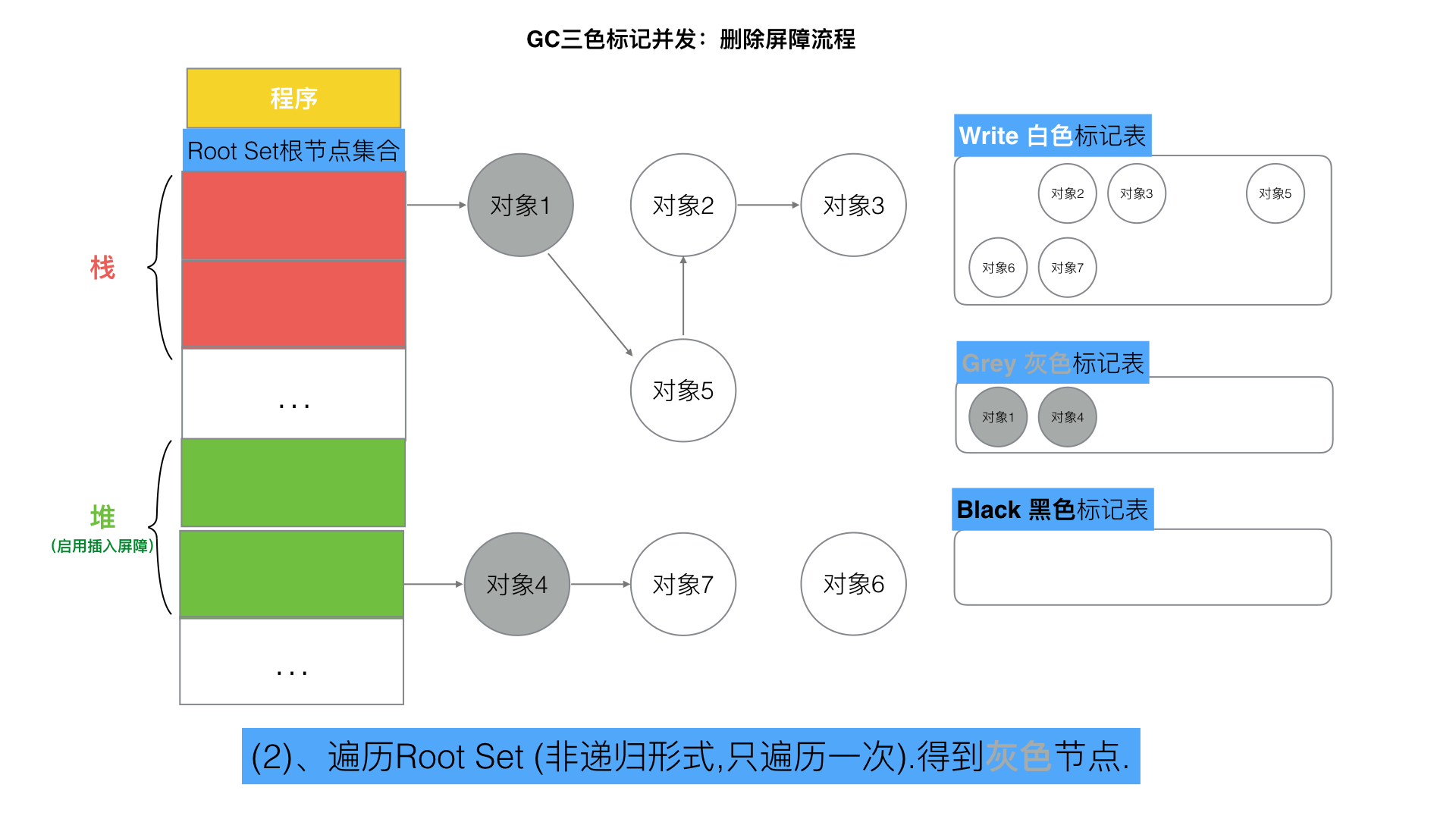
|
||||
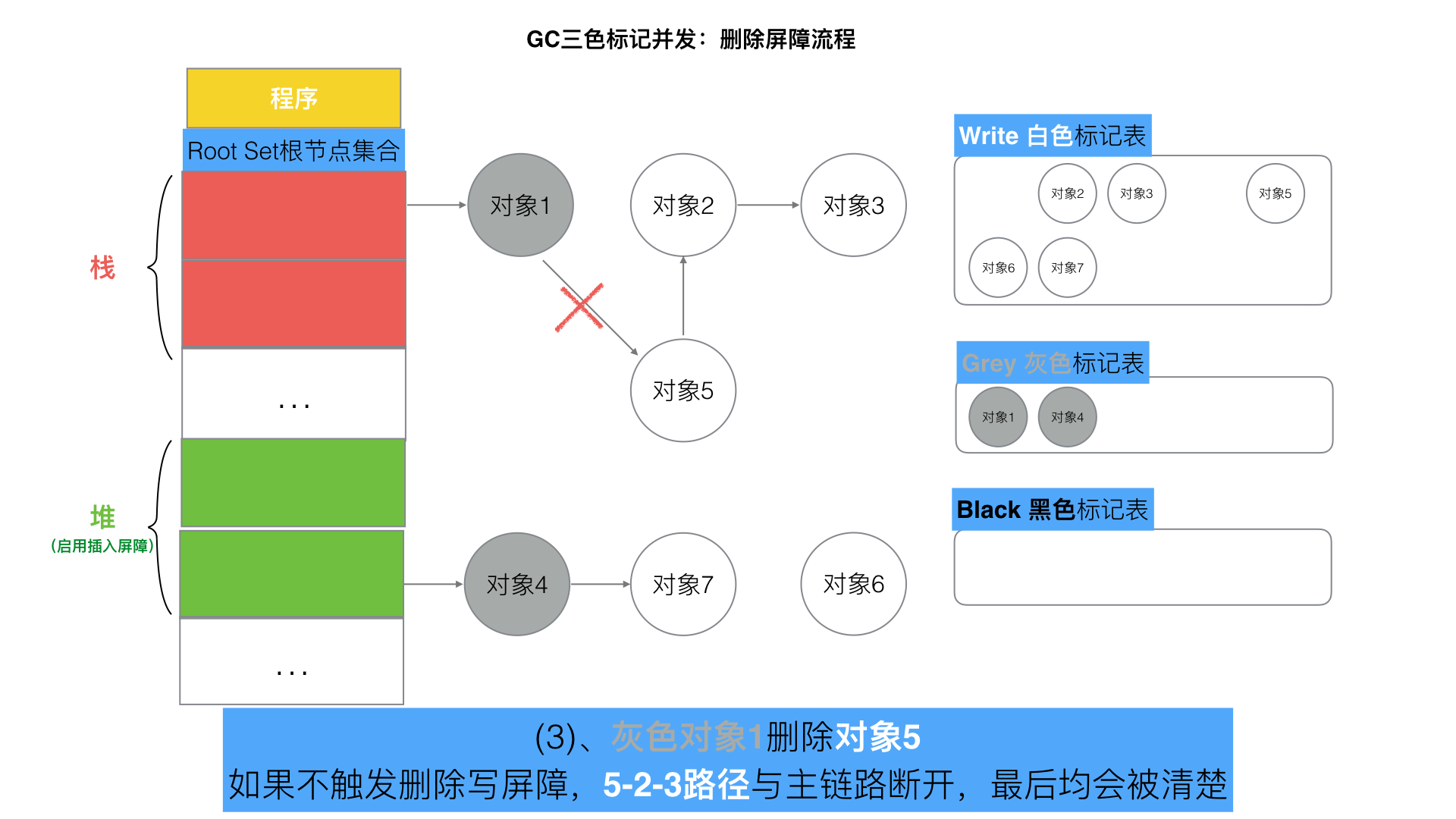
|
||||
|
||||
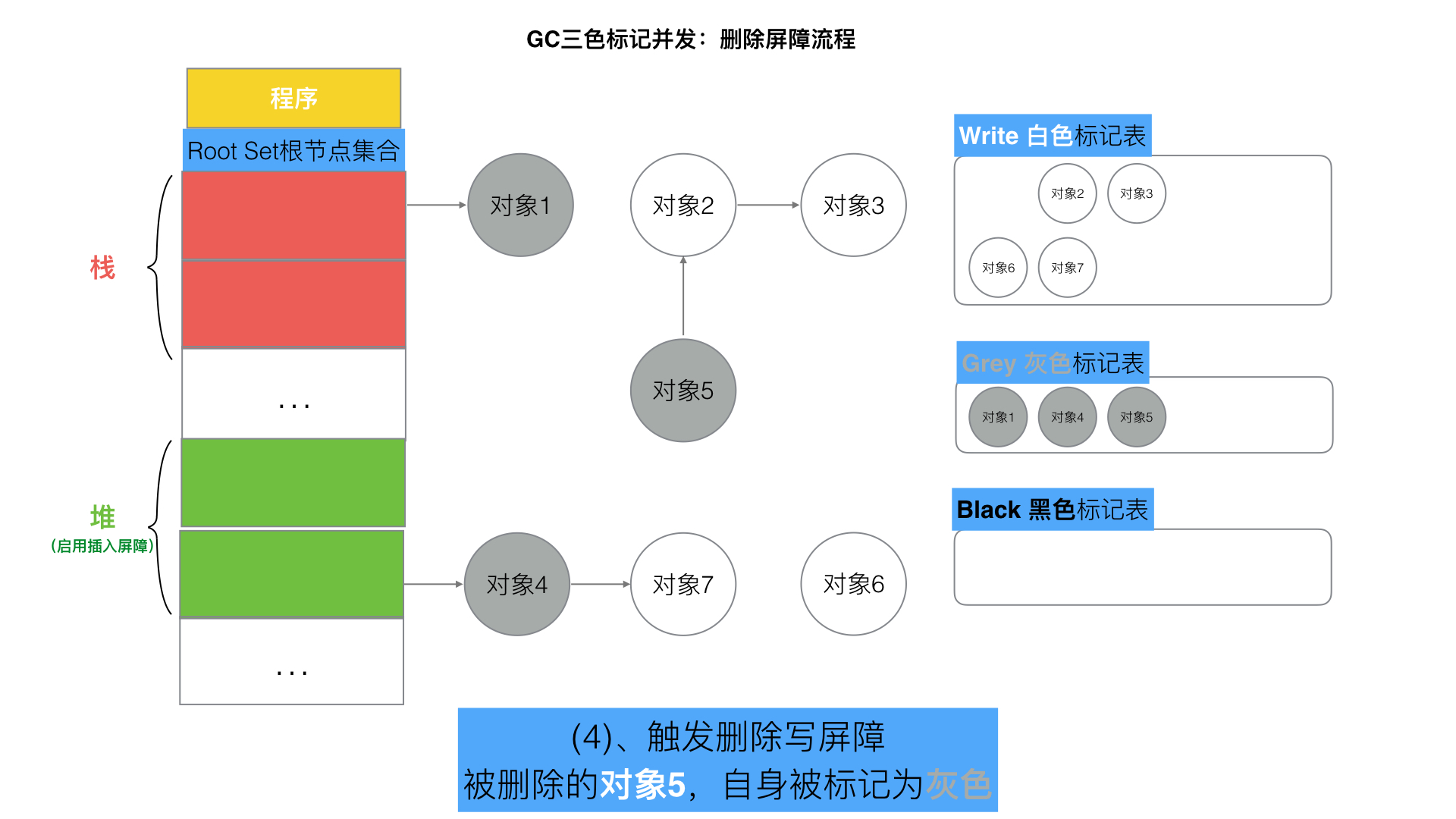
|
||||
|
||||
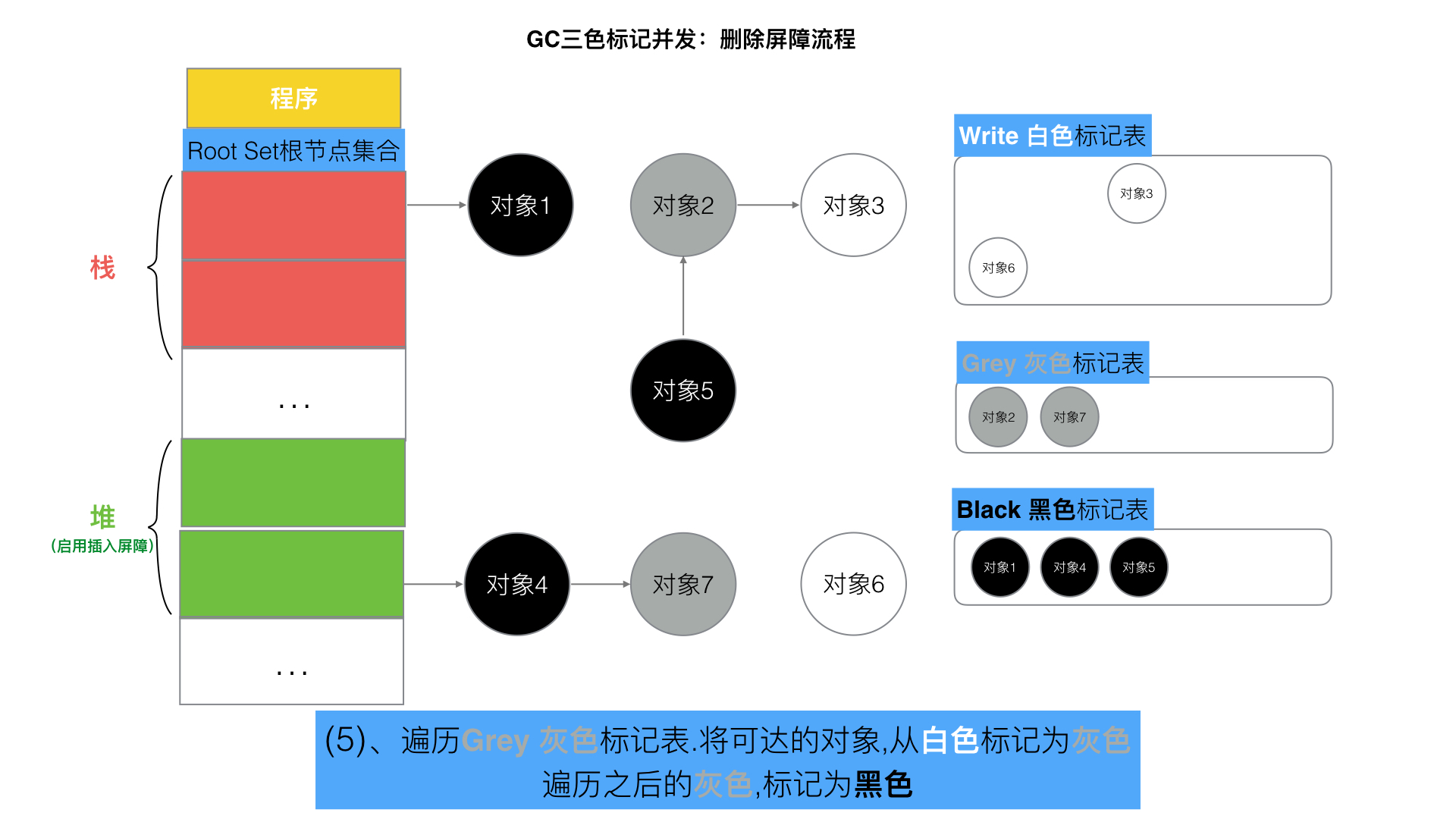
|
||||
|
||||
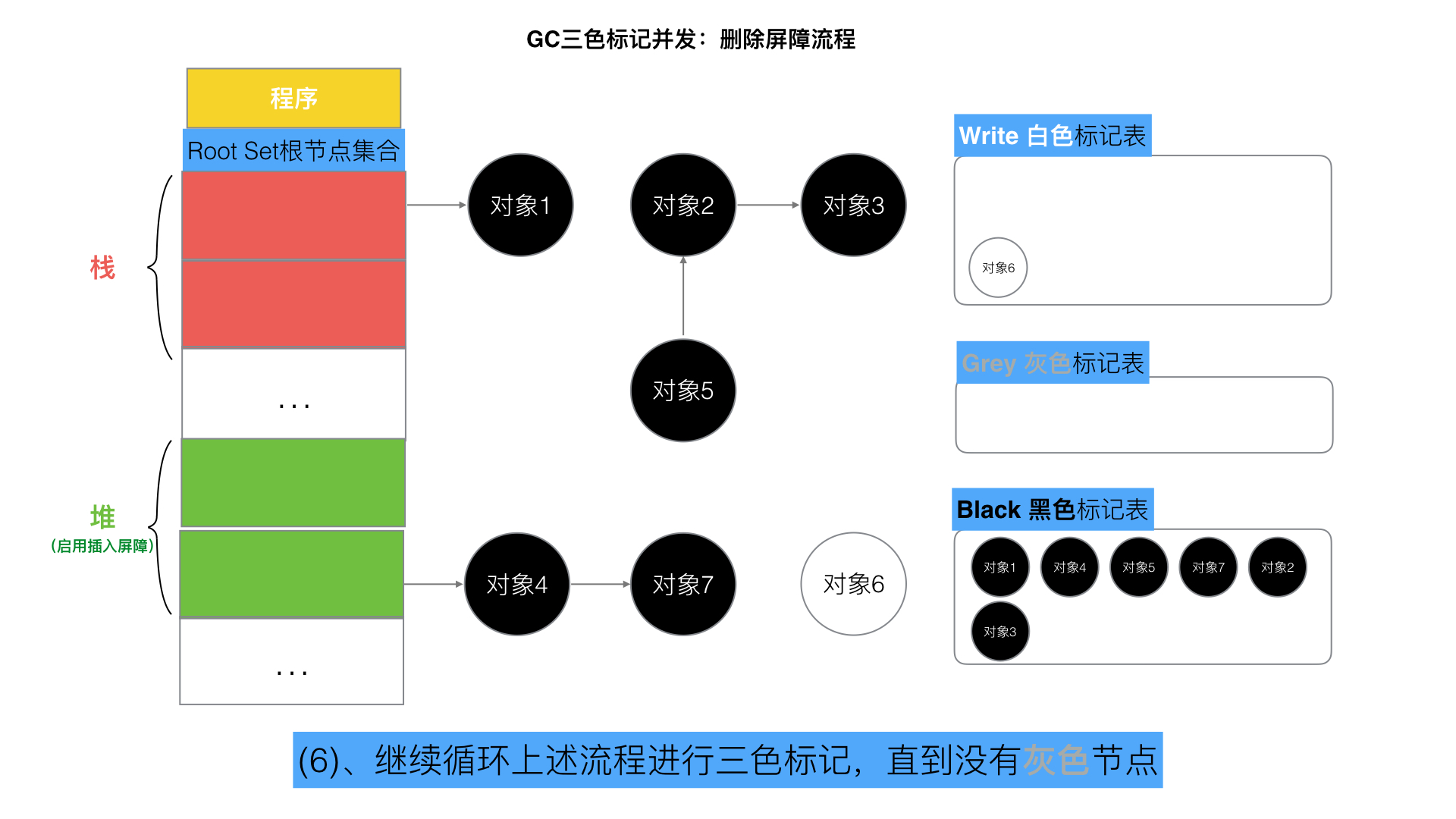
|
||||
|
||||
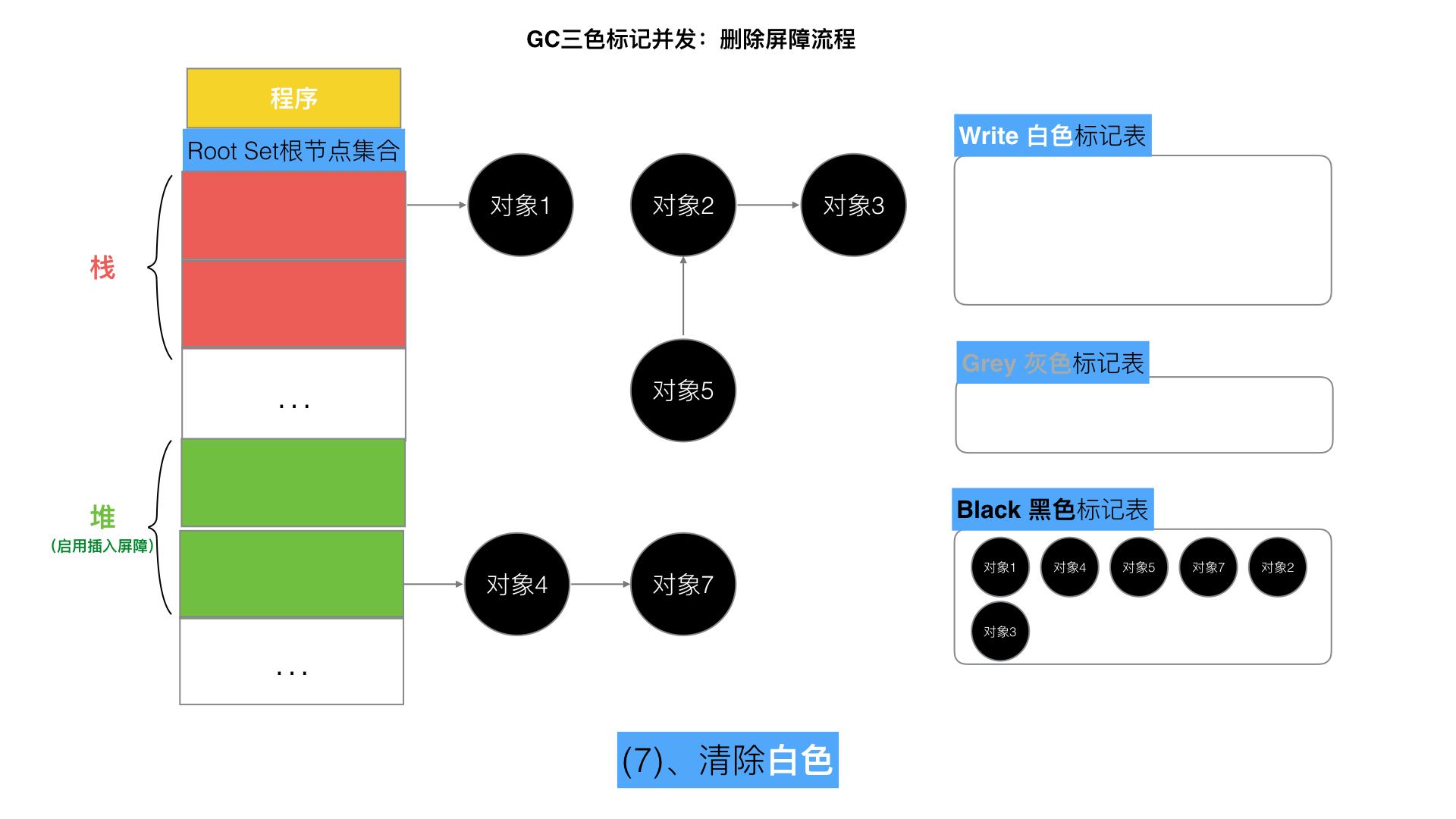
|
||||
|
||||
这种方式的回收精度低,一个对象即使被删除了最后一个指向它的指针也依旧可以活过这一轮,在下一轮GC中被清理掉。
|
||||
|
||||
### 混合屏障Go V1.8
|
||||
|
||||
插入写屏障和删除写屏障的短板:
|
||||
|
||||
● 插入写屏障:结束时需要STW来重新扫描栈,标记栈上引用的白色对象的存活;
|
||||
● 删除写屏障:回收精度低,GC开始时STW扫描堆栈来记录初始快照,这个过程会保护开始时刻的所有存活对象。
|
||||
|
||||
Go V1.8版本引入了混合写屏障机制(hybrid write barrier),避免了对栈re-scan的过程,极大的减少了STW的时间。结合了两者的优点。
|
||||
|
||||

|
||||
|
||||
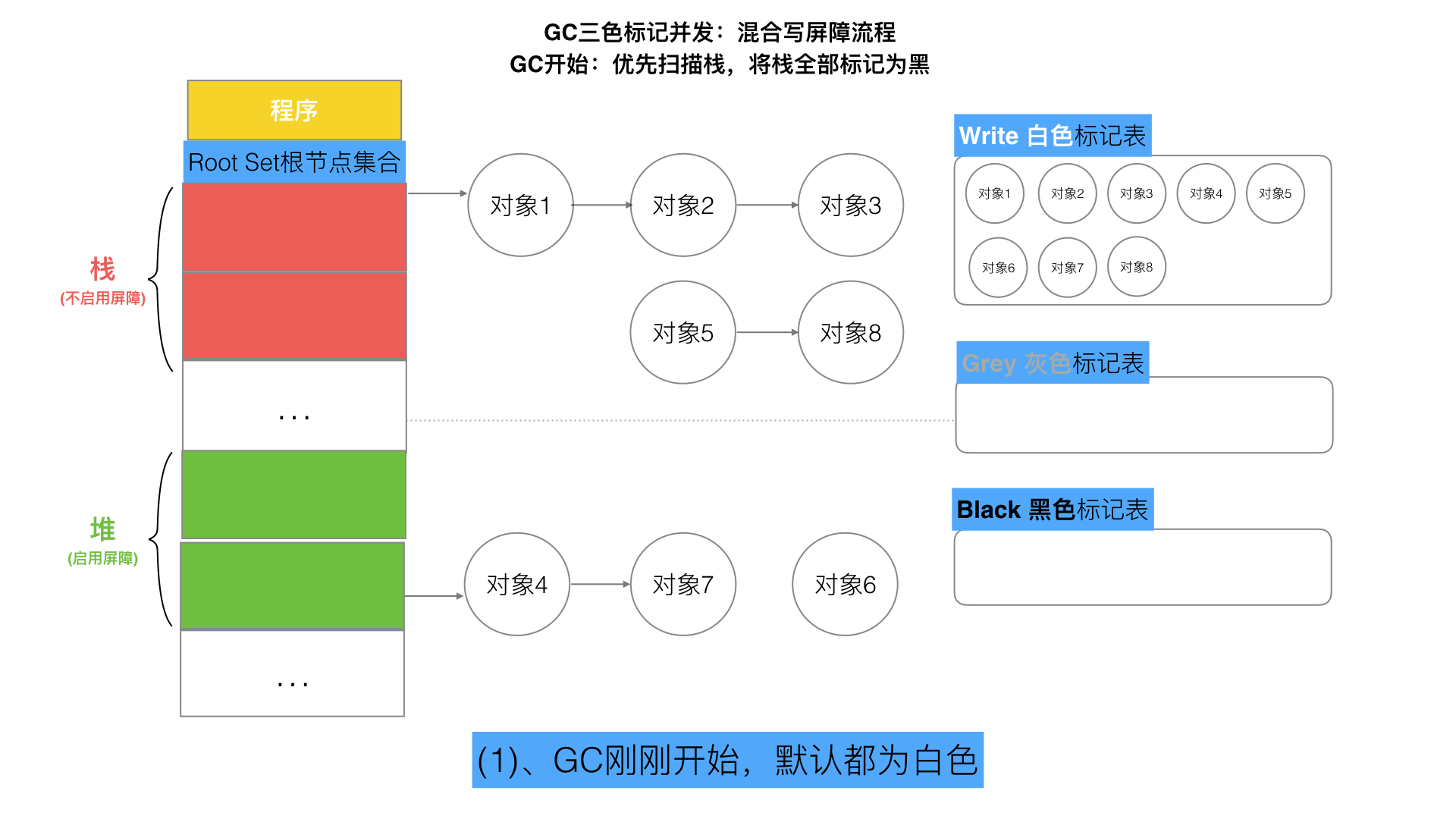
|
||||
|
||||
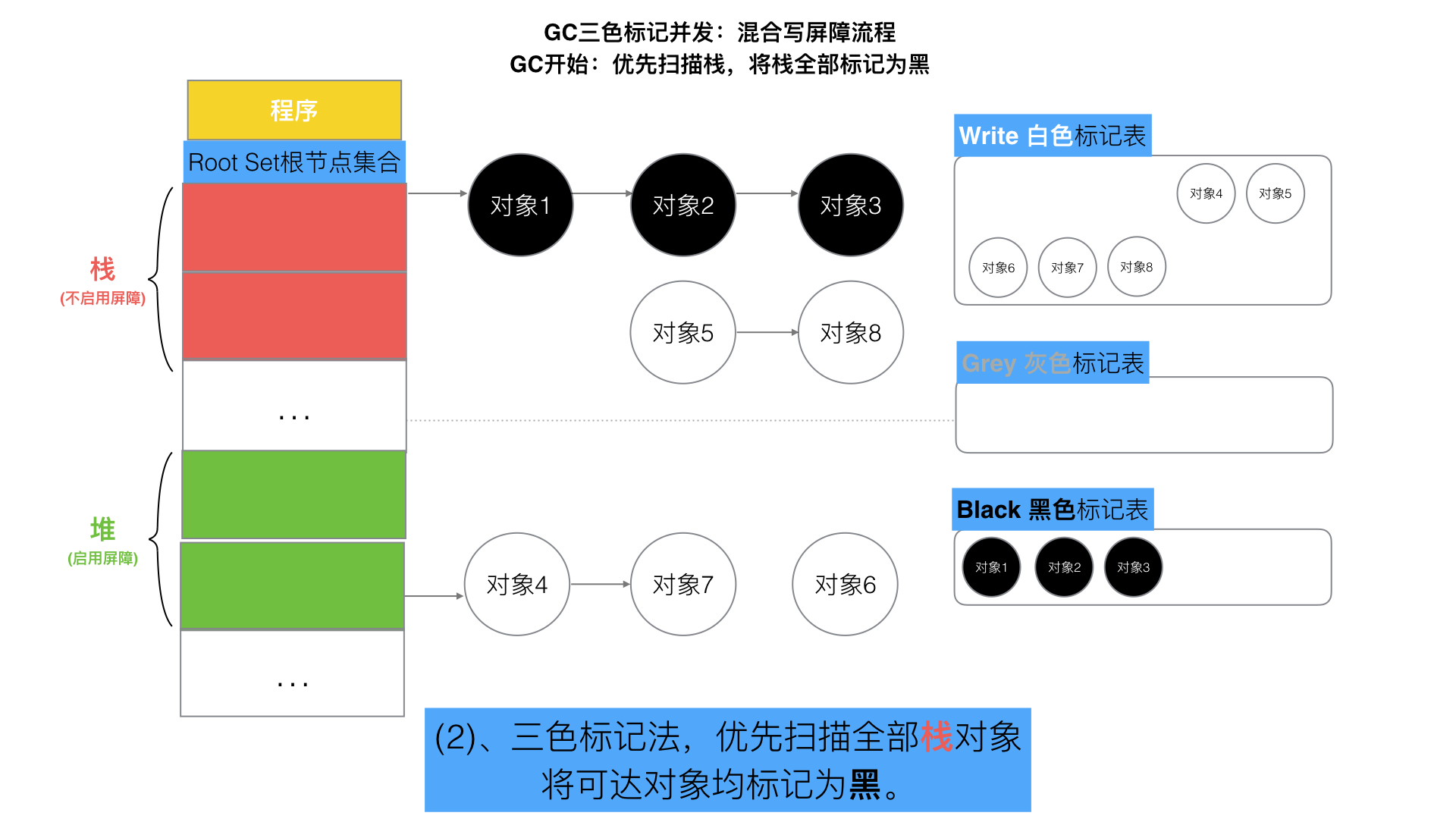
|
||||
|
||||
`具体操作`:
|
||||
|
||||
1、GC开始将栈上的对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW),
|
||||
|
||||
2、GC期间,任何在栈上创建的新对象,均为黑色。
|
||||
|
||||
3、被删除的对象标记为灰色。
|
||||
|
||||
4、被添加的对象标记为灰色。
|
||||
374
src/content/posts/Java/BigDecimal高精度计算.md
Normal file
374
src/content/posts/Java/BigDecimal高精度计算.md
Normal file
@@ -0,0 +1,374 @@
|
||||
---
|
||||
title: BigDecimal高精度计算
|
||||
published: 2025-07-26
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['Java', '面试','高精度计算','BigDecimal']
|
||||
category: 'Java > 面试题'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
https://javaguide.cn/java/basis/bigdecimal.html
|
||||
|
||||
# BigDecimal详解
|
||||
Java中,浮点数的运算有精度丢失的风险
|
||||
|
||||
为什么浮点数运算的时候会有精度丢失的风险?
|
||||
计算机是二进制的,浮点数在计算机中是通过二进制的方式来表示的。但是,浮点数的表示方式是有限的,所以在进行浮点数运算的时候,会存在精度丢失的风险。
|
||||
|
||||
例如,在Java中,浮点数的表示方式是 IEEE 754 标准,使用 64 位二进制来表示一个浮点数。其中,1 位用于表示符号位,11 位用于表示指数位,52 位用于表示尾数位。但是,浮点数的表示方式是有限的,所以在进行浮点数运算的时候,会存在精度丢失的风险。
|
||||
|
||||
# BigDecimal 类的常用方法
|
||||
BigDecimal可以实现对小数的运算,不会造成精度损失
|
||||
|
||||
通常情况下,大部分需要小数精确运算结果的业务场景都是通过BigDecimal来做的。
|
||||
|
||||
《阿里巴巴 Java 开发手册》中提到:浮点数之间的等值判断,基本数据类型不能用 == 来比较,包装数据类型不能用 equals 来判断。
|
||||
|
||||
## 创建
|
||||
我们在使用BigDecimal的时候,需要注意以下几点:
|
||||
|
||||
1. 不能使用new BigDecimal(double)的方式来创建BigDecimal对象,因为double类型的精度是有限的,所以在创建BigDecimal对象的时候,会存在精度丢失的风险。
|
||||
|
||||
2. 可以使用new BigDecimal(String)的方式来创建BigDecimal对象,因为String类型的精度是无限的,所以在创建BigDecimal对象的时候,不会存在精度丢失的风险。
|
||||
|
||||
3. 可以使用BigDecimal的valueOf()方法来创建BigDecimal对象,因为valueOf()方法的参数是double类型,但是在内部会将double类型的参数转换为String类型,所以在创建BigDecimal对象的时候,不会存在精度丢失的风险。
|
||||
|
||||

|
||||
|
||||
## 加减乘除
|
||||
add
|
||||
subtract
|
||||
multiply
|
||||
divide
|
||||
|
||||
divide可以指定保留的小数位数,以及四舍五入的方式。
|
||||
```java
|
||||
public BigDecimal divide(BigDecimal divisor, int scale, RoundingMode roundingMode) {
|
||||
return divide(divisor, scale, roundingMode.oldMode);
|
||||
}
|
||||
```
|
||||
|
||||
我们使用 divide 方法的时候尽量使用 3 个参数版本,并且RoundingMode 不要选择 UNNECESSARY,否则很可能会遇到 ArithmeticException(无法除尽出现无限循环小数的时候),其中 scale 表示要保留几位小数,roundingMode 代表保留规则。
|
||||
|
||||
scale是保留几位小数,roundingMode是保留规则。
|
||||
|
||||
roundingMode:
|
||||
- UP 向上四舍五入
|
||||
- DOWN 向下截取
|
||||
- CEILING 向上截取
|
||||
- FLOOR 向下截取
|
||||
- HALF_UP 四舍五入
|
||||
- HALF_DOWN 五舍六入
|
||||
- HALF_EVEN 四舍六入五取偶
|
||||
|
||||
# RoundingMode枚举详解 📚📊
|
||||
|
||||
## 各种舍入模式详细说明
|
||||
|
||||
### 1. UP - 向上舍入 ⬆️
|
||||
```java
|
||||
// 绝对值增大方向舍入,远离零的方向
|
||||
2.4 -> 3 // 正数向上
|
||||
1.6 -> 2 // 正数向上
|
||||
-1.6 -> -2 // 负数向更小(绝对值更大)
|
||||
-2.4 -> -3 // 负数向更小
|
||||
```
|
||||
|
||||
### 2. DOWN - 向下舍入 ⬇️
|
||||
```java
|
||||
// 绝对值减小方向舍入,趋向零的方向
|
||||
2.4 -> 2 // 正数向下
|
||||
1.6 -> 1 // 正数向下
|
||||
-1.6 -> -1 // 负数向更大(绝对值更小)
|
||||
-2.4 -> -2 // 负数向更大
|
||||
```
|
||||
|
||||
### 3. CEILING - 向正无穷舍入 ☁️
|
||||
```java
|
||||
// 向数轴右侧舍入
|
||||
2.4 -> 3 // 正数向上
|
||||
1.6 -> 2 // 正数向上
|
||||
-1.6 -> -1 // 负数向更大(向右)
|
||||
-2.4 -> -2 // 负数向更大
|
||||
```
|
||||
|
||||
### 4. FLOOR - 向负无穷舍入 ⚡
|
||||
```java
|
||||
// 向数轴左侧舍入
|
||||
2.4 -> 2 // 正数向下
|
||||
1.6 -> 1 // 正数向下
|
||||
-1.6 -> -2 // 负数向更小(向左)
|
||||
-2.4 -> -3 // 负数向更小
|
||||
```
|
||||
|
||||
### 5. HALF_UP - 四舍五入 🎯
|
||||
```java
|
||||
// 遇5向上舍入
|
||||
2.4 -> 2 // 小于5,向下
|
||||
2.5 -> 3 // 等于5,向上
|
||||
2.6 -> 3 // 大于5,向上
|
||||
-1.5 -> -2 // 负数也一样,-1.5 -> -2
|
||||
-1.4 -> -1 // -1.4 -> -1
|
||||
```
|
||||
|
||||
## 实际代码示例 💡
|
||||
|
||||
```java
|
||||
import java.math.BigDecimal;
|
||||
import java.math.RoundingMode;
|
||||
|
||||
public class RoundingModeDemo {
|
||||
public static void main(String[] args) {
|
||||
BigDecimal[] testNumbers = {
|
||||
new BigDecimal("2.4"),
|
||||
new BigDecimal("2.5"),
|
||||
new BigDecimal("2.6"),
|
||||
new BigDecimal("-1.4"),
|
||||
new BigDecimal("-1.5"),
|
||||
new BigDecimal("-1.6")
|
||||
};
|
||||
|
||||
for (BigDecimal num : testNumbers) {
|
||||
System.out.println("\n原数: " + num);
|
||||
System.out.println("UP: " + num.setScale(0, RoundingMode.UP));
|
||||
System.out.println("DOWN: " + num.setScale(0, RoundingMode.DOWN));
|
||||
System.out.println("CEILING: " + num.setScale(0, RoundingMode.CEILING));
|
||||
System.out.println("FLOOR: " + num.setScale(0, RoundingMode.FLOOR));
|
||||
System.out.println("HALF_UP: " + num.setScale(0, RoundingMode.HALF_UP));
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 输出结果展示 📊
|
||||
|
||||
```
|
||||
原数: 2.4
|
||||
UP: 3
|
||||
DOWN: 2
|
||||
CEILING: 3
|
||||
FLOOR: 2
|
||||
HALF_UP: 2
|
||||
|
||||
原数: 2.5
|
||||
UP: 3
|
||||
DOWN: 2
|
||||
CEILING: 3
|
||||
FLOOR: 2
|
||||
HALF_UP: 3
|
||||
|
||||
原数: -1.5
|
||||
UP: -2
|
||||
DOWN: -1
|
||||
CEILING: -1
|
||||
FLOOR: -2
|
||||
HALF_UP: -2
|
||||
```
|
||||
|
||||
## 使用场景建议 🎯
|
||||
|
||||
```java
|
||||
public class RoundingMode应用场景 {
|
||||
public static void main(String[] args) {
|
||||
// 金融计算 - 通常使用HALF_UP(银行家舍入)
|
||||
BigDecimal money = new BigDecimal("123.455");
|
||||
BigDecimal roundedMoney = money.setScale(2, RoundingMode.HALF_UP);
|
||||
|
||||
// 统计计算 - 可能使用HALF_EVEN(银行家舍入)
|
||||
BigDecimal average = new BigDecimal("87.345");
|
||||
BigDecimal roundedAvg = average.setScale(2, RoundingMode.HALF_EVEN);
|
||||
|
||||
// 科学计算 - 根据需要选择合适的模式
|
||||
BigDecimal scientific = new BigDecimal("99.999");
|
||||
BigDecimal ceilingResult = scientific.setScale(2, RoundingMode.CEILING);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
# BigDecimal等值比较
|
||||
使用compareTo进行比较,因为equals会比较值和精度,但是compareTo会忽略精度
|
||||
|
||||
compareTo() 方法可以比较两个 BigDecimal 的值,如果相等就返回 0,如果第 1 个数比第 2 个数大则返回 1,反之返回-1。
|
||||
|
||||
# BigDecimal工具类
|
||||
```java
|
||||
import java.math.BigDecimal;
|
||||
import java.math.RoundingMode;
|
||||
|
||||
/**
|
||||
* 简化BigDecimal计算的小工具类
|
||||
*/
|
||||
public class BigDecimalUtil {
|
||||
|
||||
/**
|
||||
* 默认除法运算精度
|
||||
*/
|
||||
private static final int DEF_DIV_SCALE = 10;
|
||||
|
||||
private BigDecimalUtil() {
|
||||
}
|
||||
|
||||
/**
|
||||
* 提供精确的加法运算。
|
||||
*
|
||||
* @param v1 被加数
|
||||
* @param v2 加数
|
||||
* @return 两个参数的和
|
||||
*/
|
||||
public static double add(double v1, double v2) {
|
||||
BigDecimal b1 = BigDecimal.valueOf(v1);
|
||||
BigDecimal b2 = BigDecimal.valueOf(v2);
|
||||
return b1.add(b2).doubleValue();
|
||||
}
|
||||
|
||||
/**
|
||||
* 提供精确的减法运算。
|
||||
*
|
||||
* @param v1 被减数
|
||||
* @param v2 减数
|
||||
* @return 两个参数的差
|
||||
*/
|
||||
public static double subtract(double v1, double v2) {
|
||||
BigDecimal b1 = BigDecimal.valueOf(v1);
|
||||
BigDecimal b2 = BigDecimal.valueOf(v2);
|
||||
return b1.subtract(b2).doubleValue();
|
||||
}
|
||||
|
||||
/**
|
||||
* 提供精确的乘法运算。
|
||||
*
|
||||
* @param v1 被乘数
|
||||
* @param v2 乘数
|
||||
* @return 两个参数的积
|
||||
*/
|
||||
public static double multiply(double v1, double v2) {
|
||||
BigDecimal b1 = BigDecimal.valueOf(v1);
|
||||
BigDecimal b2 = BigDecimal.valueOf(v2);
|
||||
return b1.multiply(b2).doubleValue();
|
||||
}
|
||||
|
||||
/**
|
||||
* 提供(相对)精确的除法运算,当发生除不尽的情况时,精确到
|
||||
* 小数点以后10位,以后的数字四舍六入五成双。
|
||||
*
|
||||
* @param v1 被除数
|
||||
* @param v2 除数
|
||||
* @return 两个参数的商
|
||||
*/
|
||||
public static double divide(double v1, double v2) {
|
||||
return divide(v1, v2, DEF_DIV_SCALE);
|
||||
}
|
||||
|
||||
/**
|
||||
* 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指
|
||||
* 定精度,以后的数字四舍六入五成双。
|
||||
*
|
||||
* @param v1 被除数
|
||||
* @param v2 除数
|
||||
* @param scale 表示表示需要精确到小数点以后几位。
|
||||
* @return 两个参数的商
|
||||
*/
|
||||
public static double divide(double v1, double v2, int scale) {
|
||||
if (scale < 0) {
|
||||
throw new IllegalArgumentException(
|
||||
"The scale must be a positive integer or zero");
|
||||
}
|
||||
BigDecimal b1 = BigDecimal.valueOf(v1);
|
||||
BigDecimal b2 = BigDecimal.valueOf(v2);
|
||||
return b1.divide(b2, scale, RoundingMode.HALF_EVEN).doubleValue();
|
||||
}
|
||||
|
||||
/**
|
||||
* 提供精确的小数位四舍六入五成双处理。
|
||||
*
|
||||
* @param v 需要四舍六入五成双的数字
|
||||
* @param scale 小数点后保留几位
|
||||
* @return 四舍六入五成双后的结果
|
||||
*/
|
||||
public static double round(double v, int scale) {
|
||||
if (scale < 0) {
|
||||
throw new IllegalArgumentException(
|
||||
"The scale must be a positive integer or zero");
|
||||
}
|
||||
BigDecimal b = BigDecimal.valueOf(v);
|
||||
BigDecimal one = new BigDecimal("1");
|
||||
return b.divide(one, scale, RoundingMode.HALF_UP).doubleValue();
|
||||
}
|
||||
|
||||
/**
|
||||
* 提供精确的类型转换(Float)
|
||||
*
|
||||
* @param v 需要被转换的数字
|
||||
* @return 返回转换结果
|
||||
*/
|
||||
public static float convertToFloat(double v) {
|
||||
BigDecimal b = new BigDecimal(v);
|
||||
return b.floatValue();
|
||||
}
|
||||
|
||||
/**
|
||||
* 提供精确的类型转换(Int)不进行四舍六入五成双
|
||||
*
|
||||
* @param v 需要被转换的数字
|
||||
* @return 返回转换结果
|
||||
*/
|
||||
public static int convertsToInt(double v) {
|
||||
BigDecimal b = new BigDecimal(v);
|
||||
return b.intValue();
|
||||
}
|
||||
|
||||
/**
|
||||
* 提供精确的类型转换(Long)
|
||||
*
|
||||
* @param v 需要被转换的数字
|
||||
* @return 返回转换结果
|
||||
*/
|
||||
public static long convertsToLong(double v) {
|
||||
BigDecimal b = new BigDecimal(v);
|
||||
return b.longValue();
|
||||
}
|
||||
|
||||
/**
|
||||
* 返回两个数中大的一个值
|
||||
*
|
||||
* @param v1 需要被对比的第一个数
|
||||
* @param v2 需要被对比的第二个数
|
||||
* @return 返回两个数中大的一个值
|
||||
*/
|
||||
public static double returnMax(double v1, double v2) {
|
||||
BigDecimal b1 = new BigDecimal(v1);
|
||||
BigDecimal b2 = new BigDecimal(v2);
|
||||
return b1.max(b2).doubleValue();
|
||||
}
|
||||
|
||||
/**
|
||||
* 返回两个数中小的一个值
|
||||
*
|
||||
* @param v1 需要被对比的第一个数
|
||||
* @param v2 需要被对比的第二个数
|
||||
* @return 返回两个数中小的一个值
|
||||
*/
|
||||
public static double returnMin(double v1, double v2) {
|
||||
BigDecimal b1 = new BigDecimal(v1);
|
||||
BigDecimal b2 = new BigDecimal(v2);
|
||||
return b1.min(b2).doubleValue();
|
||||
}
|
||||
|
||||
/**
|
||||
* 精确对比两个数字
|
||||
*
|
||||
* @param v1 需要被对比的第一个数
|
||||
* @param v2 需要被对比的第二个数
|
||||
* @return 如果两个数一样则返回0,如果第一个数比第二个数大则返回1,反之返回-1
|
||||
*/
|
||||
public static int compareTo(double v1, double v2) {
|
||||
BigDecimal b1 = BigDecimal.valueOf(v1);
|
||||
BigDecimal b2 = BigDecimal.valueOf(v2);
|
||||
return b1.compareTo(b2);
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
271
src/content/posts/Java/JUC/ABA问题.md
Normal file
271
src/content/posts/Java/JUC/ABA问题.md
Normal file
@@ -0,0 +1,271 @@
|
||||
---
|
||||
title: ABA问题
|
||||
published: 2025-07-19
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [JUC, ABA问题]
|
||||
category: 'Java > JUC'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# 介绍
|
||||
|
||||
ABA问题是并发编程中,在使用无锁(lock-free)算法,特别是基于 比较并交换(Compare-And-Swap, CAS) 操作时可能出现的一种逻辑错误。
|
||||
|
||||
它之所以被称为"ABA"问题,是因为一个变量的值从 A 变成了 B,然后又变回了 A。对于一个只检查当前值是否等于期望值的CAS操作来说,它会认为值没有发生变化,从而成功执行操作,但实际上变量在期间已经被修改过了。
|
||||
|
||||
## **ABA问题发生的场景及危害**
|
||||
|
||||
想象一个无锁的栈(Stack),其 `pop()` 操作需要原子地更新栈顶元素。
|
||||
|
||||
**假设初始状态:**
|
||||
栈顶 `top` 指向元素 `A`。
|
||||
|
||||
**正常 `pop` 操作流程:**
|
||||
|
||||
1. 线程1读取当前栈顶元素 `A`。
|
||||
2. 线程1准备将栈顶更新为 `A.next` (假设是 `null`)。
|
||||
3. 线程1执行 `top.compareAndSet(A, A.next)`,如果成功,`A` 被弹出。
|
||||
|
||||
**ABA问题发生过程:**
|
||||
|
||||
1. **线程1** 读取当前栈顶元素,发现是 `A`。它记下 `A`,并准备执行 `CAS(A, C)`。
|
||||
|
||||
```
|
||||
top -> A -> B -> D
|
||||
Thread 1 reads top: A
|
||||
```
|
||||
|
||||
2. **线程2** 此时突然执行,它将 `A` 弹出。
|
||||
|
||||
```
|
||||
top -> B -> D (A is now removed)
|
||||
Thread 2 pops A
|
||||
```
|
||||
|
||||
3. **线程2** 又将一个**新的元素 `A` (或者一个值和 `A` 相同但实际上是不同对象的元素)**压入栈。
|
||||
*注意:这里的“新的元素A”指的是一个与最开始的A值相同,但内存地址可能不同,或者即便内存地址相同,其内部状态已经发生过变化的对象。*
|
||||
|
||||
```
|
||||
top -> A -> B -> D (This A is NOT the original A, it's a new one!)
|
||||
Thread 2 pushes A back
|
||||
```
|
||||
|
||||
4. **线程1** 恢复执行 `CAS(A, C)`。它检查当前栈顶是否是它之前读取的 `A`。
|
||||
由于栈顶现在又指向了 `A`(尽管是新的 `A`),`compareAndSet` 操作会认为当前值等于期望值 `A`,并成功将栈顶更新为 `C`。
|
||||
|
||||
```
|
||||
top -> C (Thread 1's CAS(A, C) succeeds!)
|
||||
```
|
||||
|
||||
**危害:**
|
||||
尽管线程1的CAS操作成功了,但它操作的实际上是一个**新的 `A`**,而不是它最初读取的那个 `A`。如果 `A` 的内部状态(比如它的 `next` 指针)在这期间被改变了,那么线程1的后续操作可能会导致:
|
||||
|
||||
* **数据结构损坏**:例如,在链表中,节点指针可能指向错误的位置。
|
||||
* **逻辑错误**:程序基于过时的或不正确的状态信息做出决策。
|
||||
* **内存泄漏**:旧的 `A` (或其他被弹出又压入的元素)可能永远无法被垃圾回收。
|
||||
|
||||
---
|
||||
|
||||
```java
|
||||
package org.example.aba;
|
||||
|
||||
import java.util.concurrent.atomic.AtomicReference;
|
||||
|
||||
class Node {
|
||||
public final String item; // 节点内容
|
||||
public Node next; // 下一个节点的引用
|
||||
|
||||
public Node(String item) {
|
||||
this.item = item;
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString() {
|
||||
return item;
|
||||
}
|
||||
}
|
||||
|
||||
class LockFreeStackABA {
|
||||
private AtomicReference<Node> top = new AtomicReference<>();
|
||||
|
||||
// 压入栈顶
|
||||
public void push(String item) {
|
||||
Node newHead = new Node(item);
|
||||
Node oldHead;
|
||||
do {
|
||||
oldHead = top.get();
|
||||
newHead.next = oldHead;
|
||||
} while (!top.compareAndSet(oldHead, newHead));
|
||||
System.out.println(Thread.currentThread().getName() + " 压入: " + item + " (当前栈顶: " + top.get() + ")");
|
||||
}
|
||||
|
||||
// 弹出栈顶
|
||||
public Node pop() {
|
||||
Node oldHead;
|
||||
Node newHead;
|
||||
do {
|
||||
oldHead = top.get();
|
||||
if (oldHead == null) {
|
||||
System.out.println(Thread.currentThread().getName() + " 尝试弹出,但栈为空!");
|
||||
return null;
|
||||
}
|
||||
newHead = oldHead.next;
|
||||
System.out.println(Thread.currentThread().getName() + " 尝试弹出 " + oldHead.item +
|
||||
" (期望栈顶: " + oldHead + ", 更新栈顶至: " + newHead + ")");
|
||||
} while (!top.compareAndSet(oldHead, newHead)); // CAS操作:如果当前栈顶仍是oldHead,则更新为newHead
|
||||
System.out.println(Thread.currentThread().getName() + " 成功弹出: " + oldHead.item + " (当前栈顶: " + top.get() + ")");
|
||||
return oldHead;
|
||||
}
|
||||
|
||||
// 打印栈内容
|
||||
public void printStack() {
|
||||
System.out.print("当前栈: ");
|
||||
Node current = top.get();
|
||||
if (current == null) {
|
||||
System.out.println("空");
|
||||
return;
|
||||
}
|
||||
StringBuilder sb = new StringBuilder();
|
||||
while (current != null) {
|
||||
sb.append(current.item).append(" -> ");
|
||||
current = current.next;
|
||||
}
|
||||
sb.setLength(sb.length() - 4); // 移除最后的 " -> "
|
||||
System.out.println(sb.toString());
|
||||
}
|
||||
|
||||
// 获取栈顶节点
|
||||
public Node getTop() {
|
||||
return top.get();
|
||||
}
|
||||
}
|
||||
|
||||
public class AbaAppear {
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
LockFreeStackABA stack = new LockFreeStackABA();
|
||||
|
||||
// 1. 初始状态:栈中逐步压入 A、B、C
|
||||
stack.push("C"); // 栈顶:C
|
||||
stack.push("B"); // 栈顶:B → C
|
||||
stack.push("A"); // 栈顶:A → B → C
|
||||
|
||||
Node originalNodeA = stack.getTop(); // 获取当前栈顶的 A 节点引用
|
||||
|
||||
System.out.println("\n--- 初始栈内容 ---");
|
||||
stack.printStack();
|
||||
|
||||
// 2. 线程1 启动,读取栈顶元素后等待
|
||||
Thread thread1 = new Thread(() -> {
|
||||
Node readNode = stack.getTop(); // 线程1在原栈中看到栈顶元素 A
|
||||
System.out.println("\n线程-1 读取到栈顶节点: " + readNode);
|
||||
try {
|
||||
Thread.sleep(200); // 等待线程2的干扰行为发生
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("\n线程-1 开始尝试弹出栈顶节点...");
|
||||
Node popNode = stack.pop(); // 线程1尝试弹出栈顶(被线程2修改为新 A)
|
||||
if (readNode == popNode) {
|
||||
System.out.println("同一个节点");
|
||||
}else {
|
||||
System.out.println("不是同一个节点,ABA问题已重现!");
|
||||
}
|
||||
}, "线程-1");
|
||||
|
||||
// 3. 线程2 启动,执行 ABA 序列
|
||||
Thread thread2 = new Thread(() -> {
|
||||
System.out.println("\n--- 线程-2 执行 ABA 序列 ---");
|
||||
stack.pop(); // 弹出 A,栈顶变为 B
|
||||
stack.pop(); // 弹出 B,栈顶变为 C
|
||||
stack.push("X"); // 压入一个新节点 X,栈顶变为 X → C
|
||||
stack.push("A"); // 再压入一个新的 A,栈顶变为 A → X → C
|
||||
System.out.println("--- 线程-2 完成 ABA 序列 ---");
|
||||
stack.printStack();
|
||||
}, "线程-2");
|
||||
|
||||
thread1.start(); // 启动线程1
|
||||
thread2.start(); // 启动线程2
|
||||
|
||||
thread1.join(); // 等待线程1完成
|
||||
thread2.join(); // 等待线程2完成
|
||||
|
||||
System.out.println("\n--- 最终栈内容 ---");
|
||||
stack.printStack();
|
||||
System.out.println("当前栈顶节点: " + stack.getTop());
|
||||
if (stack.getTop() != null) {
|
||||
System.out.println("栈顶节点的 next: " + stack.getTop().next);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
# 如何解决ABA问题
|
||||
|
||||
解决ABA问题的主要方法是引入一个 版本号(或时间戳) 机制。每次修改变量时,不仅修改值,也同时修改版本号。CAS操作时,需要同时比较值和版本号。
|
||||
|
||||

|
||||
|
||||
使用AtomicStampedReference解决问题
|
||||
|
||||
```java
|
||||
package org.example.aba;
|
||||
|
||||
import lombok.extern.slf4j.Slf4j;
|
||||
|
||||
import java.util.concurrent.TimeUnit;
|
||||
import java.util.concurrent.atomic.AtomicStampedReference;
|
||||
|
||||
@Slf4j
|
||||
public class AbaSolve {
|
||||
static AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0);
|
||||
|
||||
public static void main(String[] args) {
|
||||
log.debug("main start ....");
|
||||
String prev = ref.getReference();
|
||||
int stamp = ref.getStamp();
|
||||
log.debug("stamp: {}", stamp);
|
||||
|
||||
other();
|
||||
try {
|
||||
TimeUnit.SECONDS.sleep(1);
|
||||
} catch (InterruptedException e) {
|
||||
throw new RuntimeException(e);
|
||||
}
|
||||
log.debug("change A -> C {} ", ref.compareAndSet(prev, "C", stamp, stamp + 1));
|
||||
}
|
||||
|
||||
private static void other() {
|
||||
new Thread(() -> {
|
||||
int stamp = ref.getStamp();
|
||||
log.debug("{} 's stamp is : {}",Thread.currentThread().getName(),stamp);
|
||||
log.debug("change A-> B {} ", ref.compareAndSet(ref.getReference(), "B", stamp, stamp + 1));
|
||||
stamp = ref.getStamp();
|
||||
log.debug("{} 's changed stamp is : {}",Thread.currentThread().getName(),stamp);
|
||||
}, "t1").start();
|
||||
try {
|
||||
TimeUnit.MILLISECONDS.sleep(500);
|
||||
} catch (InterruptedException e) {
|
||||
throw new RuntimeException(e);
|
||||
}
|
||||
new Thread(()->{
|
||||
int stamp = ref.getStamp();
|
||||
log.debug("{} 's stamp is : {}",Thread.currentThread().getName(),stamp);
|
||||
log.debug("change B->A {}",ref.compareAndSet(ref.getReference(),"A",stamp,stamp + 1));
|
||||
stamp = ref.getStamp();
|
||||
log.debug("{} 's changed stamp is : {}",Thread.currentThread().getName(),stamp);
|
||||
},"t2").start();
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
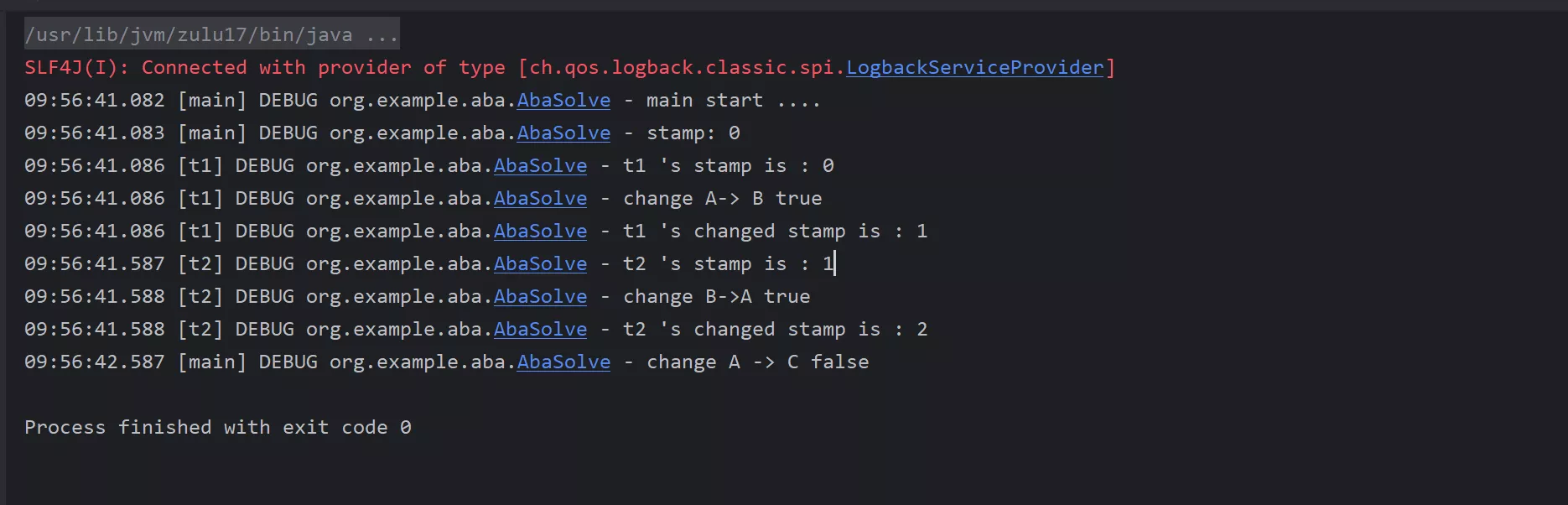
|
||||
48
src/content/posts/Java/JUC/ConcurrentHashMap1.7和1.8的区别.md
Normal file
48
src/content/posts/Java/JUC/ConcurrentHashMap1.7和1.8的区别.md
Normal file
@@ -0,0 +1,48 @@
|
||||
---
|
||||
title: ConcurrentHashMap1.7和1.8的区别
|
||||
published: 2025-09-15
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [Java,ConcurrentHashMap]
|
||||
category: 'Java'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# JDK1.7
|
||||
ConcurrentHashMap用的是分段锁,每个Segment是独立的,可以并发访问不同的Segment,默认是16个Segment,所以最多有16个线程可以并发执行。
|
||||
|
||||
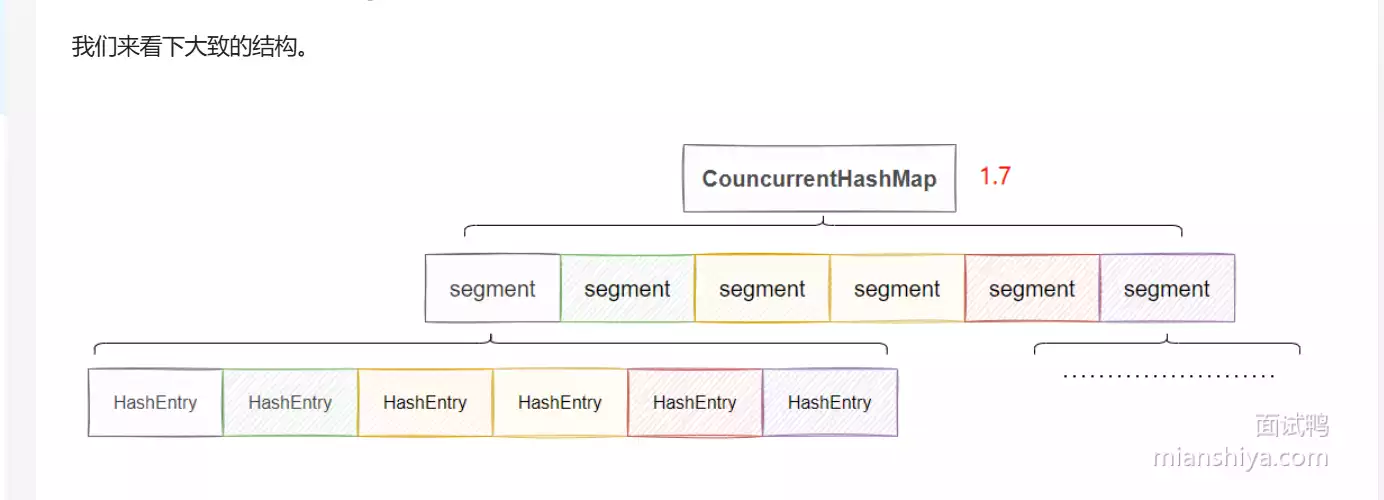
|
||||
|
||||
先通过key的hash判断得到Segment数组的下标,将这个Segment上锁,然后再次通过key的hash得到Segment里面HashEntry数组的下标。可以这么理解:每个Segment数组存放的就是一个单独的HashMap
|
||||
|
||||
缺点是Segment数组一旦初始化了之后就不会扩容,只有HashEntry数组会扩容,这就导致并发度过于死板
|
||||
|
||||
# JDK1.8
|
||||
移除了分段锁,锁的粒度更加细化,锁只在链表或者红黑树**节点级别**上进行。通过CAS进行插入操作,只有在更新链表或者红黑树的时候才使用`synchronized`,并且只锁住链表或者树的头节点,进一步减少了锁的竞争,并发度大大增加。
|
||||
|
||||
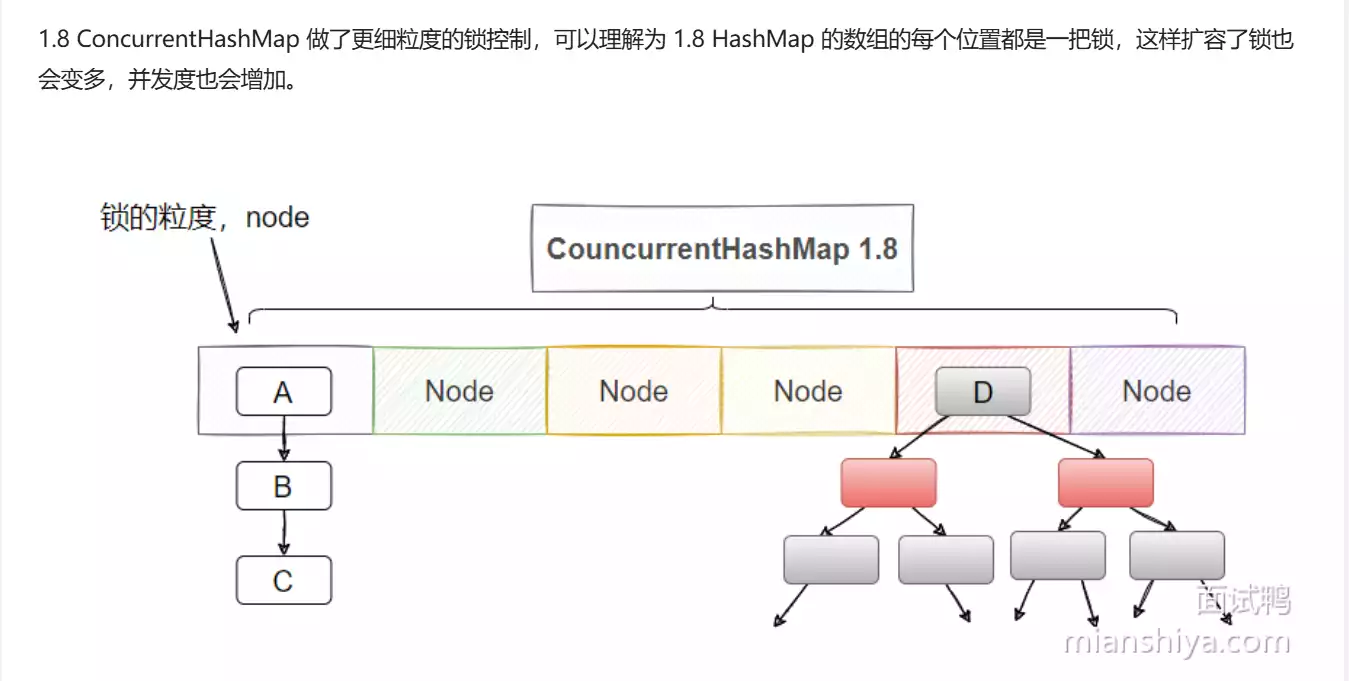
|
||||
|
||||
|
||||
1.8版本的ConcurrentHashMap也不借助ReentrantLock了,直接用synchronized。
|
||||
|
||||
当塞入一个值的时候,先计算key的hash后的下标,如果计算到的下标还没有Node,那么就通过CAS塞入新的Node,如果已经有node,就通过synchronized给这个node上锁,这样别的线程就无法访问这个node和它之后的所有节点了。
|
||||
然后判断key是不是相等,相等就直接替换value,反之新增一个node。
|
||||
|
||||
# 扩容上面的区别
|
||||
JDK1.7的扩容:
|
||||
- 基于Segment: ConcurrentHashMap是由多个Segment组成的,每个Segment中包含一个HashMap,当某个Segment内的HashMap达到扩容阈值的时候,单独为该Segment进行扩容,不会影响到其他Segment
|
||||
- 扩容过程: 每个Segment维护自己的负载因子,当Segment中的元素数量超过阈值的时候,这个Segment的HashMap会扩容,整体的ConcurrentHashMap并不是一次性全部扩容。
|
||||
|
||||
JDK1.8的扩容:
|
||||
- 全局扩容: ConcurrentHashMap取消了Segment,变成了一个全局的数组(类似于HashMap)。因此当ConcurrentHashMap中任意位置的元素超过阈值的时候,整个ConcurrentHashMap的数组都会被扩容。
|
||||
|
||||
- 基于CAS扩容: 扩容的时候,ConcurrentHashMap采用了类似HashMap的方式。通过CAS确保线程安全,避免锁住整个数组。扩容的时候,多个线程可以同时帮助完成扩容操作。
|
||||
|
||||
- 渐进性扩容: JDK1.8的ConcurrentHashMap引入了渐进式扩容机制,
|
||||
|
||||
|
||||
# size逻辑区别
|
||||
1.7 是尝试,调用size方法的时候不加锁,三次结果一样那说明没有线程竞争,如果不一样,就加锁计算。
|
||||
|
||||
1.8的话,是直接计算返回结果,用的是LongAdder完成的累加。
|
||||
14403
src/content/posts/Java/JUC/JUC笔记.md
Normal file
14403
src/content/posts/Java/JUC/JUC笔记.md
Normal file
File diff suppressed because it is too large
Load Diff
119
src/content/posts/Java/JUC/volatile双重锁.md
Normal file
119
src/content/posts/Java/JUC/volatile双重锁.md
Normal file
@@ -0,0 +1,119 @@
|
||||
---
|
||||
title: volatile-实现单例模式的双重锁
|
||||
published: 2025-08-07
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [JUC,JAVA,volatile,双重锁]
|
||||
category: 'Java > JUC'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# 什么是单例模式的双重锁
|
||||
单例模式的双重锁是一种实现单例模式的技术,通过两次检查实例是否为null,结合同步锁来保证在多线程环境下只创建一个实例,并试图通过减少同步的次数来提高性能。为了确保线程安全,尤其在涉及到对象创建的指令重排的问题的时候,通常需要使用 `volatile`关键字来修饰单例类的实例变量。
|
||||
|
||||
# 非线程安全的单例模式
|
||||
```java
|
||||
public class Singleton {
|
||||
private static Singleton instance;
|
||||
private Singleton() {
|
||||
|
||||
}
|
||||
public static Singleton getInstance() {
|
||||
if (instance == null) {
|
||||
instance = new Singleton();
|
||||
}
|
||||
return instance;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
> 多线程环境下,上面的简单实现在并发调用 `getInstance()`方法时候可能出现问题。
|
||||
|
||||

|
||||
|
||||
常见的做法是使用synchronized
|
||||
```java
|
||||
public class Singleton {
|
||||
private static Singleton instance;
|
||||
private Singleton() {
|
||||
|
||||
}
|
||||
public static synchronized Singleton getInstance() {
|
||||
if (instance == null) {
|
||||
instance = new Singleton();
|
||||
}
|
||||
return instance;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这种同步方式能确保线程安全,因为在同一时间,只有一个线程能够进入getInstance方法,但是每次调用`getInstance`方法都需要获取锁,即使在实例已经创建之后也是如此,这样会带来额外的性能开销,尤其是在频繁调用`getInstance()`的情况下
|
||||
# 什么是单例模式的双重检查锁定 -> 可能会导致半初始化问题
|
||||
双重检查锁定就是为了保证在线程安全的前提下,尽量减少同步带来的性能开销
|
||||
|
||||
核心思想:
|
||||
1. 第一次检查: 在进入同步块之前,先检查insatnce是否为null,如果不是null,说明实例已经创建,可以直接返回,避免进入同步块。
|
||||
2. 同步块: 如果第一次检查发现instance是null,就进入同步块
|
||||
3. 第二次检查: 在同步块内,再次检查instance是否为null,这是至关重要的一部,因为可能多个线程都通过了第一次检查,但只有一个线程进入同步块,在同步块内再次检查可以确保只有一个线程会智行对象的创建操作。
|
||||
4. 创建实例:如果第二次检查发现instance仍然为null,才真正创建对象并把引用赋值给instance
|
||||
|
||||
|
||||
```java
|
||||
public class Singleton {
|
||||
private static Singleton instance;
|
||||
private Singleton() {
|
||||
|
||||
}
|
||||
public static Singleton getInstance() {
|
||||
if (instance == null) {
|
||||
synchronized (Singleton.class) {
|
||||
if (instance == null) {
|
||||
instance = new Singleton();
|
||||
}
|
||||
}
|
||||
}
|
||||
return instance;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
> 尽管双重检查锁看起来聪明地减少了同步磁化,但是在JMM(JAVA 内存模型)种,没有使用`volatile`的双重检查锁仍然存在`指令重排`的问题。
|
||||
|
||||
对象创建的过程 `instance = new SimpleSingleton();` 实际上能分解为三个步骤:
|
||||
1. 为对象分配内存空间
|
||||
2. 初始化对象
|
||||
3. 将分配的内存空间的地址赋值给`instance`变量
|
||||
|
||||
在某些情况下,JVM为了优化性能,可能会对这三个步骤进行重排序,例如,可能会将步骤三排在步骤2之前
|
||||
|
||||
|
||||

|
||||
|
||||
# 为什么用volatile?
|
||||
1. 可见性: volatile确保了所有线程都能看到instance变量的最新值,当一个线程修改了instance值,这个改变会立即对其他线程可见。
|
||||
2. 禁止指令重排:解决了半初始化的问题,确保instance变量被赋值为非null之前,对象已经被完全初始化。
|
||||
|
||||
```java
|
||||
public class Singleton {
|
||||
private static volatile Singleton instance;
|
||||
private Singleton() {
|
||||
|
||||
}
|
||||
public static Singleton getInstance() {
|
||||
if (instance == null) {
|
||||
synchronized (Singleton.class) {
|
||||
if (instance == null) {
|
||||
instance = new Singleton();
|
||||
}
|
||||
}
|
||||
}
|
||||
return instance;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
308
src/content/posts/Java/JUC/线程安全单例.md
Normal file
308
src/content/posts/Java/JUC/线程安全单例.md
Normal file
@@ -0,0 +1,308 @@
|
||||
---
|
||||
title: 线程安全单例
|
||||
published: 2025-08-07
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [JUC,JAVA,volatile,线程安全,单例模式]
|
||||
category: 'Java > JUC'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||

|
||||
# 1 解决反序列化导致的单例破坏现象
|
||||
|
||||
这里的单例问题是,如果对一个可序列化对象进行反序列化,会创建一个新的对象,这就违背了我们想要全局单例的目标。因此要重写readResolve方法。
|
||||
|
||||
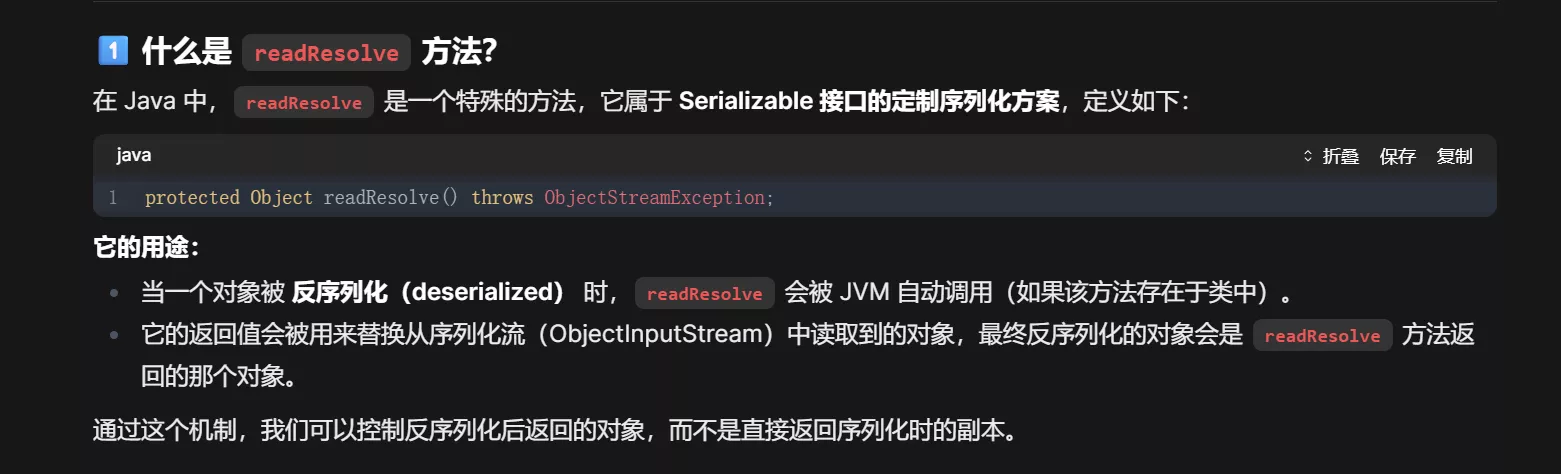
|
||||
|
||||
```java
|
||||
package org.example.sigletons;
|
||||
|
||||
import java.io.Serializable;
|
||||
|
||||
public class Singleton1 implements Serializable {
|
||||
private Singleton1(){}
|
||||
private static final Singleton1 INSTANCE = new Singleton1();
|
||||
public Singleton1 getInstance() {
|
||||
return INSTANCE;
|
||||
}
|
||||
public Object readResolve() {
|
||||
return INSTANCE;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
# 2 使用枚举实现单例模式
|
||||

|
||||
|
||||
```java
|
||||
package org.example.sigletons;
|
||||
|
||||
import java.io.IOException;
|
||||
import java.io.InputStream;
|
||||
import java.util.Properties;
|
||||
|
||||
public enum Singleton2 {
|
||||
INSTANCE;
|
||||
private final Properties properties;
|
||||
private Singleton2() {
|
||||
properties = new Properties();
|
||||
String configFile = "application.properties";
|
||||
System.out.println("ConfigurationManager: Initializing and loading " + configFile);
|
||||
try(InputStream inputStream = Singleton2.class.getClassLoader().getResourceAsStream(configFile)){
|
||||
if(inputStream == null){
|
||||
System.out.println("ConfigurationManager: Sorry, unable to find " + configFile);
|
||||
// 在实际应用中,这里可能抛出异常或有更复杂的错误处理
|
||||
return;
|
||||
}
|
||||
properties.load(inputStream);
|
||||
System.out.println("ConfigurationManager: Configuration loaded successfully.");
|
||||
}catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
public String getProperty(String key) {
|
||||
return properties.getProperty(key);
|
||||
}
|
||||
public String getProperty(String key,String defaultValue) {
|
||||
return properties.getProperty(key, defaultValue);
|
||||
}
|
||||
|
||||
// 可以添加其他需要的方法,比如重新加载配置等(需要考虑线程安全)
|
||||
public void listProperties() {
|
||||
properties.forEach((key, value) -> System.out.println(key + "=" + value));
|
||||
}
|
||||
}
|
||||
class TestSingleton2 {
|
||||
public static void main(String[] args) {
|
||||
Singleton2 singleton2 = Singleton2.INSTANCE;
|
||||
singleton2.listProperties();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
💎 枚举单例:全面解答这些问题!📜✨
|
||||
|
||||
枚举单例是一种非常推荐的单例实现方式,因为它不仅简单、易用,还天然地具备线程安全和防止反序列化、反射破坏单例的能力。接下来,我们重点针对 **枚举单例** 来回答这些问题!
|
||||
|
||||
---
|
||||
|
||||
### **问题 1:枚举单例是如何限制实例个数的?**
|
||||
|
||||
枚举单例通过枚举的机制天然地保证:
|
||||
1. 枚举类的每一个枚举实例(如单例对象)都在 **类加载阶段** 就完成初始化,并且整个应用程序中只有一个实例。
|
||||
2. 枚举类型底层由 JVM 的实现机制保证,它不像普通类那样允许通过反射或 `new` 额外创建实例。
|
||||
|
||||
#### 示例:
|
||||
```java
|
||||
public enum SingletonEnum {
|
||||
INSTANCE; // 枚举单例实例
|
||||
|
||||
public void doSomething() {
|
||||
System.out.println("Doing something...");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 使用方式:
|
||||
即便通过 `SingletonEnum.INSTANCE` 多次获取,得到的始终是同一个实例。
|
||||
```java
|
||||
SingletonEnum instance1 = SingletonEnum.INSTANCE;
|
||||
SingletonEnum instance2 = SingletonEnum.INSTANCE;
|
||||
System.out.println(instance1 == instance2); // 输出:true
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### **问题 2:枚举单例在创建时是否有并发问题?**
|
||||
|
||||
枚举单例天然线程安全,因为:
|
||||
1. 枚举类型的初始化由 JVM 保证,是在类加载时完成的。
|
||||
2. 类加载过程是线程安全的,JVM 使用了类加载的同步机制,保证枚举单例的初始化不会因多线程而发生竞争。
|
||||
|
||||
#### 举例:
|
||||
即使多个线程同时调用 `SingletonEnum.INSTANCE`,它们都会得到在类加载阶段构造好的唯一对象,无需额外同步。
|
||||
|
||||
---
|
||||
|
||||
### **问题 3:枚举单例能否被反射破坏单例?**
|
||||
|
||||
**不会!** 枚举类型的结构特殊,无法被反射破坏单例。这是因为:
|
||||
1. 枚举的构造器是私有的,并且其底层会检测反射调用。
|
||||
2. 如果尝试通过反射显式调用枚举类的构造器,JVM 会抛出 `IllegalArgumentException`。
|
||||
|
||||
#### 验证代码:
|
||||
```java
|
||||
import java.lang.reflect.Constructor;
|
||||
|
||||
public class EnumReflectionTest {
|
||||
public static void main(String[] args) {
|
||||
try {
|
||||
// 获取枚举的构造器
|
||||
Constructor<SingletonEnum> constructor = SingletonEnum.class.getDeclaredConstructor();
|
||||
constructor.setAccessible(true);
|
||||
SingletonEnum instance = constructor.newInstance(); // 反射创建枚举对象
|
||||
} catch (Exception e) {
|
||||
e.printStackTrace(); // 会抛出 IllegalArgumentException
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 运行结果:
|
||||
```
|
||||
java.lang.IllegalArgumentException: Cannot reflectively create enum objects
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### **问题 4:枚举单例能否被反序列化破坏单例?**
|
||||
|
||||
枚举单例天然具备防止反序列化破坏的特性,原因是:
|
||||
1. `Enum` 类型的序列化机制是由 JVM 内部实现的,不走普通的对象序列化流程。
|
||||
2. 反序列化枚举对象时,JVM 会直接返回枚举类中的现有实例,而不是从序列化流中创建新对象。
|
||||
|
||||
#### 验证代码:
|
||||
```java
|
||||
import java.io.*;
|
||||
|
||||
public class EnumSerializationTest {
|
||||
public static void main(String[] args) throws IOException, ClassNotFoundException {
|
||||
SingletonEnum instance1 = SingletonEnum.INSTANCE;
|
||||
|
||||
// 序列化枚举对象
|
||||
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("enum_singleton.obj"));
|
||||
oos.writeObject(instance1);
|
||||
oos.close();
|
||||
|
||||
// 反序列化枚举对象
|
||||
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("enum_singleton.obj"));
|
||||
SingletonEnum instance2 = (SingletonEnum) ois.readObject();
|
||||
|
||||
// 判断是否破坏单例
|
||||
System.out.println(instance1 == instance2); // 输出:true,单例没有破坏
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### **问题 5:枚举单例属于懒汉式还是饿汉式?**
|
||||
|
||||
**枚举单例本质上属于饿汉式单例**。它的特点是**在类加载阶段完成初始化**:
|
||||
- 枚举的实例在类加载时就被创建并初始化。
|
||||
- 即使程序中从未访问过 `SingletonEnum.INSTANCE`,枚举实例依然会被加载。
|
||||
|
||||
#### 优点:
|
||||
- 线程安全,无需为单例初始化额外编写同步代码。
|
||||
- 实现简洁,JVM 自动保证。
|
||||
|
||||
#### 缺点:
|
||||
- 如果枚举实例较多,并且包含较大的初始化逻辑,会导致类加载阶段性能开销增加。
|
||||
|
||||
---
|
||||
|
||||
### **问题 6:枚举单例如果希望加入一些初始化逻辑,该如何做?**
|
||||
|
||||
可以通过添加枚举的构造方法和静态方法来实现初始化逻辑。枚举的构造方法是私有的,可以用来在实例创建时执行初始化。
|
||||
|
||||
#### 修改代码:
|
||||
```java
|
||||
public enum SingletonEnum {
|
||||
INSTANCE; // 枚举单例实例
|
||||
|
||||
private String configuration;
|
||||
|
||||
// 枚举的构造方法
|
||||
SingletonEnum() {
|
||||
// 初始化逻辑
|
||||
configuration = "System Configuration Loaded";
|
||||
}
|
||||
|
||||
public String getConfiguration() {
|
||||
return configuration;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 测试:
|
||||
```java
|
||||
public class TestEnumInitialization {
|
||||
public static void main(String[] args) {
|
||||
SingletonEnum instance = SingletonEnum.INSTANCE;
|
||||
System.out.println(instance.getConfiguration()); // 输出:System Configuration Loaded
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 分析:
|
||||
- 枚举类型的构造器会在类加载时调用,且只调用一次。
|
||||
- 可用枚举构造器实现单例实例的初始化逻辑。
|
||||
|
||||
---
|
||||
|
||||
### 总结
|
||||
|
||||
**为何枚举单例完美适合单例模式?**
|
||||
- 它是天生线程安全的,JVM 保障了枚举实例的唯一性。
|
||||
- 枚举实例不能通过反射或序列化破坏。
|
||||
- 枚举的初始化流程天然符合饿汉式单例的特点。
|
||||
|
||||
---
|
||||
|
||||
# 3 Double Check
|
||||
|
||||
https://meowrain.cn/archives/volatile-shi-xian-dan-li-mo-shi-de-shuang-zhong-suo
|
||||
|
||||
|
||||
```java
|
||||
package cn.meowrain;
|
||||
|
||||
public class DoubleSingleton {
|
||||
private static volatile DoubleSingleton INSTANCE = null;
|
||||
public static DoubleSingleton getInstance() {
|
||||
if(INSTANCE != null) {
|
||||
return INSTANCE;
|
||||
}
|
||||
synchronized (DoubleSingleton.class){
|
||||
if(INSTANCE != null) {
|
||||
return INSTANCE;
|
||||
}
|
||||
INSTANCE = new DoubleSingleton();
|
||||
return INSTANCE;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
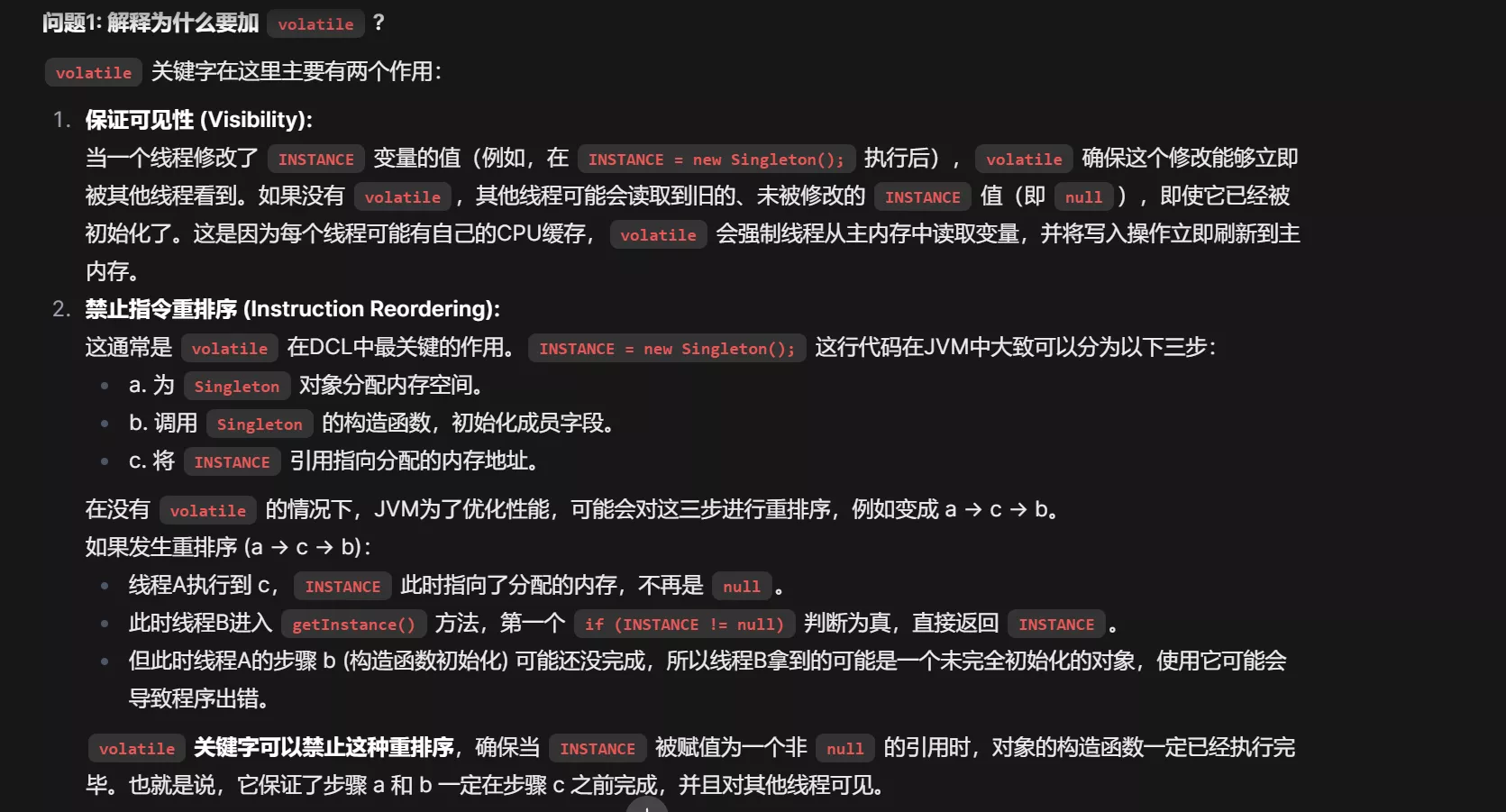
|
||||
|
||||
|
||||
# 4 静态内部类懒汉式创建线程安全单例
|
||||
|
||||
```
|
||||
package cn.meowrain;
|
||||
|
||||
public class Singleton2 {
|
||||
private Singleton2(){}
|
||||
// 问题1: 属于懒汉式还是饿汉式
|
||||
private static class LazyLoader{
|
||||
static final Singleton2 INSTANCE = new Singleton2();
|
||||
}
|
||||
// 在创建的时候是否有并发问题
|
||||
public static Singleton2 getInstance() {
|
||||
return LazyLoader.INSTANCE;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
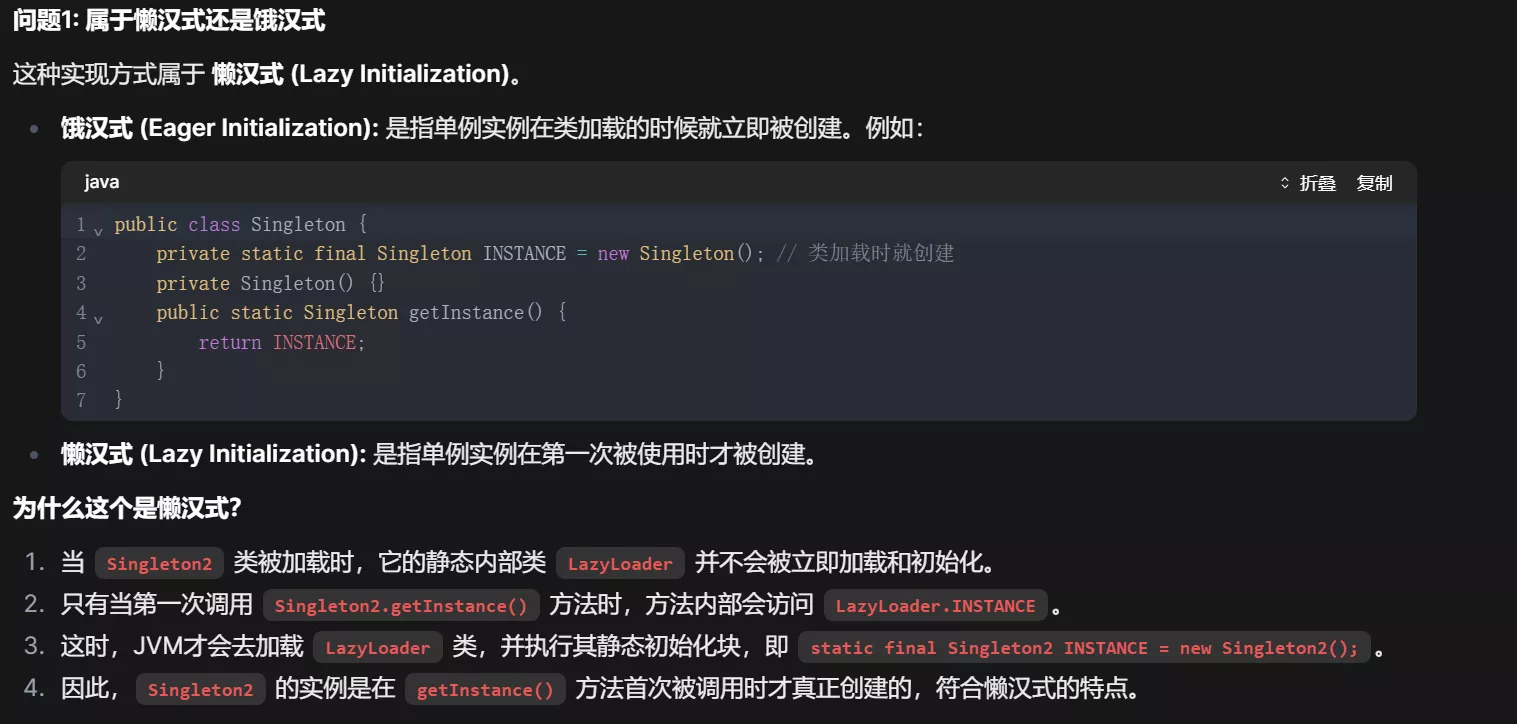
|
||||
|
||||
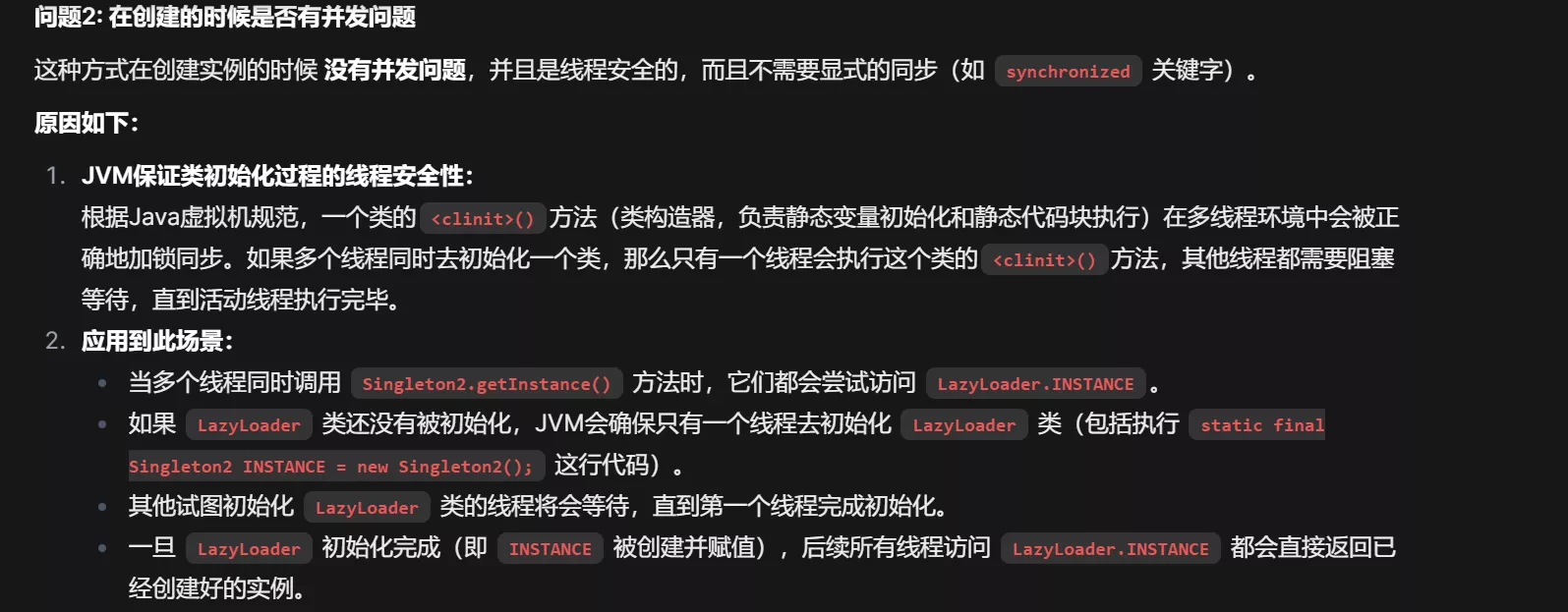
|
||||
117
src/content/posts/Java/JVM/GC相关参数.md
Normal file
117
src/content/posts/Java/JVM/GC相关参数.md
Normal file
@@ -0,0 +1,117 @@
|
||||
---
|
||||
title: JVM GC相关参数
|
||||
published: 2025-07-18
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [GC,JAVA,JVM]
|
||||
category: 'Java > JVM'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# GC相关参数
|
||||
|
||||
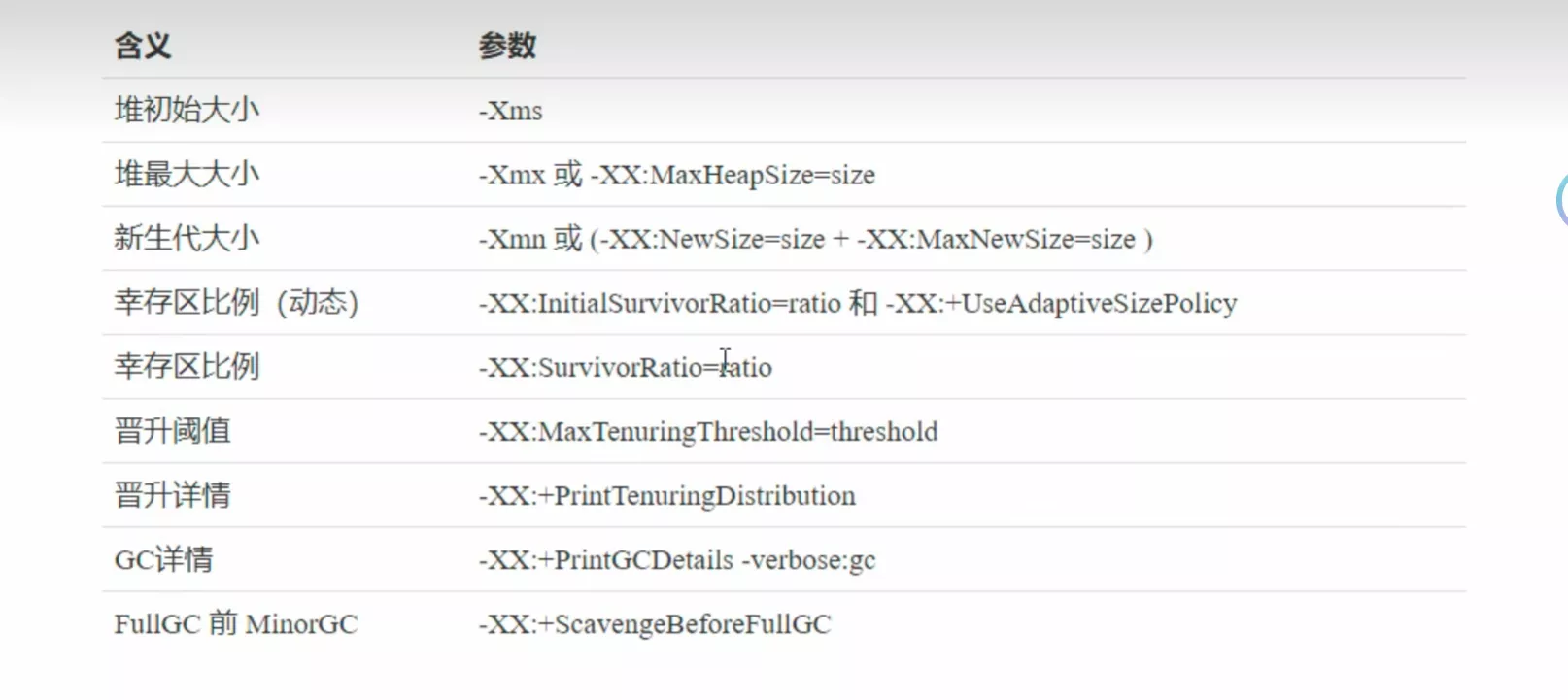
|
||||
|
||||
---
|
||||
|
||||
### 1. 堆初始大小 (`Xms`)
|
||||
|
||||
- **参数:** `Xms<size>`
|
||||
- **含义:** 设置 JVM 启动时**初始分配的堆内存大小**。
|
||||
- **作用:**
|
||||
- 决定了 Java 程序一启动时,JVM 向操作系统申请的内存大小。
|
||||
- 如果设置得太小,JVM 可能会在程序运行初期频繁地进行堆内存扩展,这会带来一定的性能开销。
|
||||
- **示例:** `Xms512m` 表示设置初始堆大小为 512MB。
|
||||
- **最佳实践:** 在生产环境中,通常建议将 `Xms` 和 `Xmx` 设置为相同的值,以避免堆的动态扩展和收缩带来的性能抖动。
|
||||
|
||||
---
|
||||
|
||||
### 2. 堆最大大小 (`Xmx` 或 `XX:MaxHeapSize`)
|
||||
|
||||
- **参数:** `Xmx<size>` 或 `XX:MaxHeapSize=<size>`
|
||||
- **含义:** 设置 JVM **允许分配的最大堆内存大小**。
|
||||
- **作用:**
|
||||
- 这是堆内存的硬性上限。如果应用程序需要的内存超过了这个值,就会抛出 `java.lang.OutOfMemoryError`。
|
||||
- 合理设置此值可以防止应用程序因内存泄漏等问题耗尽所有服务器内存,从而影响其他进程。
|
||||
- **示例:** `Xmx2g` 表示设置最大堆大小为 2GB。
|
||||
|
||||
---
|
||||
|
||||
### 3. 新生代大小 (`Xmn` 或 `XX:NewSize` + `XX:MaxNewSize`)
|
||||
|
||||
- **参数:** `Xmn<size>`
|
||||
- **含义:** 设置**新生代(Young Generation)的大小**。这是一个快捷参数。
|
||||
- **作用:**
|
||||
- 新生代是绝大多数新对象产生的地方,也是 Minor GC 发生的主要区域。
|
||||
- 设置一个合理的新生代大小非常重要。
|
||||
- **过小:** 会导致 Minor GC 过于频繁。
|
||||
- **过大:** 会挤占老年代的空间,可能导致更频繁的 Full GC。同时,单次 Minor GC 的时间可能会变长。
|
||||
- **补充:** `Xmn` 实际上是同时设置了 `XX:NewSize`(新生代初始大小)和 `XX:MaxNewSize`(新生代最大大小)。如果希望新生代大小动态变化,可以分别设置这两个参数。
|
||||
|
||||
---
|
||||
|
||||
### 4. 幸存区比例 (`XX:SurvivorRatio`)
|
||||
|
||||
- **参数:** `XX:SurvivorRatio=<ratio>`
|
||||
- **含义:** 设置新生代中 **Eden 区与一个 Survivor 区的大小比例**。
|
||||
- **计算公式:** `ratio = Eden区大小 / Survivor区大小`。
|
||||
- **作用:**
|
||||
- 这个比例决定了新生代中用于创建新对象(Eden)和存放幸存对象(Survivor)的空间分配。
|
||||
- 例如,`XX:SurvivorRatio=8` 表示 Eden:S0:S1 的比例是 8:1:1。这意味着 Eden 区将占用新生代 8/10 的空间,而每个 Survivor 区占用 1/10。
|
||||
- **注意:** 这个参数在启用了自适应大小策略(`XX:+UseAdaptiveSizePolicy`,在某些 GC 算法中默认开启)时,其设置的固定比例可能会被 JVM 动态调整。
|
||||
|
||||
---
|
||||
|
||||
### 5. 幸存区比例 (动态) (`XX:InitialSurvivorRatio` 和 `XX:+UseAdaptiveSizePolicy`)
|
||||
|
||||
- **参数:** `XX:+UseAdaptiveSizePolicy`
|
||||
- **含义:** **启用 GC 自适应大小策略**。这个策略允许 JVM 根据应用程序的运行情况(如吞吐量、停顿时间目标)动态调整堆中各区域的大小,包括 Eden/Survivor 的比例。
|
||||
- **作用:**
|
||||
- 开启后,JVM 会自动优化内存分配,省去了手动精细调优的麻烦。这是 Parallel GC 等收集器默认开启的。
|
||||
- `XX:InitialSurvivorRatio` 用于设定自适应策略下的**初始** SurvivorRatio 值,后续 JVM 可能会根据需要进行调整。
|
||||
- **结论:** 如果你看到这个参数,意味着 JVM 正在自动管理新生代的比例,`XX:SurvivorRatio` 的静态设置可能不会生效。
|
||||
|
||||
---
|
||||
|
||||
### 6. 晋升阈值 (`XX:MaxTenuringThreshold`)
|
||||
|
||||
- **参数:** `XX:MaxTenuringThreshold=<threshold>`
|
||||
- **含义:** 设置对象从新生代晋升到老年代的**年龄阈值**。
|
||||
- **作用:**
|
||||
- 一个对象在 Survivor 区每熬过一次 Minor GC,其年龄就加 1。当年龄达到这个阈值时,就会被移动到老年代。
|
||||
- 默认值通常是 15(或 6,取决于 GC)。
|
||||
- 如果设置得太高,对象可能长时间停留在 Survivor 区,增加了复制成本;如果设置得太低,可能导致一些生命周期不长的对象过早进入老年代,增加了 Full GC 的压力。
|
||||
|
||||
---
|
||||
|
||||
### 7. 晋升详情 (`XX:+PrintTenuringDistribution`)
|
||||
|
||||
- **参数:** `XX:+PrintTenuringDistribution`
|
||||
- **含义:** 一个诊断参数,用于在每次 Minor GC 后**打印出 Survivor 区中对象的年龄分布情况**。
|
||||
- **作用:**
|
||||
- 这是调优 `XX:MaxTenuringThreshold` 的重要工具。
|
||||
- 通过观察日志,你可以看到每个年龄段有多少对象,以及 JVM 计算出的动态晋升阈值,从而判断当前设置是否合理。
|
||||
|
||||
---
|
||||
|
||||
### 8. GC 详情 (`XX:+PrintGCDetails` 和 `verbose:gc`)
|
||||
|
||||
- **参数:** `XX:+PrintGCDetails` 或 `verbose:gc`
|
||||
- **含义:** 打印详细的 GC 日志信息。
|
||||
- **作用:**
|
||||
- 这是进行 GC 性能分析和故障排查的**必备参数**。
|
||||
- `verbose:gc` 是一个标准参数,输出基本的 GC 信息。
|
||||
- `XX:+PrintGCDetails` 会提供更详尽的信息,包括每次 GC 前后堆各区域的大小、GC 耗时等。
|
||||
- **推荐:** 通常与 `XX:+PrintGCTimeStamps` 或 `XX:+PrintGCDateStamps` 一起使用,为日志增加时间戳。
|
||||
|
||||
---
|
||||
|
||||
### 9. FullGC 前 MinorGC (`XX:+ScavengeBeforeFullGC`)
|
||||
|
||||
- **参数:** `XX:+ScavengeBeforeFullGC`
|
||||
- **含义:** 指示 JVM 在执行 Full GC 之前,先强制进行一次 Minor GC。
|
||||
- **作用:**
|
||||
- 理论上,这可以清理掉新生代中大部分可以被回收的对象,从而减轻 Full GC 的负担,因为 Full GC 需要处理整个堆(包括新生代)。
|
||||
- **注意:**
|
||||
- 此参数在现代的 GC(如 G1)中已不推荐使用或被废弃,因为它们有更智能的回收策略。
|
||||
- 在某些情况下,它可能会引入一次额外的、不必要的停顿(Minor GC 的停顿)。因此,除非有明确的测试数据支持,否则一般不建议开启。
|
||||
31
src/content/posts/Java/JVM/JVM内存模型分区.md
Normal file
31
src/content/posts/Java/JVM/JVM内存模型分区.md
Normal file
@@ -0,0 +1,31 @@
|
||||
---
|
||||
title: JVM内存模型分区
|
||||
published: 2025-07-18
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [JVM,内存模型]
|
||||
category: 'Java > JVM'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# JVM内存模型分⼏个区,每个区放什么对象
|
||||
|
||||
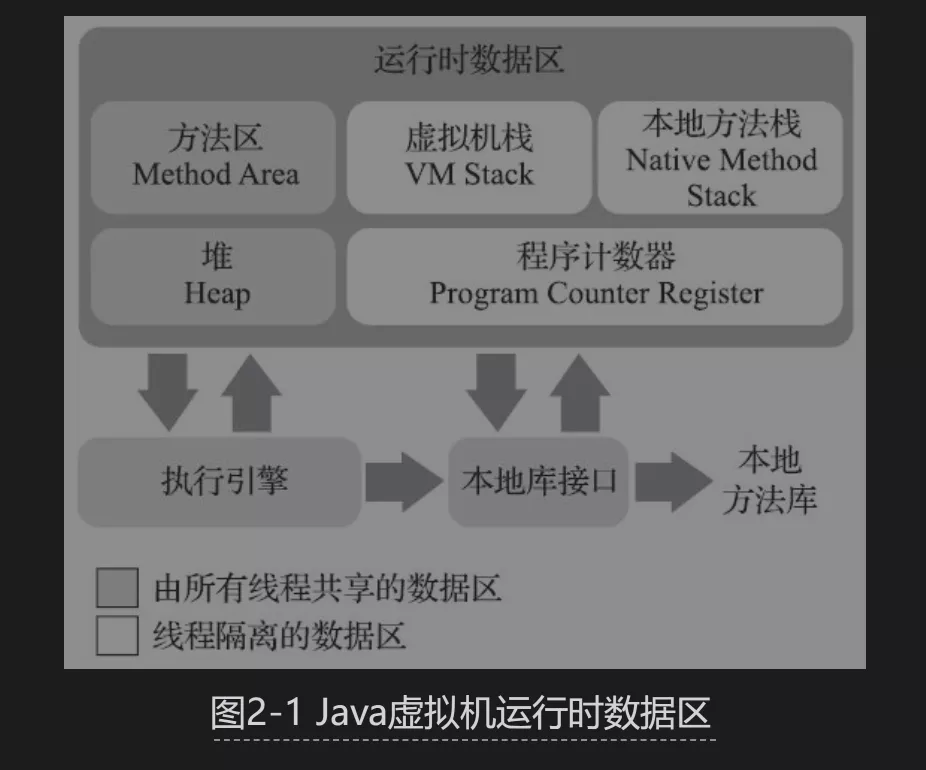
|
||||
|
||||
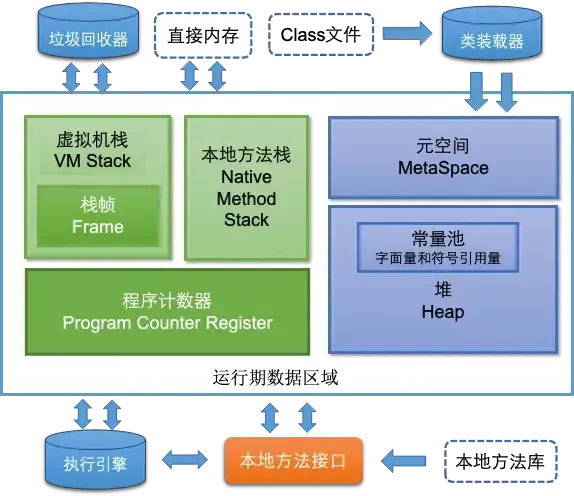
|
||||
|
||||

|
||||
|
||||
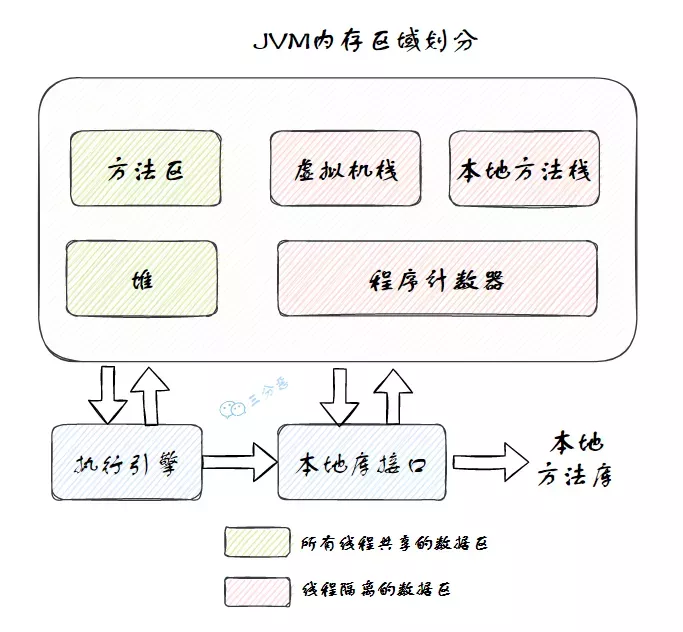
|
||||
|
||||
分为方法区,堆,本地方法栈,虚拟机栈,程序计数器
|
||||
|
||||
方法区(元空间):用于存储已经被虚拟机加载的类信息,常量,静态变量等数据。虽然方法区被描述为堆的逻辑部分,但有”非堆“的别名。方法区可以选择不实现垃圾收集,内存不足的时候,会抛出OutOfMemoryError异常。
|
||||
|
||||
程序计数器: 当前线程所执行的字节码的行号指示器,存储当前线程正在执行的Java方法的JVM指令地址。
|
||||
|
||||
JVM虚拟机栈:每个线程都有自己独立的Java虚拟机栈,生命周期和线程相同,每个方法在执行的时候都会创建一个栈帧,用来存储局部变量表,操作数栈,动态链接,方法出口等信息。
|
||||
|
||||
本地方法栈: 与Java虚拟机栈差不读多,执行本地方法,其中堆和方法区是线程共有的。
|
||||
|
||||
Java堆: 存放和管理对象实例,被所有线程共享。
|
||||
148
src/content/posts/Java/JVM/JVM垃圾回收算法.md
Normal file
148
src/content/posts/Java/JVM/JVM垃圾回收算法.md
Normal file
@@ -0,0 +1,148 @@
|
||||
---
|
||||
title: JVM垃圾回收算法
|
||||
published: 2025-07-18
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [JVM,垃圾回收,分代回收]
|
||||
category: 'Java > JVM'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# 垃圾回收算法
|
||||
|
||||

|
||||
|
||||
[【Java虚拟机】JVM垃圾回收机制和常见回收算法原理-腾讯云开发者社区-腾讯云](https://cloud.tencent.com/developer/article/2292267)
|
||||
|
||||
### **垃圾回收机制**
|
||||
|
||||
**(1)什么是垃圾回收机制(Garbage Collection, 简称GC)**
|
||||
|
||||
- 指自动管理动态分配的内存空间的机制,自动回收不再使用的内存,以避免内存泄漏和内存溢出的问题
|
||||
- 最早是在1960年代提出的,程序员需要手动管理内存的分配和释放
|
||||
- 这往往会导致内存泄漏和内存溢出等问题,同时也增加了程序员的工作量,特别是C++/C语言开发的时候
|
||||
- Java语言是最早实现垃圾回收机制的语言之一,其他编程语言,如C#、Python和Ruby等,也都提供了垃圾回收机制
|
||||
|
||||
**(2)JVM自动垃圾回收机制**
|
||||
|
||||
- 指Java虚拟机在运行Java程序时,自动回收不再使用的对象所占用的内存空间的过程
|
||||
- Java程序中的对象,一旦不再被引用会被标记为垃圾对象,JVM会在适当的时候自动回收这些垃圾对象所占用的内存空间
|
||||
- 优点
|
||||
- 减少了程序员的工作量,不需要手动管理内存
|
||||
- 动态地管理内存,根据应用程序的需要进行分配和回收,提高了内存利用率
|
||||
- 避免内存泄漏和野指针等问题,增加程序的稳定性和可靠
|
||||
- 缺点
|
||||
- 垃圾回收会占用一定的系统资源,可能会影响程序的性能
|
||||
- 垃圾回收过程中会停止程序的执行,可能会导致程序出现卡顿等问题
|
||||
- **不一定能够完全解决内存泄漏等问题,需要在编写代码时注意内存管理和编码规范**
|
||||
|
||||
---
|
||||
|
||||
# 垃圾回收算法
|
||||
|
||||
## 引用计数法
|
||||
|
||||
跟踪每个对象被引用的次数,当引用次数为0 的时候,可以将该对象回收。
|
||||
|
||||
优点是实现简单,缺点是循环引用没办法回收,而且引用计数器消耗大。
|
||||
|
||||

|
||||
|
||||
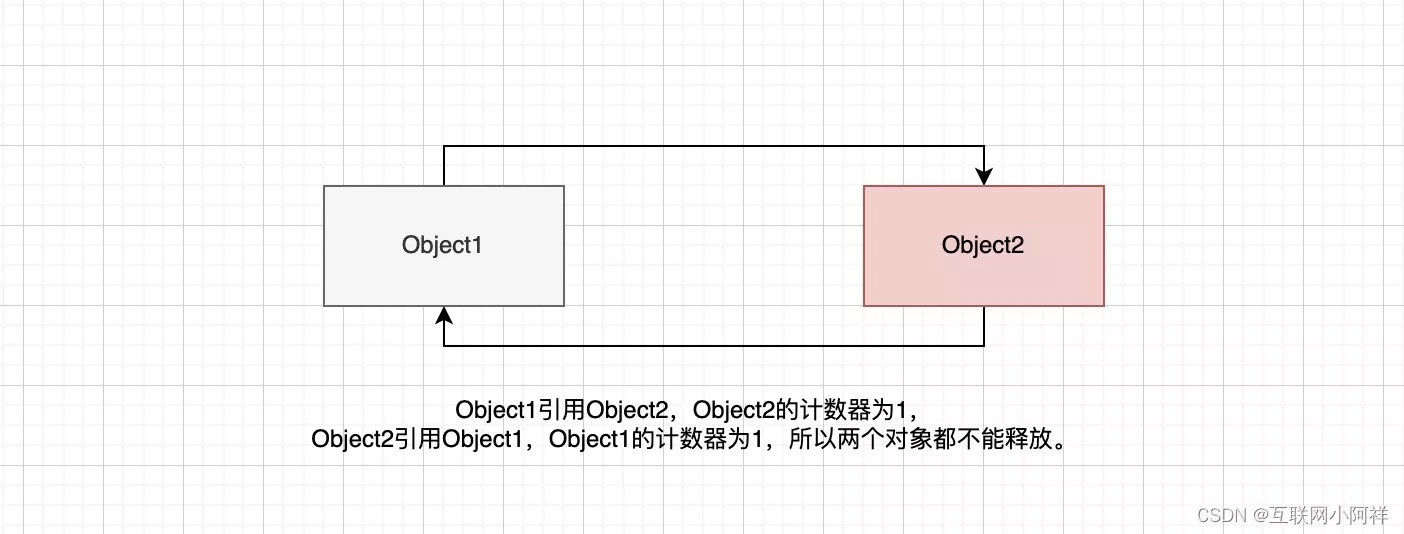
|
||||
|
||||
## **可达性分析算法**
|
||||
|
||||
- 可达性分析算法的基本思想是通过一系列的“GC Roots”对象作为起点进行搜索。
|
||||
- 如果“GC Roots”和一个对象之间没有可达路径,则称该对象是不可达的,不过要注意的是被判定为不可达的对象不一定就会成为可回收对象。
|
||||
- 被判定为不可达的对象要成为回收对象,要至少经历两次标记过程。
|
||||
- 如果在这两次标记过程中仍然没有逃脱成为可回收对象的可能性,则基本上就真的成为可回收对象了。
|
||||
|
||||
通过一系列称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索走过的路径称为“引用链”,当一个对象到 GC Roots 没有任何的引用链相连时(从 GC Roots 到这个对象不可达)时,证明此对象不可用。
|
||||
|
||||
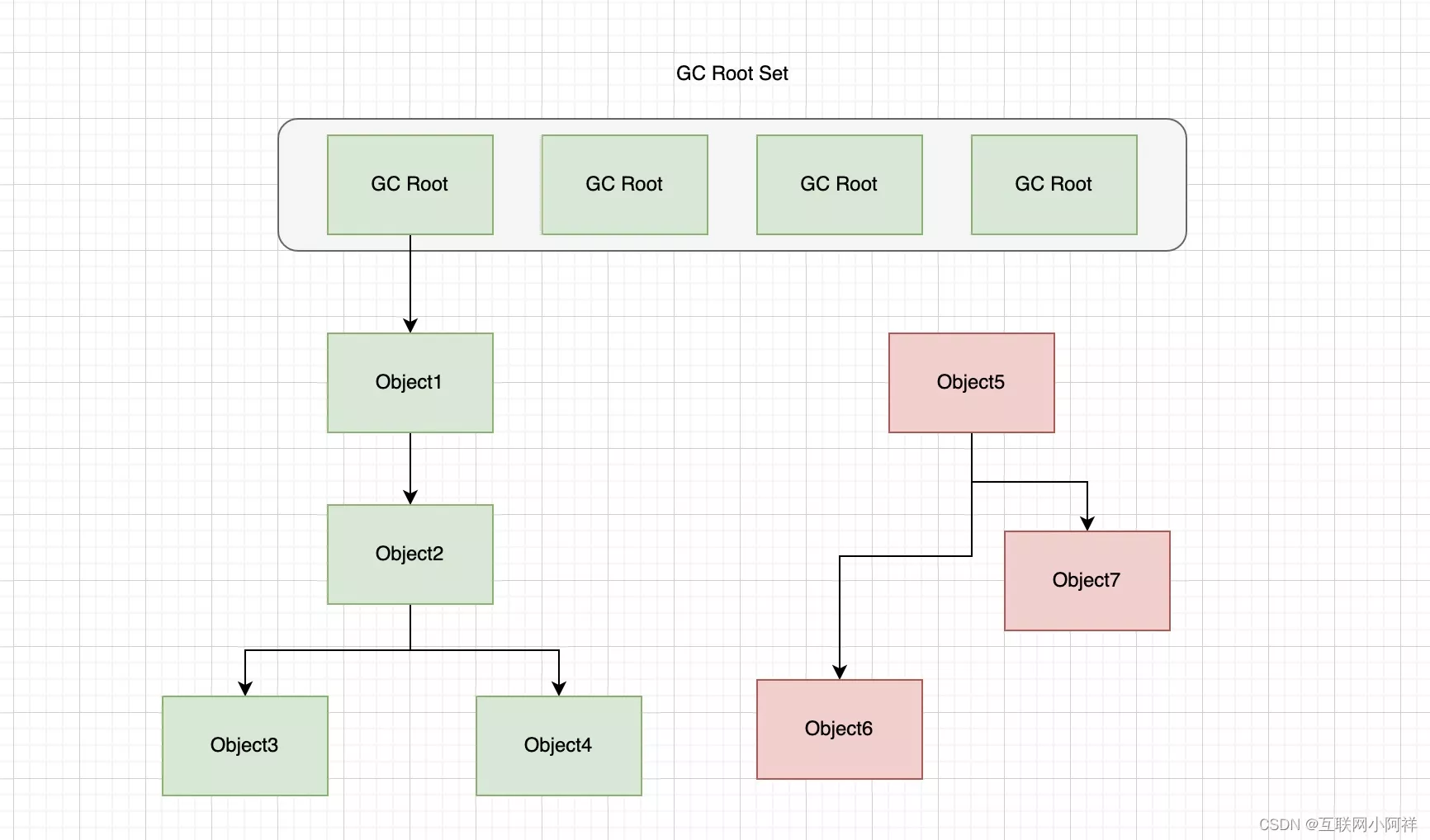
|
||||
|
||||
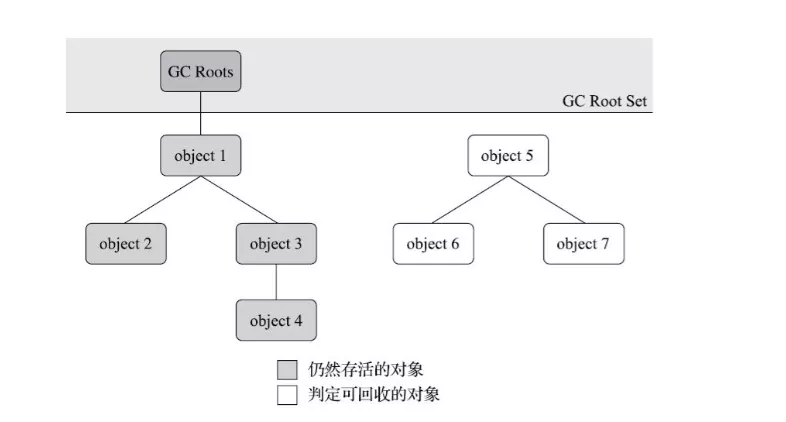
|
||||
|
||||
### 什么是GC ROOT
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## **垃圾回收算法之标记-复制算法**
|
||||
|
||||
- 标记算法是一种常见的垃圾回收算法,它的基本思路是将Java堆分为两个区域:一个活动区域和一个空闲区域
|
||||
- 在垃圾回收过程中,首先标记所有被引用的对象
|
||||
- 然后将所有被标记的对象复制到空闲区域中,最后交换两个区域的角色,完成垃圾回收
|
||||
- 标记复制算法的详细实现步骤
|
||||
- 将Java堆分为两个区域:一个活动区域和一个空闲区域,初始时,所有对象都分配在活动区域中
|
||||
- 从GC Roots对象开始,遍历整个对象图,标记所有被引用的对象
|
||||
- 对所有被标记存活的对象进行遍历,将它们复制到空闲区域中,并更新所有指向它们的引用,使它们指向新的地址
|
||||
- 对所有未被标记的对象进行回收,将它们所占用的内存空间释放
|
||||
- 交换活动区域和空闲区域的角色,空闲区域变为新的活动区域,原来的活动区域变为空闲区域
|
||||
- 当空闲区域的内存空间不足时,进行一次垃圾回收,重复以上步骤。
|
||||
- 优点
|
||||
- 如果内存中的垃圾对象较多,需要复制的对象就较少,则效率高
|
||||
- 清理后,内存碎片少
|
||||
- 缺点
|
||||
- 标记复制算法的效率较高,但是预留一半的内存区域用来存放存活的对象,占用额外的内存空间
|
||||
- 如果出现存活对象数量比较多的时候,需要复制较多的对象 效率低
|
||||
- 假如是在老年代区域,99%的对象都是存活的,则性能底,所以老年代不适合这个算法
|
||||
|
||||
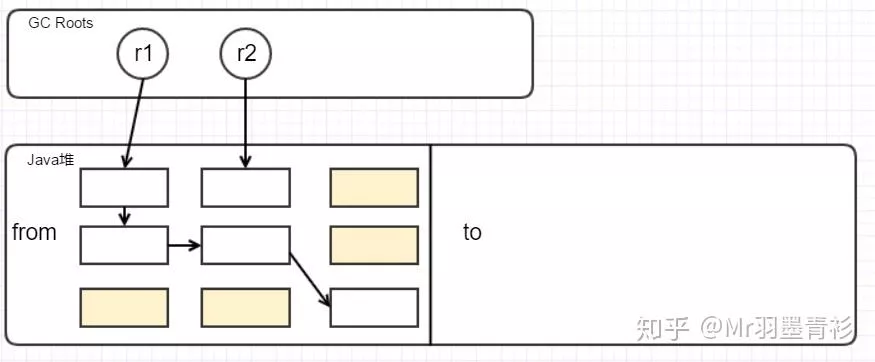
|
||||
|
||||
复制过程如下,GC会将五个存活对象复制到to区,并且保证在to区内存空间上的连续性。
|
||||
|
||||
|
||||
|
||||
最后,将from区中的垃圾对象清除。
|
||||
|
||||
|
||||
|
||||
## **垃圾回收算法之标记-整理算法**
|
||||
|
||||
标记-整理算法(Mark-Compact Algorithm) 是一种常见的垃圾回收(GC)算法,主要用于解决 标记-清除算法(Mark-Sweep) 产生的内存碎片问题。它通常被用于 Java 的老年代(Old Generation)垃圾回收中。
|
||||
|
||||
标记-整理算法主要分为两大阶段:
|
||||
|
||||
标记阶段(Mark Phase)
|
||||
|
||||
和标记-清除算法一样,从 GC Roots 出发,遍历所有可达对象,并将其标记为“存活”状态。
|
||||
|
||||
整理阶段(Compact Phase)
|
||||
|
||||
将所有存活对象向内存的一端移动(通常是低地址方向)。
|
||||
|
||||
移动后会更新对象引用地址,以保证程序继续正确运行。
|
||||
|
||||
移动完成后,直接清理边界以后的内存空间。
|
||||
|
||||
|
||||
|
||||
| **特点** | **标记-清除算法** | **标记-整理算法** |
|
||||
| ------ | ------------- | ------------- |
|
||||
| 内存碎片 | 会产生碎片 | 不会产生碎片 |
|
||||
| 效率 | 清除快(只清除不可达对象) | 较慢(需要移动对象) |
|
||||
| 适用场景 | 适用于对象回收率较高的情况 | 适用于对象存活率较高的情况 |
|
||||
|
||||
## 垃圾回收算法之-分代算法
|
||||
|
||||

|
||||
|
||||
新生代分为eden区、from区、to区,老年代是一整块内存空间
|
||||
|
||||
分代算法将内存区域分为两部分:新生代和老年代。
|
||||
|
||||
根据新生代和老年代中对象的不同特点,使用不同的GC算法。
|
||||
|
||||
新生代对象的特点是:创建出来没多久就可以被回收(例如虚拟机栈中创建的对象,方法出栈就会销毁)。也就是说,每次回收时,大部分是垃圾对象,所以新生代适用于复制算法。
|
||||
|
||||
老年代的特点是:经过多次GC,依然存活。也就是说,每次GC时,大部分是存活对象,所以老年代适用于标记压缩算法。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 分代算法执行过程
|
||||
|
||||
---
|
||||
40
src/content/posts/Java/JVM/Java类加载器与双亲委派机制.md
Normal file
40
src/content/posts/Java/JVM/Java类加载器与双亲委派机制.md
Normal file
@@ -0,0 +1,40 @@
|
||||
---
|
||||
title: Java类加载器与双亲委派机制
|
||||
published: 2025-07-18
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [Java,类加载器,ClassLoader,双亲委派机制]
|
||||
category: 'Java > JVM'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# Java类加载器和双亲委派机制
|
||||
|
||||
[Java 虚拟机之类加载](https://dunwu.github.io/waterdrop/pages/3e37ea6e/#%E7%B1%BB%E5%8A%A0%E8%BD%BD%E6%9C%BA%E5%88%B6)
|
||||
|
||||
## Java类加载器层级
|
||||
|
||||
Java类加载器从高到低分为以下层级(以JDK 8为例):
|
||||
|
||||
1. **启动类加载器(Bootstrap ClassLoader)** :加载JRE的`lib`目录下的核心类库(如`rt.jar`)。
|
||||
2. **扩展类加载器(Extension ClassLoader)** :加载`lib/ext`目录下的扩展类。
|
||||
3. **应用程序类加载器(Application ClassLoader)** :加载用户类路径(ClassPath)下的类。
|
||||
4. **自定义类加载器**:用户可自定义类加载器(需继承`ClassLoader`)。
|
||||
|
||||
## 什么是双亲委派机制
|
||||
|
||||
**双亲委派机制** 是Java类加载器的核心工作机制。它的核心思想是:当一个类加载器需要加载某个类时,不会直接尝试自己加载,而是将这个请求**逐级向上委托给父类加载器**处理。只有当所有父类加载器都无法完成加载时,子类加载器才会尝试自己加载。
|
||||
|
||||
## ## 示意图
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[深入理解Java双亲委派机制:原理、意义与实战示例 - 云熙橙 - 博客园](https://www.cnblogs.com/xchangting/articles/18744083)
|
||||
|
||||
## 双亲委派机制的好处
|
||||
|
||||
1. **保障核心类库的安全**防止用户自定义的类(如`java.lang.Object`)覆盖JVM核心类。例如,如果用户编写了一个恶意`String`类,双亲委派机制会优先加载核心库中的`String`,从而避免安全隐患。
|
||||
2. **避免重复加载**同一个类只会被一个类加载器加载一次,防止内存中出现多个相同类的副本,确保类的唯一性。
|
||||
3. **实现代码隔离**不同类加载器加载的类属于不同的命名空间,天然支持模块化(如Tomcat为每个Web应用分配独立的类加载器)。
|
||||
79
src/content/posts/Java/JVM/Jvm分代回收机制.md
Normal file
79
src/content/posts/Java/JVM/Jvm分代回收机制.md
Normal file
@@ -0,0 +1,79 @@
|
||||
---
|
||||
title: Jvm分代回收机制
|
||||
published: 2025-07-18
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [分代回收,JVM]
|
||||
category: 'Java > JVM'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# 分代回收
|
||||
|
||||
[juejin.cn](https://juejin.cn/post/7474503566154858536)
|
||||
|
||||
[【GC系列】JVM堆内存分代模型及常见的垃圾回收器-腾讯云开发者社区-腾讯云](https://cloud.tencent.com/developer/article/1755848)
|
||||
|
||||
[Eden与Survivor区 · Homurax's Blog](https://blog.homurax.com/2018/09/17/eden-survivor/)
|
||||
|
||||
[Java 虚拟机之垃圾收集](https://dunwu.github.io/waterdrop/pages/587898a0/)
|
||||
|
||||
[JVM内存分配策略](https://linqiankun.github.io/hexoblog/md/jvm/JVM%E5%86%85%E5%AD%98%E5%88%86%E9%85%8D%E7%AD%96%E7%95%A5/)
|
||||
|
||||
现代JVM堆内存的典型划分:
|
||||
|
||||
1. 年轻代(Young Generation)
|
||||
2. 老年代(Old Generation)
|
||||
3. 永久代/元空间(Permanent Gen/Metaspace)
|
||||
|
||||
## JDK7堆空间内部结构
|
||||
|
||||
|
||||
|
||||
特点:
|
||||
|
||||
永久代位于堆内存中
|
||||
|
||||
字符串常量池存放在永久代
|
||||
|
||||
方法区使用永久代实现
|
||||
|
||||
## JDK8堆空间内部结构
|
||||
|
||||
|
||||
|
||||
永久代被元空间替换,元空间不属于堆内存。
|
||||
|
||||
元空间使用本地内存
|
||||
|
||||
字符串常量池移至堆内存
|
||||
|
||||
方法区改由元空间实现。
|
||||
|
||||
## 年轻代与老年代
|
||||
|
||||
JVM 内置的通用垃圾回收原则。堆内存划分为 Eden、Survivor(年轻代) , Tenured/Old (老年代)空间:
|
||||
|
||||
|
||||
|
||||
核心规则:
|
||||
|
||||
1. 对象优先在Eden区分配
|
||||
2. 大对象直接进入老年代
|
||||
3. 长期存活对象进入老年代(默认年龄阈值15)
|
||||
4. 动态年龄判断(Survivor区中相同年龄对象总和超过50%时候晋升)
|
||||
|
||||
在 JVM 中,**年龄阈值(Tenuring Threshold)** 是一个关键的参数,它决定了新生代(Young Generation)中的对象需要经历多少次垃圾回收(Minor GC)仍然存活,才会被晋升(Promotion)到老年代(Old Generation)。
|
||||
|
||||
年轻代分为Eden区和Survivor区,Survivor区又分为S0,S1,S0,S1其中一个作为使用区(from),一个作为空闲区(to)(不固定,可能S0是空闲区,也可能是使用区)
|
||||
在Minor GC开始以后(会回收Eden区和使用区中的对象),逃过第一轮GC的,在Eden区和使用区中的对象,会被丢在空闲区,接下来将使用区和空闲区互换(空闲区变使用区,使用区变空闲区),等待下一次Eden区满进行Minor GC,以此不断循环(每复制一次,年龄就会 + 1)
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
# 堆空间大小设置
|
||||
|
||||
|
||||
|
||||

|
||||
44
src/content/posts/Java/JVM/Jvm常见垃圾收集器.md
Normal file
44
src/content/posts/Java/JVM/Jvm常见垃圾收集器.md
Normal file
@@ -0,0 +1,44 @@
|
||||
---
|
||||
title: Jvm常见垃圾收集器
|
||||
published: 2025-07-18
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [Java,JVM,垃圾收集器]
|
||||
category: 'Java > JVM'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# Java中常见的垃圾收集器
|
||||
|
||||
GC收集器有哪些?
|
||||
|
||||
1.serial收集器
|
||||
单线程,工作时必须暂停其他工作线程。多用于client机器上,使用复制算法
|
||||
2.ParNew收集器
|
||||
serial收集器的多线程版本,server模式下虚拟机首选的新生代收集器。复制算法
|
||||
3.Parallel Scavenge收集器
|
||||
复制算法,可控制吞吐量的收集器。吞吐量即有效运行时间。
|
||||
4.Serial Old收集器
|
||||
serial的老年代版本,使用整理算法。
|
||||
5.Parallel Old收集器
|
||||
第三种收集器的老年代版本,多线程,标记整理
|
||||
6.CMS收集器
|
||||
目标是最短回收停顿时间。
|
||||
|
||||
7.G1收集器,基本思想是化整为零,将堆分为多个Region,优先收集回收价值最大的Region。
|
||||
|
||||
[垃圾收集器_java垃圾收集器-CSDN博客](https://blog.csdn.net/binbinxyz/article/details/141821712)
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
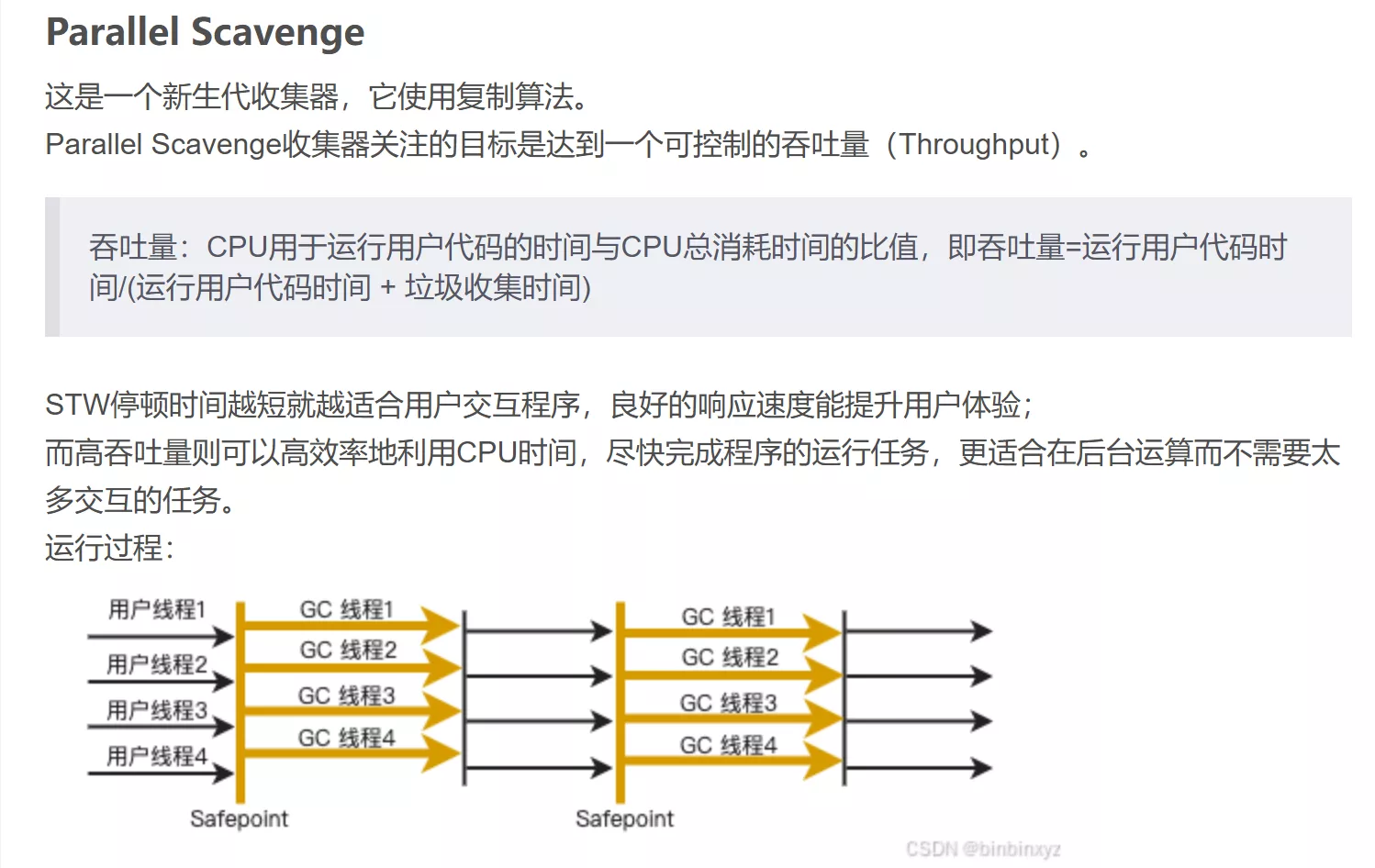
|
||||
|
||||
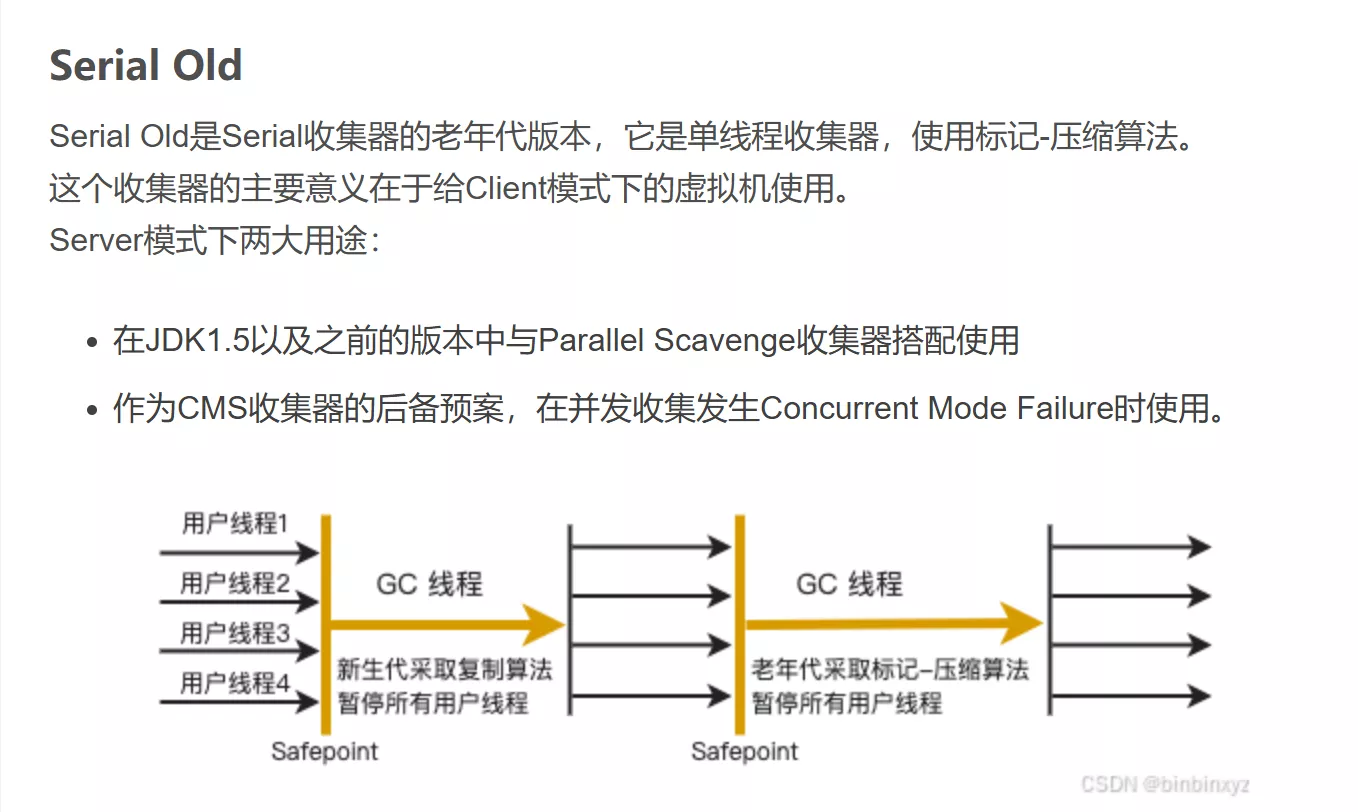
|
||||
|
||||
# G1垃圾回收器
|
||||
|
||||
[G1垃圾回收](Java%E4%B8%AD%E5%B8%B8%E8%A7%81%E7%9A%84%E5%9E%83%E5%9C%BE%E6%94%B6%E9%9B%86%E5%99%A8%2022a49a1194e98020a75ced52b5d871d7/G1%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6%2022a49a1194e980e9bbf7e2a6c0f3e4c6.md)
|
||||
24
src/content/posts/Java/Java内存模型.md
Normal file
24
src/content/posts/Java/Java内存模型.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
title: Java内存模型
|
||||
published: 2025-09-13
|
||||
description: ' Java内存模型 '
|
||||
image: ''
|
||||
tags: ['JMM','Java内存模型']
|
||||
category: 'Java > 面试题'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
Java内存模型,是Java虚拟机定义的一种规范,用来描述多线程程序中的变量如何在内存中读取数据,何时会把数据写回主内存。
|
||||
|
||||
JMM的核心目标是确保多线程环境下的**可见性,有序性和原子性**,从而避免由于硬件和编译器优化带来的不一致问题。
|
||||
- 可见性:确保一个线程对共享变量的修改,其他线程能够及时看到。关键字 `volatile`是用来保证可见性的,它强制线程每次读写的时候都从主内存中获取最新值。
|
||||
- 有序性:确保程序执行的顺序符合代码的书写顺序。JMM允许某些指令重排序,来提高性能,但会保证线程内的操作顺序不会被破坏,通过happens-before关系保证跨线程的有序性。
|
||||
- 原子性:确保操作的不可分割性,要么全部成功,要么全部失败。 例如synchronized关键字能确保方法或者代码块的原子性。
|
||||
|
||||
|
||||
## 参考
|
||||
JMM 会把内存分为本地内存和主存,每个线程都有它自己的私有化的本地内存,还有个存储共享数据的主存。
|
||||
|
||||
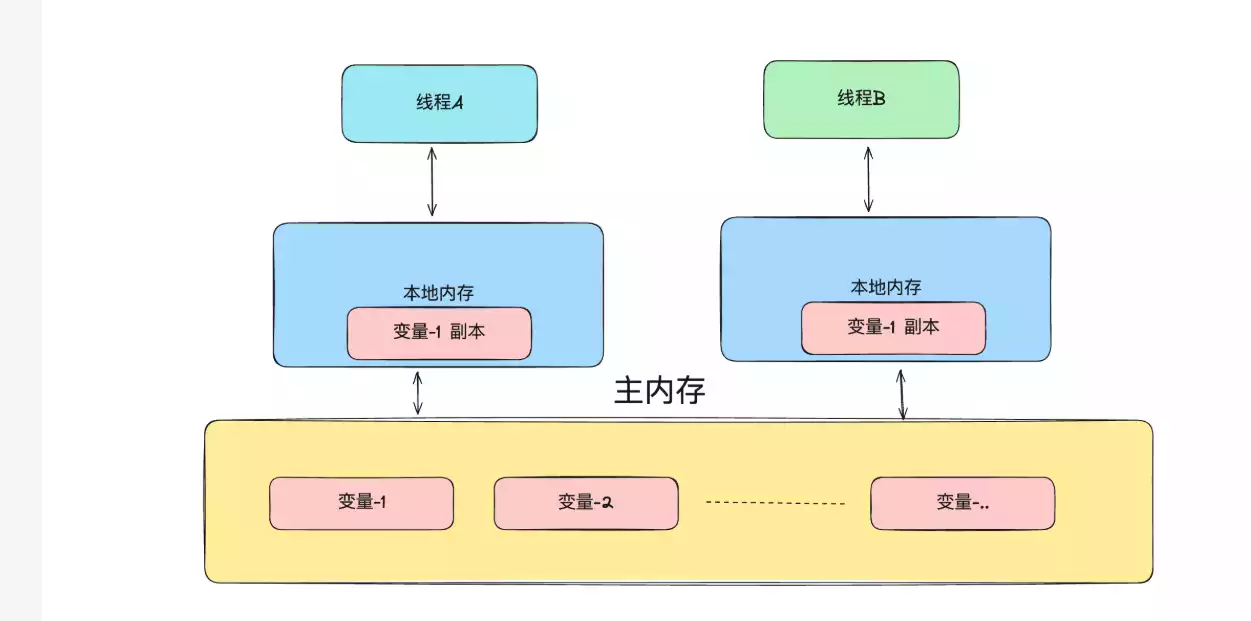
|
||||
372
src/content/posts/Java/Java函数式接口.md
Normal file
372
src/content/posts/Java/Java函数式接口.md
Normal file
@@ -0,0 +1,372 @@
|
||||
---
|
||||
title: Java函数式接口
|
||||
published: 2025-07-19
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [函数式接口, Java, 编程]
|
||||
category: 'Java'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
<https://www.cnblogs.com/dgwblog/p/11739500.html>
|
||||
|
||||
<https://juejin.cn/post/6844903892166148110>
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## 1. `Supplier<T>` - 数据的供给者 🎁
|
||||
|
||||
**接口定义**:`@FunctionalInterface public interface Supplier<T> { T get(); }`
|
||||
|
||||
**核心作用**:
|
||||
`Supplier` 接口的核心职责是**生产或提供数据**,它不接受任何参数,但会返回一个 `T` 类型的结果。你可以把它想象成一个“工厂”或者“源头”,当你需要一个特定类型的对象时,就调用它的 `get()` 方法。
|
||||
|
||||
**方法详解**:
|
||||
|
||||
* `T get()`: 这是 `Supplier` 接口中唯一的抽象方法。调用它时,会执行你提供的 Lambda 表达式或方法引用所定义的逻辑,并返回一个结果。
|
||||
|
||||
**常见应用场景**:
|
||||
|
||||
* **延迟加载/创建对象**:当某个对象的创建成本较高,或者并非立即需要时,可以使用 `Supplier` 来推迟其创建,直到真正使用时才调用 `get()`。
|
||||
* **生成默认值或配置信息**:提供一个默认对象或从某个源(如配置文件、数据库)获取配置。
|
||||
* **生成随机数据**:如示例中的随机数生成器。
|
||||
* **作为工厂方法**:在更复杂的场景中,`Supplier` 可以作为创建对象的简单工厂。
|
||||
|
||||
**您的示例代码分析** (`SupplierExample.java`):
|
||||
|
||||
```java
|
||||
import java.util.Random;
|
||||
import java.util.function.Supplier;
|
||||
|
||||
public class SupplierExample {
|
||||
|
||||
// 示例方法1: 接收一个 Supplier 来获取随机整数
|
||||
public static Integer getRandomNumber(Supplier<Integer> randomNumberSupplier) {
|
||||
// 调用 randomNumberSupplier 的 get 方法来执行其提供的逻辑
|
||||
return randomNumberSupplier.get();
|
||||
}
|
||||
|
||||
// 示例方法2: 接收一个 Supplier 来创建问候语字符串
|
||||
public static String createGreetingMessage(Supplier<String> greetingSupplier) {
|
||||
return greetingSupplier.get();
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
// 场景1: 获取随机数
|
||||
// Lambda 表达式实现 Supplier: () -> new Random().nextInt(100)
|
||||
// 这个 Lambda 不接受参数,返回一个 0-99 的随机整数
|
||||
Supplier<Integer> randomIntSupplier = () -> new Random().nextInt(100);
|
||||
Integer num = getRandomNumber(randomIntSupplier); // 传递行为
|
||||
System.out.println("随机数: " + num);
|
||||
|
||||
// 场景2: 获取固定数字
|
||||
// Lambda 表达式实现 Supplier: () -> 42
|
||||
// 这个 Lambda 总是返回固定的数字 42
|
||||
Supplier<Integer> fixedIntSupplier = () -> 42;
|
||||
Integer fixedNum = getRandomNumber(fixedIntSupplier);
|
||||
System.out.println("固定数字: " + fixedNum);
|
||||
|
||||
// 场景3: 创建不同的问候语
|
||||
Supplier<String> englishGreeting = () -> "Hello, World!";
|
||||
System.out.println(createGreetingMessage(englishGreeting)); // 输出: Hello, World!
|
||||
|
||||
Supplier<String> spanishGreeting = () -> "¡Hola, Mundo!";
|
||||
System.out.println(createGreetingMessage(spanishGreeting)); // 输出: ¡Hola, Mundo!
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**代码解读**:
|
||||
|
||||
* `getRandomNumber` 和 `createGreetingMessage` 方法本身并不关心数字或字符串是如何产生的,它们只依赖传入的 `Supplier` 来提供结果。这体现了**行为参数化**——方法接受行为(通过函数式接口)作为参数。
|
||||
* 在 `main` 方法中:
|
||||
* `randomIntSupplier`: 定义了一个行为——“生成一个0到99的随机整数”。
|
||||
* `fixedIntSupplier`: 定义了另一个行为——“总是提供数字42”。
|
||||
* `englishGreeting` 和 `spanishGreeting`: 定义了不同的行为来提供特定的字符串。
|
||||
* 通过将不同的 `Supplier` 实现传递给同一个方法 (`getRandomNumber` 或 `createGreetingMessage`),我们可以获得不同的结果,而无需修改方法本身。
|
||||
|
||||
**关键益处**:
|
||||
|
||||
* **灵活性**:可以轻松替换不同的供给逻辑。
|
||||
* **解耦**:数据的使用者和数据的生产者解耦。
|
||||
* **可测试性**:可以方便地传入 mock 的 `Supplier` 进行单元测试。
|
||||
|
||||
---
|
||||
|
||||
## 2. `Function<T, R>` - 数据的转换器/映射器 🔄
|
||||
|
||||
**接口定义**:`@FunctionalInterface public interface Function<T, R> { R apply(T t); }`
|
||||
|
||||
**核心作用**:
|
||||
`Function` 接口的核心职责是**将一个类型 `T` 的输入参数转换或映射成另一个类型 `R` 的输出结果**。它就像一个数据处理管道中的一个环节,接收数据,进行处理,然后传递给下一个环节。
|
||||
|
||||
**方法详解**:
|
||||
|
||||
* `R apply(T t)`: 这是 `Function` 的核心方法。它接受一个 `T` 类型的参数 `t`,对其执行Lambda表达式或方法引用中定义的转换逻辑,并返回一个 `R` 类型的结果。
|
||||
|
||||
**常见应用场景**:
|
||||
|
||||
* **数据转换**:例如,将字符串转换为整数,将日期对象格式化为字符串,或者如示例中计算字符串长度、数字平方。
|
||||
* **对象属性提取**:从一个复杂对象中提取某个特定属性的值。例如,`Person -> String (person.getName())`。
|
||||
* **链式操作**:`Function` 接口提供了 `andThen()` 和 `compose()` 默认方法,可以方便地将多个 `Function` 串联起来形成一个处理流水线。
|
||||
|
||||
**您的示例代码分析** (`FunctionExample.java`):
|
||||
|
||||
```java
|
||||
import java.util.function.Function;
|
||||
|
||||
public class FunctionExample {
|
||||
|
||||
// 示例方法1: 接收一个 Function 来计算字符串长度
|
||||
public static Integer getStringLength(String text, Function<String, Integer> lengthCalculator) {
|
||||
// 调用 lengthCalculator 的 apply 方法,传入 text,执行其转换逻辑
|
||||
return lengthCalculator.apply(text);
|
||||
}
|
||||
|
||||
// 示例方法2: 接收一个 Function 来计算数字的平方
|
||||
public static Integer squareNumber(Integer number, Function<Integer, Integer> squareFunction) {
|
||||
return squareFunction.apply(number);
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
// 场景1: 计算字符串长度
|
||||
String myString = "Java Functional";
|
||||
// Lambda 表达式实现 Function: s -> s.length()
|
||||
// 这个 Lambda 接受一个 String s,返回其长度 (Integer)
|
||||
Function<String, Integer> lengthLambda = s -> s.length();
|
||||
Integer length = getStringLength(myString, lengthLambda);
|
||||
System.out.println("字符串 '" + myString + "' 的长度是: " + length);
|
||||
|
||||
// 使用方法引用 (Method Reference) 实现 Function: String::length
|
||||
// String::length 等价于 s -> s.length(),更为简洁
|
||||
Integer lengthUsingMethodRef = getStringLength("Test", String::length);
|
||||
System.out.println("字符串 'Test' 的长度是: " + lengthUsingMethodRef);
|
||||
|
||||
// 场景2: 计算数字平方
|
||||
Integer num = 5;
|
||||
// Lambda 表达式实现 Function: n -> n * n
|
||||
// 接受一个 Integer n,返回 n 的平方 (Integer)
|
||||
Function<Integer, Integer> squareLambda = n -> n * n;
|
||||
Integer squared = squareNumber(num, squareLambda);
|
||||
System.out.println(num + " 的平方是: " + squared);
|
||||
|
||||
Integer anotherNum = 10;
|
||||
// 多行 Lambda 表达式
|
||||
Function<Integer, Integer> verboseSquareLambda = x -> {
|
||||
System.out.println("正在计算 " + x + " 的平方..."); // Lambda 可以包含多条语句
|
||||
return x * x;
|
||||
};
|
||||
Integer squaredAgain = squareNumber(anotherNum, verboseSquareLambda);
|
||||
System.out.println(anotherNum + " 的平方是: " + squaredAgain);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**代码解读**:
|
||||
|
||||
* `getStringLength` 和 `squareNumber` 方法定义了操作的框架,但具体的转换逻辑由传入的 `Function` 对象决定。
|
||||
* 在 `main` 方法中:
|
||||
* `s -> s.length()` 和 `String::length` 都是 `Function<String, Integer>` 的实例,它们定义了“从字符串到其长度整数”的转换。
|
||||
* `n -> n * n` 是 `Function<Integer, Integer>` 的实例,定义了“从整数到其平方整数”的转换。
|
||||
* 多行 Lambda `verboseSquareLambda` 展示了更复杂的转换逻辑可以被封装。
|
||||
* 这种方式使得我们可以为同一个通用方法(如 `getStringLength`)提供不同的转换策略。
|
||||
|
||||
**关键益处**:
|
||||
|
||||
* **代码复用**:通用的转换逻辑可以被封装成 `Function` 并在多处使用。
|
||||
* **可组合性**:通过 `andThen` 和 `compose` 可以构建复杂的转换流。
|
||||
* **清晰性**:将数据转换的意图明确表达出来。
|
||||
|
||||
---
|
||||
|
||||
## 3. `BiConsumer<T, U>` - 双参数的消费者/执行者 🤝
|
||||
|
||||
**接口定义**:`@FunctionalInterface public interface BiConsumer<T, U> { void accept(T t, U u); }`
|
||||
|
||||
**核心作用**:
|
||||
`BiConsumer` 接口的核心职责是**对两个不同类型(或相同类型)的输入参数 `T` 和 `U` 执行某个操作或产生某种副作用,但它不返回任何结果 (void)**。你可以把它看作是需要两个输入才能完成其工作的“执行者”。
|
||||
|
||||
**方法详解**:
|
||||
|
||||
* `void accept(T t, U u)`: 这是 `BiConsumer` 的核心方法。它接受两个参数 `t` 和 `u`,并对它们执行 Lambda 表达式或方法引用中定义的操作。由于返回类型是 `void`,它通常用于执行有副作用的操作,如打印、修改集合、更新数据库等。
|
||||
|
||||
**常见应用场景**:
|
||||
|
||||
* **处理键值对**:非常适合用于迭代 `Map` 的条目,如 `Map.forEach()` 方法就接受一个 `BiConsumer<K, V>`。
|
||||
* **同时操作两个相关对象**:当一个操作需要两个输入,并且不产生新的独立结果时。例如,将一个对象的属性设置到另一个对象上。
|
||||
* **配置或初始化**:使用两个参数来配置某个组件。
|
||||
|
||||
**您的示例代码分析** (`BiConsumerExample.java`):
|
||||
|
||||
```java
|
||||
import java.util.HashMap;
|
||||
import java.util.Map;
|
||||
import java.util.function.BiConsumer;
|
||||
|
||||
public class BiConsumerExample {
|
||||
|
||||
// 示例方法1: 接收 BiConsumer 来打印键和值
|
||||
public static <K, V> void printMapEntry(K key, V value, BiConsumer<K, V> entryPrinter) {
|
||||
// 调用 entryPrinter 的 accept 方法,传入 key 和 value
|
||||
entryPrinter.accept(key, value);
|
||||
}
|
||||
|
||||
// 示例2 在 main 中直接演示了更常见的 Map 操作方式
|
||||
|
||||
// 辅助内部类,如果 BiConsumer 需要一次性接收多个信息 (在此示例中未直接用于核心 BiConsumer 演示)
|
||||
// static class Pair<F, S> {
|
||||
// F first; S second;
|
||||
// Pair(F f, S s) { this.first = f; this.second = s; }
|
||||
// }
|
||||
|
||||
public static void main(String[] args) {
|
||||
// 场景1: 使用 printMapEntry 打印键值
|
||||
// Lambda 表达式实现 BiConsumer: (k, v) -> System.out.println("键: " + k + ", 值: " + v)
|
||||
// 接受一个 String k 和一个 Integer v,然后打印它们
|
||||
BiConsumer<String, Integer> simplePrinter = (k, v) -> System.out.println("键: " + k + ", 值: " + v);
|
||||
printMapEntry("年龄", 30, simplePrinter);
|
||||
printMapEntry("数量", 100, simplePrinter);
|
||||
|
||||
// 场景2: 使用 BiConsumer 来填充 Map
|
||||
Map<String, String> config = new HashMap<>();
|
||||
// Lambda 表达式实现 BiConsumer: (key, value) -> config.put(key, value)
|
||||
// 这个 Lambda 捕获了外部的 'config' Map 对象。
|
||||
// 它接受 String key 和 String value,并将它们放入 config Map 中。
|
||||
BiConsumer<String, String> mapPutter = (key, value) -> config.put(key, value);
|
||||
|
||||
mapPutter.accept("user.name", "Alice"); // 执行操作:config.put("user.name", "Alice")
|
||||
mapPutter.accept("user.role", "Admin"); // 执行操作:config.put("user.role", "Admin")
|
||||
System.out.println("配置Map: " + config);
|
||||
|
||||
// 场景3: Map.forEach() 的典型用法
|
||||
// Map 的 forEach 方法直接接受一个 BiConsumer<K, V>
|
||||
System.out.println("遍历Map:");
|
||||
config.forEach((key, value) -> { // 这里的 (key, value) -> {...} 就是一个 BiConsumer
|
||||
System.out.println("配置项 - " + key + ": " + value);
|
||||
});
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**代码解读**:
|
||||
|
||||
* `printMapEntry` 方法接受一个键、一个值和一个 `BiConsumer`,该 `BiConsumer` 定义了如何处理这对键值。
|
||||
* 在 `main` 方法中:
|
||||
* `simplePrinter`: 定义了一个行为——“接收一个键和一个值,并将它们打印到控制台”。
|
||||
* `mapPutter`: 定义了一个行为——“接收一个键和一个字符串值,并将它们存入外部的 `config` Map”。这里 Lambda 表达式捕获了外部变量 `config`,这是一种常见的用法。
|
||||
* `config.forEach(...)`: 这是 `BiConsumer` 最经典的用例之一。`forEach` 方法遍历 `Map` 中的每个条目,并对每个键值对执行提供的 `BiConsumer` 逻辑。
|
||||
|
||||
**关键益处**:
|
||||
|
||||
* **处理成对数据**:专门设计用于需要两个输入的场景。
|
||||
* **与集合(尤其是Map)的良好集成**:`Map.forEach` 是一个很好的例子。
|
||||
* **封装副作用操作**:可以将对两个参数的副作用操作(如修改、打印)封装起来。
|
||||
|
||||
---
|
||||
|
||||
## 4. `Consumer<T>` - 数据的消费者/执行者 🍽️
|
||||
|
||||
**接口定义**:`@FunctionalInterface public interface Consumer<T> { void accept(T t); }`
|
||||
|
||||
**核心作用**:
|
||||
`Consumer` 接口的核心职责是**对单个输入参数 `T` 执行某个操作或产生某种副作用,它不返回任何结果 (void)**。你可以把它看作是数据的“终点”或某个动作的执行者,它“消费”数据但不产生新的输出数据。
|
||||
|
||||
**方法详解**:
|
||||
|
||||
* `void accept(T t)`: 这是 `Consumer` 的核心方法。它接受一个 `T` 类型的参数 `t`,并对其执行 Lambda 表达式或方法引用中定义的操作。因为返回 `void`,它主要用于执行那些为了副作用而进行的操作(如打印、修改对象状态、写入文件等)。
|
||||
|
||||
**常见应用场景**:
|
||||
|
||||
* **迭代集合并处理元素**:`List.forEach()` 方法接受一个 `Consumer<T>`,对列表中的每个元素执行指定操作。
|
||||
* **打印/日志记录**:将信息输出到控制台、文件或其他日志系统。
|
||||
* **更新对象状态**:修改传入对象的属性。
|
||||
* **回调**:在某个异步操作完成后执行一个 `Consumer` 定义的动作。
|
||||
|
||||
**您的示例代码分析** (`ConsumerExample.java`):
|
||||
|
||||
```java
|
||||
import java.util.Arrays;
|
||||
import java.util.List;
|
||||
import java.util.function.Consumer;
|
||||
|
||||
public class ConsumerExample {
|
||||
|
||||
// 示例方法1: 接收 Consumer 来展示单个项目
|
||||
public static <T> void displayItem(T item, Consumer<T> itemDisplayer) {
|
||||
// 调用 itemDisplayer 的 accept 方法,传入 item,执行其消费逻辑
|
||||
itemDisplayer.accept(item);
|
||||
}
|
||||
|
||||
// 示例方法2: 接收 Consumer 来处理列表中的每个项目
|
||||
public static <T> void processListItems(List<T> list, Consumer<T> itemProcessor) {
|
||||
for (T item : list) {
|
||||
itemProcessor.accept(item); // 对列表中的每个 item 执行 itemProcessor 的逻辑
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
// 场景1: 使用 displayItem 打印信息
|
||||
// Lambda 表达式实现 Consumer: message -> System.out.println("消息: " + message)
|
||||
// 接受一个 String message,然后打印它
|
||||
Consumer<String> consolePrinter = message -> System.out.println("消息: " + message);
|
||||
displayItem("你好,函数式接口!", consolePrinter);
|
||||
|
||||
// 多行 Lambda 实现 Consumer,进行更复杂的打印
|
||||
Consumer<Integer> detailedPrinter = number -> {
|
||||
System.out.println("--- 数字详情 ---");
|
||||
System.out.println("值: " + number);
|
||||
System.out.println("是否偶数: " + (number % 2 == 0));
|
||||
System.out.println("----------------");
|
||||
};
|
||||
displayItem(10, detailedPrinter);
|
||||
displayItem(7, System.out::println); // 方法引用: System.out::println 等价于 x -> System.out.println(x)
|
||||
|
||||
// 场景2: 使用 processListItems 处理列表
|
||||
List<String> names = Arrays.asList("爱丽丝", "鲍勃", "查理");
|
||||
|
||||
System.out.println("\n打印名字:");
|
||||
// Lambda: name -> System.out.println("你好, " + name + "!")
|
||||
// 对列表中的每个名字,执行打印问候语的操作
|
||||
processListItems(names, name -> System.out.println("你好, " + name + "!"));
|
||||
|
||||
System.out.println("\n将名字转换为大写并打印 (仅打印,不修改原列表):");
|
||||
// Lambda: name -> System.out.println(name.toUpperCase())
|
||||
// 对列表中的每个名字,先转大写,然后打印
|
||||
processListItems(names, name -> System.out.println(name.toUpperCase()));
|
||||
|
||||
// Consumer 也可以有副作用,比如修改外部状态 (通常需谨慎使用以避免复杂性)
|
||||
StringBuilder allNames = new StringBuilder();
|
||||
// Lambda: name -> allNames.append(name).append(" ")
|
||||
// 这个 Consumer 修改了外部的 allNames 对象
|
||||
processListItems(names, name -> allNames.append(name).append(" "));
|
||||
System.out.println("\n拼接所有名字: " + allNames.toString().trim());
|
||||
|
||||
// List.forEach 的典型用法
|
||||
System.out.println("\n使用 List.forEach 打印名字(大写):");
|
||||
names.forEach(name -> System.out.println(name.toUpperCase())); // name -> System.out.println(...) 是一个Consumer
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**代码解读**:
|
||||
|
||||
* `displayItem` 方法接受一个项目和一个 `Consumer`,该 `Consumer` 定义了如何“消费”或处理这个项目。
|
||||
* `processListItems` 方法遍历列表,并对每个元素应用传入的 `Consumer` 逻辑。这与 `List.forEach()` 的行为非常相似。
|
||||
* 在 `main` 方法中:
|
||||
* `consolePrinter` 和 `detailedPrinter` 定义了不同的打印行为。`System.out::println` 是一个简洁的方法引用,用于直接打印。
|
||||
* 在处理 `names` 列表时,通过传递不同的 `Consumer` 给 `processListItems`,实现了不同的处理逻辑(简单问候、转换为大写打印、追加到 `StringBuilder`)。
|
||||
* `allNames.append(...)` 的例子展示了 `Consumer` 如何产生副作用(修改外部对象的状态)。虽然强大,但在复杂系统中应谨慎使用副作用,以保持代码的可预测性。
|
||||
* `names.forEach(...)` 直接使用了 `List` 接口内置的 `forEach` 方法,该方法就接受一个 `Consumer`。
|
||||
|
||||
**关键益处**:
|
||||
|
||||
* **执行动作**:非常适合表示对数据执行的无返回值的操作。
|
||||
* **迭代与处理**:与集合框架(如 `List.forEach`)完美配合,简化迭代代码。
|
||||
* **封装副作用**:将有副作用的操作(如I/O、UI更新)封装到 `Consumer` 中,使得代码意图更清晰。
|
||||
|
||||
---
|
||||
158
src/content/posts/Java/Spring/SpringBean生命周期.md
Normal file
158
src/content/posts/Java/Spring/SpringBean生命周期.md
Normal file
@@ -0,0 +1,158 @@
|
||||
---
|
||||
title: SpringBean生命周期
|
||||
published: 2025-07-28
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ["Spring","Java"]
|
||||
category: 'Java > Spring'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# Bean 的生命周期
|
||||
|
||||

|
||||
|
||||
Bean生命周期可以粗略的划分为五大步:
|
||||
|
||||
第一步:实例化Bean
|
||||
第二步:Bean属性赋值
|
||||
第三步:初始化Bean
|
||||
第四步:使用Bean
|
||||
第五步:销毁Bean
|
||||

|
||||
|
||||
```java
|
||||
package com.powercode.spring6.beans;
|
||||
|
||||
public class User {
|
||||
private String name;
|
||||
public User() {
|
||||
System.out.println("1.实例化Bean");
|
||||
}
|
||||
|
||||
public void setName(String name) {
|
||||
this.name = name;
|
||||
System.out.println("2.Bean属性赋值");
|
||||
}
|
||||
|
||||
public void initBean(){
|
||||
System.out.println("3.初始化Bean");
|
||||
}
|
||||
|
||||
public void destroyBean(){
|
||||
System.out.println("5.销毁Bean");
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
2024-01-11 12:21:23 618 [main] DEBUG org.springframework.context.support.ClassPathXmlApplicationContext - Refreshing org.springframework.context.support.ClassPathXmlApplicationContext@183e8023
|
||||
2024-01-11 12:21:23 715 [main] DEBUG org.springframework.beans.factory.xml.XmlBeanDefinitionReader - Loaded 1 bean definitions from class path resource [spring12.xml]
|
||||
2024-01-11 12:21:23 732 [main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'userBean'
|
||||
1.实例化Bean
|
||||
2.Bean属性赋值
|
||||
3.初始化Bean
|
||||
4.使用Bean
|
||||
2024-01-11 12:21:23 774 [main] DEBUG org.springframework.context.support.ClassPathXmlApplicationContext - Closing org.springframework.context.support.ClassPathXmlApplicationContext@183e8023, started on Thu Jan 11 12:21:23 CST 2024
|
||||
5.销毁Bean
|
||||
2024-01-11 12:21:23 774 [main] DEBUG org.springframework.beans.factory.support.DisposableBeanAdapter - Custom destroy method 'destroyBean' on bean with name 'userBean' completed
|
||||
|
||||
进程已结束,退出代码为 0
|
||||
|
||||
```
|
||||
|
||||
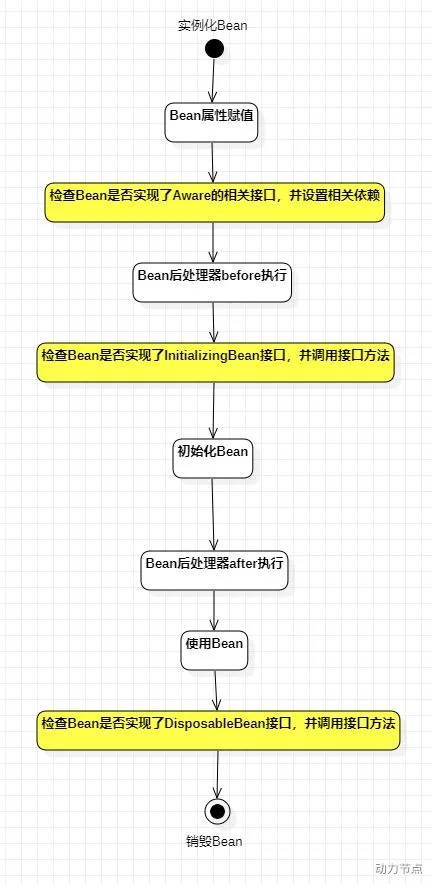
|
||||
|
||||
## Bean后处理器
|
||||
加上后处理器就变成七步了:
|
||||

|
||||
|
||||
|
||||
### BeanPostProcessor 的核心作用
|
||||
BeanPostProcessor 本身并不属于某个特定 Bean 的生命周期,而是作用于容器中所有 Bean 的 “全局处理器”。它的核心功能是:在 Bean 完成实例化和属性赋值后、初始化方法(如 afterPropertiesSet() 或 init-method)执行前后,对 Bean 进行加工或增强。
|
||||
|
||||
上图中检查Bean是否实现了Aware的相关接口是什么意思?
|
||||
|
||||
|
||||
## Aware相关接口
|
||||
Aware相关的接口包括:BeanNameAware、BeanClassLoaderAware、BeanFactoryAware
|
||||
|
||||
当Bean实现了BeanNameAware,Spring会将Bean的名字传递给Bean。
|
||||
当Bean实现了BeanClassLoaderAware,Spring会将加载该Bean的类加载器传递给Bean。
|
||||
当Bean实现了BeanFactoryAware,Spring会将Bean工厂对象传递给Bean。
|
||||
测试以上10步,可以让User类实现5个接口,并实现所有方法:
|
||||
- BeanNameAware
|
||||
- BeanClassLoaderAware
|
||||
- BeanFactoryAware
|
||||
- InitializingBean
|
||||
- DisposableBean
|
||||
|
||||
## InitializingBean 的核心作用
|
||||
当一个 Bean 实现了 InitializingBean 接口后,Spring 容器会在该 Bean 的所有属性都被成功设置(即完成属性注入)之后,自动调用其 afterPropertiesSet() 方法。这一特性使得开发者可以在 Bean 正式投入使用前,进行一些必要的初始化操作,例如数据校验、资源加载、状态初始化等。
|
||||
|
||||
## DisposableBean核心作用
|
||||
DisposableBean 是 Spring 提供的销毁回调接口,其核心作用是在 Bean 即将被容器销毁前,触发自定义的清理操作。
|
||||
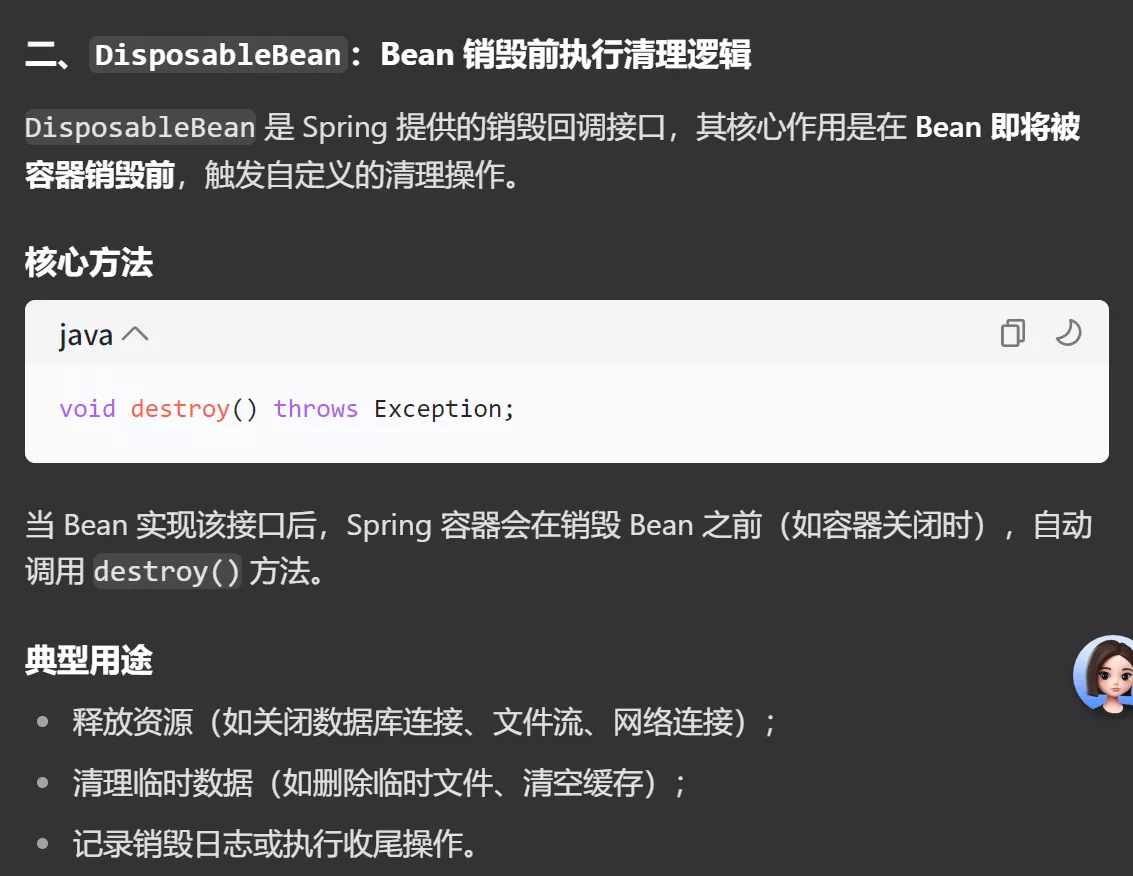
|
||||
|
||||
```java
|
||||
package com.powercode.spring6.beans;
|
||||
|
||||
import org.springframework.beans.BeansException;
|
||||
import org.springframework.beans.factory.*;
|
||||
|
||||
/**
|
||||
* @author 动力节点
|
||||
* @version 1.0
|
||||
* @className User
|
||||
* @since 1.0
|
||||
**/
|
||||
public class User implements BeanNameAware, BeanClassLoaderAware, BeanFactoryAware, InitializingBean, DisposableBean {
|
||||
private String name;
|
||||
|
||||
public User() {
|
||||
System.out.println("1.实例化Bean");
|
||||
}
|
||||
|
||||
public void setName(String name) {
|
||||
this.name = name;
|
||||
System.out.println("2.Bean属性赋值");
|
||||
}
|
||||
|
||||
public void initBean(){
|
||||
System.out.println("6.初始化Bean");
|
||||
}
|
||||
|
||||
public void destroyBean(){
|
||||
System.out.println("10.销毁Bean");
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setBeanClassLoader(ClassLoader classLoader) {
|
||||
System.out.println("3.类加载器:" + classLoader);
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
|
||||
System.out.println("3.Bean工厂:" + beanFactory);
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setBeanName(String name) {
|
||||
System.out.println("3.bean名字:" + name);
|
||||
}
|
||||
|
||||
@Override
|
||||
public void destroy() throws Exception {
|
||||
System.out.println("9.DisposableBean destroy");
|
||||
}
|
||||
|
||||
@Override
|
||||
public void afterPropertiesSet() throws Exception {
|
||||
System.out.println("5.afterPropertiesSet执行");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
26
src/content/posts/Java/Spring/SpringBoot是如何实现自动配置的.md
Normal file
26
src/content/posts/Java/Spring/SpringBoot是如何实现自动配置的.md
Normal file
@@ -0,0 +1,26 @@
|
||||
---
|
||||
title: SpringBoot是如何实现自动配置的
|
||||
published: 2025-09-15
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['SpringBoot','Java','自动配置']
|
||||
category: 'Java > Spring'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# SpringBoot是如何实现自动配置的
|
||||
|
||||
Spring Boot的自动配置是通过 `@EnableAutoConfiguration` 注解来实现的。
|
||||
这个注解包含 `@Import({AutoConfigurationImportSelector.class})`注解
|
||||
导入的这两个类会扫描classpath下所有的`META-INF/spring.factories`中的文件,根据文件中指定的配置类加载相应的Bean的自动配置。
|
||||
|
||||
这些Bean通常会使用 `@ConditionOnClass`,`@ConditionOnMissingBean`,`@ConditionalOnProperty`等注解来控制自动配置的加载条件,例如仅在类路径中存在某个类的时候,才加载某些配置。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
17
src/content/posts/Java/Spring/SpringMVC工作流程.md
Normal file
17
src/content/posts/Java/Spring/SpringMVC工作流程.md
Normal file
@@ -0,0 +1,17 @@
|
||||
---
|
||||
title: SpringMVC工作流程
|
||||
published: 2025-09-22
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [SpringMVC,DispatcherServlet]
|
||||
category: 'Java > Spring'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
141
src/content/posts/Java/Spring/Spring中拦截器和过滤器的区别.md
Normal file
141
src/content/posts/Java/Spring/Spring中拦截器和过滤器的区别.md
Normal file
@@ -0,0 +1,141 @@
|
||||
---
|
||||
title: Spring中拦截器和过滤器的区别
|
||||
published: 2025-09-22
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [SpringMVC,拦截器,过滤器]
|
||||
category: 'Java > Spring'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
https://www.mianshiya.com/question/1907425766060380162#heading-0
|
||||
|
||||
|
||||
# 过滤器
|
||||
## 实现机制
|
||||
过滤器是Servlet规范的一部分,独立于Spring存在,主要用于过滤请求和响应,可以对所有类型的请求进行处理。
|
||||
## 使用范围
|
||||
可以过滤所有的请求,包括静态资源,jsp,html等,因为它在Servlet容器层面生效。
|
||||
## 配置方法
|
||||
需要实现Filter接口,通过标准的Servlet配置方式进行注册:
|
||||
https://www.cnblogs.com/xfeiyun/p/15790555.html
|
||||
|
||||
https://juejin.cn/post/7000950677409103880
|
||||
|
||||
|
||||

|
||||
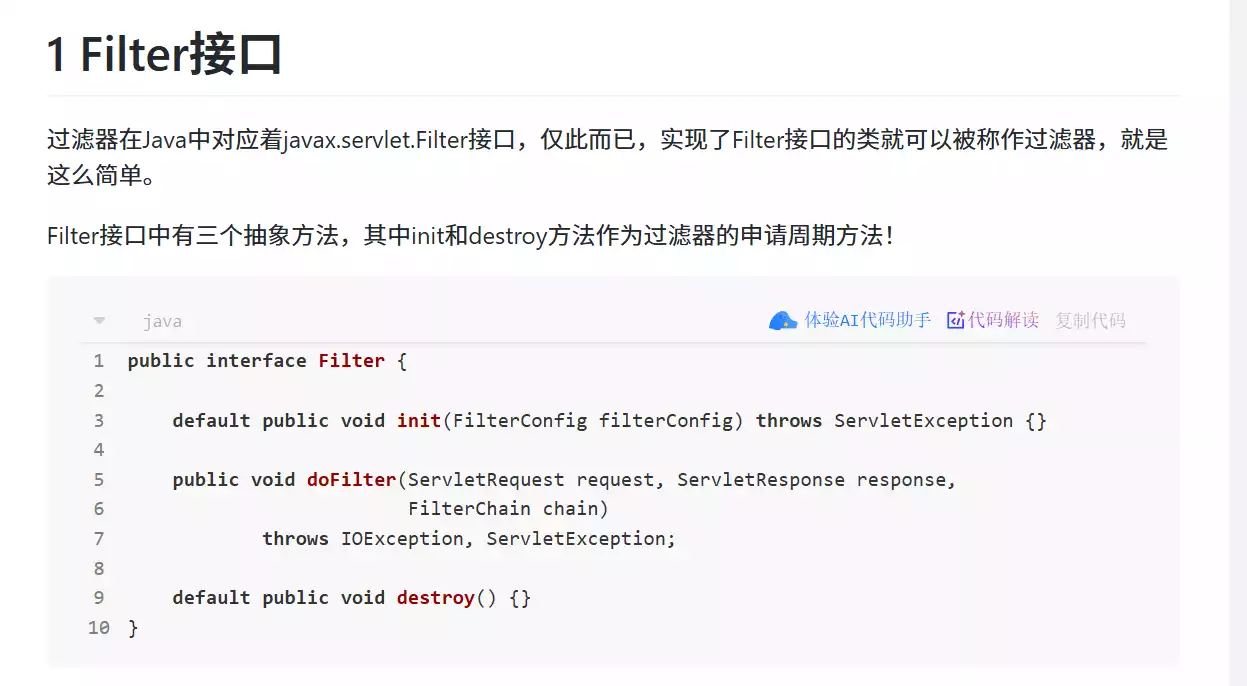
|
||||

|
||||

|
||||
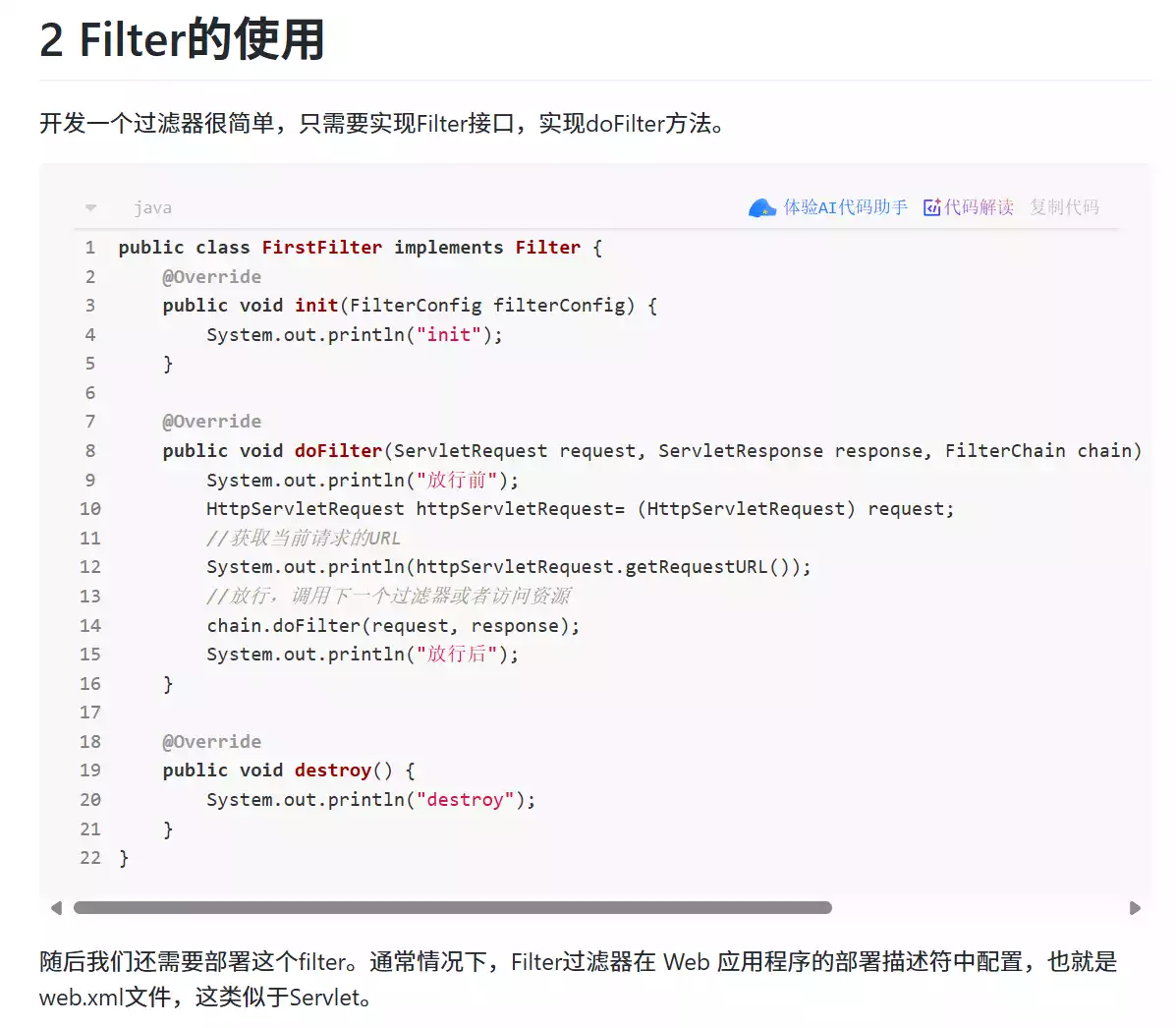
|
||||
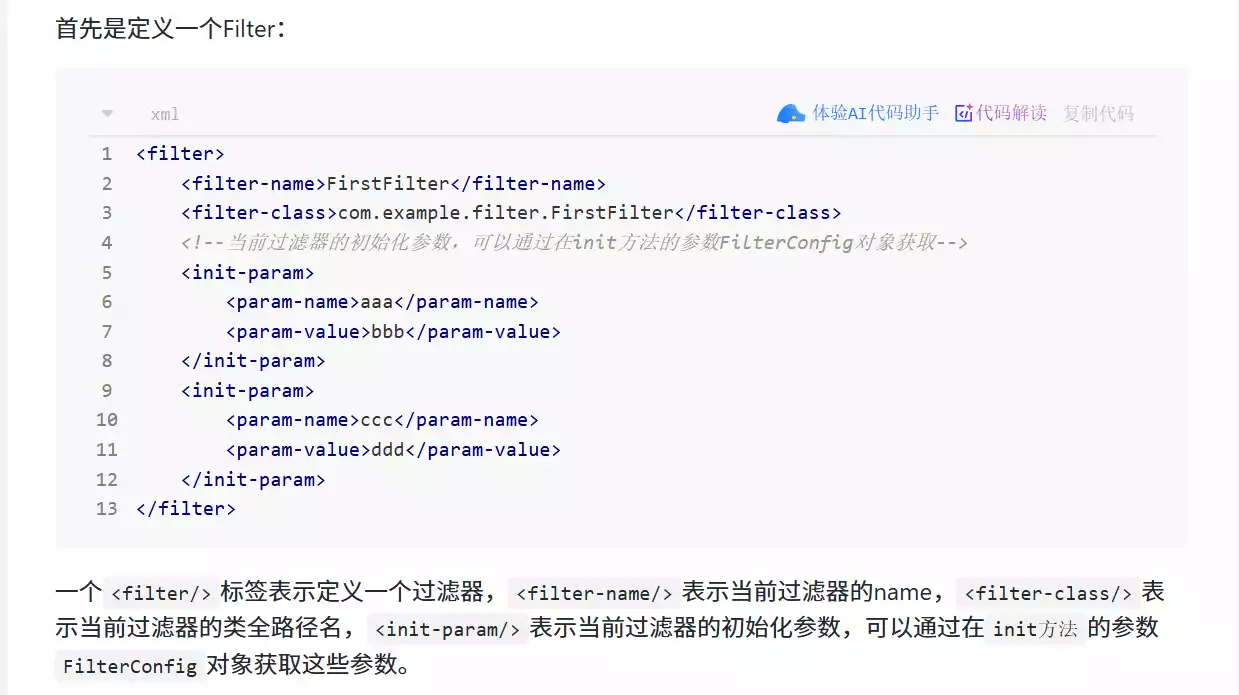
|
||||
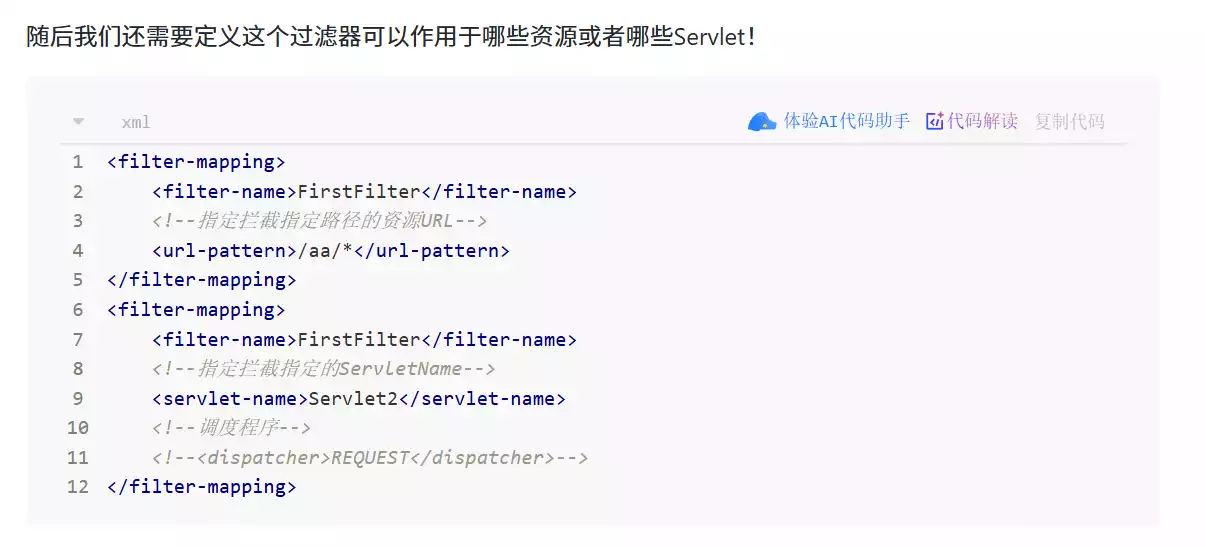
|
||||

|
||||

|
||||
|
||||
## 执行顺序
|
||||
先于拦截器执行,因为过滤器作用于Servlet容器层面,拦截器作用在Spring MVC 的处理器映射器找到控制器前或者后执行。
|
||||
|
||||
## 功能侧重
|
||||
侧重于过滤请求和响应的内容,比如设置编码格式,安全控制等。
|
||||
|
||||
# 拦截器
|
||||
## 实现机制
|
||||
拦截器是Spring框架的一部分,基于Java的反射机制实现,主要针对的是Handler的调用
|
||||
|
||||
## 使用范围
|
||||
主要用于拦截访问DispathcherServlet的请求,通常只适用于Spring MVC的应用程序中的请求处理方法。
|
||||
|
||||
|
||||
## 配置方式
|
||||
需要实现org.springframework.web.servlet.HandlerInterceptor接口,并在Spring配置文件中进行注册。
|
||||
可以通过实现WebMvcConfigurer接口的addInterceptors方法来进行注册。
|
||||

|
||||
```java
|
||||
package com.example.interceptor;
|
||||
|
||||
import jakarta.servlet.http.HttpServletRequest;
|
||||
import jakarta.servlet.http.HttpServletResponse;
|
||||
import org.springframework.web.servlet.HandlerInterceptor;
|
||||
import org.springframework.web.servlet.ModelAndView;
|
||||
|
||||
/**
|
||||
* @author wipe
|
||||
* @version 1.0
|
||||
*/
|
||||
|
||||
public class MyInterceptor1 implements HandlerInterceptor {
|
||||
|
||||
@Override//目标资源方法执行前执行。 返回true:放行 返回false:不放行
|
||||
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
|
||||
|
||||
System.out.println("MyInterceptor1 ... preHandle");
|
||||
return true;
|
||||
}
|
||||
|
||||
@Override//目标资源方法执行后执行
|
||||
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
|
||||
System.out.println("MyInterceptor1 ... postHandle");
|
||||
}
|
||||
|
||||
@Override//视图渲染完毕后执行,最后执行
|
||||
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
|
||||
System.out.println("MyInterceptor1 ... afterCompletion");
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
```java
|
||||
package com.example.config;
|
||||
|
||||
import com.example.filter.MyFilter1;
|
||||
import com.example.filter.MyFilter2;
|
||||
import com.example.interceptor.MyInterceptor1;
|
||||
import com.example.interceptor.MyInterceptor2;
|
||||
import org.springframework.boot.web.servlet.FilterRegistrationBean;
|
||||
import org.springframework.context.annotation.Bean;
|
||||
import org.springframework.context.annotation.Configuration;
|
||||
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
|
||||
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
|
||||
/**
|
||||
* @author wipe
|
||||
* @version 1.0
|
||||
*/
|
||||
@Configuration
|
||||
public class MyConfig implements WebMvcConfigurer {
|
||||
|
||||
|
||||
@Override
|
||||
public void addInterceptors(InterceptorRegistry registry) {
|
||||
// 添加拦截器,并指定执行顺序,也可以通过将拦截器声明成 bean 对象,然后通过 @Order 注解或者实现 Order 接口指定执行顺序
|
||||
registry.addInterceptor(new MyInterceptor1()).order(1);
|
||||
registry.addInterceptor(new MyInterceptor2()).order(2);
|
||||
}
|
||||
|
||||
|
||||
@Bean// 这样配置可以指定过滤器的执行顺序
|
||||
public FilterRegistrationBean<MyFilter1> myFilter1() {
|
||||
FilterRegistrationBean<MyFilter1> filter = new FilterRegistrationBean<>();
|
||||
filter.setFilter(new MyFilter1());
|
||||
filter.addUrlPatterns("/*");
|
||||
filter.setOrder(1);
|
||||
return filter;
|
||||
}
|
||||
|
||||
@Bean
|
||||
public FilterRegistrationBean<MyFilter2> myFilter2() {
|
||||
FilterRegistrationBean<MyFilter2> filter = new FilterRegistrationBean<>();
|
||||
filter.setFilter(new MyFilter2());
|
||||
filter.addUrlPatterns("/*");
|
||||
filter.setOrder(2);
|
||||
return filter;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
也可以直接用@Component注册Interceptor
|
||||
## 执行顺序
|
||||
可以指定多个拦截器之间的执行顺序,通过实现Ordered接口或者使用@Order注解来控制。
|
||||
|
||||
## 功能侧重
|
||||
侧重于业务逻辑的前置检查,权限验证,日志记录等。
|
||||
265
src/content/posts/Java/Spring/Spring中的BeanFactory与FactoryBean.md
Normal file
265
src/content/posts/Java/Spring/Spring中的BeanFactory与FactoryBean.md
Normal file
@@ -0,0 +1,265 @@
|
||||
---
|
||||
title: Spring中的BeanFactory与FactoryBean
|
||||
published: 2025-08-08
|
||||
description: 深入理解Spring容器的核心接口BeanFactory与特殊工厂Bean——FactoryBean的区别、使用场景与最佳实践
|
||||
image: ''
|
||||
tags: [Java, Spring, IoC, DI, BeanFactory, FactoryBean]
|
||||
category: 'Java > Spring'
|
||||
draft: false
|
||||
lang: zh-CN
|
||||
---
|
||||
|
||||
# BeanFactory
|
||||
BeanFactory是一个工厂接口,是一个负责生产和管理bean的一个工厂。BeanFactory是工厂的顶层接口,是IOC容器的核心接口,BeanFactory定义了管理Bean的通用方法,如getBean和containsBean等,它的职责包括:
|
||||
- Bean实例化: 根据XML注解等创建Bean对象。
|
||||
- 依赖注入: 自动将Bean所需的依赖注入进去。
|
||||
- 生命周期管理: 管理Bean的初始化,销毁等生命周期方法。
|
||||
- 延迟加载: 默认采用懒加载策略,只有在调用getBean()时才创建Bean实例。
|
||||
- Bean获取: 提供getBean()方法来获取Bean实例。
|
||||
|
||||

|
||||
|
||||
BeanFactory只是一个接口,不是IOC容器的具体实现,所以Spring容器给出了很多种实现,如XmlBeanFactory、AnnotationConfigApplicationContext,ApplicationContext等。
|
||||
|
||||
## BeanFactory 的常见实现类
|
||||
|
||||
Spring 提供了多种 BeanFactory 的实现,每种实现都有其特定的使用场景:
|
||||
|
||||
### DefaultListableBeanFactory
|
||||
最常用的完整实现,支持完整的Bean生命周期管理:
|
||||
|
||||
```java
|
||||
import org.springframework.beans.factory.support.DefaultListableBeanFactory;
|
||||
import org.springframework.beans.factory.support.RootBeanDefinition;
|
||||
|
||||
public class BeanFactoryExample {
|
||||
public static void main(String[] args) {
|
||||
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
|
||||
|
||||
// 手动注册Bean定义
|
||||
RootBeanDefinition beanDefinition = new RootBeanDefinition(MyService.class);
|
||||
factory.registerBeanDefinition("myService", beanDefinition);
|
||||
|
||||
// 获取Bean
|
||||
MyService service = factory.getBean("myService", MyService.class);
|
||||
service.doSomething();
|
||||
}
|
||||
}
|
||||
|
||||
class MyService {
|
||||
public void doSomething() {
|
||||
System.out.println("Service is working!");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### XmlBeanFactory(已废弃)
|
||||
基于XML配置的BeanFactory实现,Spring 5.x后已废弃,推荐使用ApplicationContext:
|
||||
|
||||
```java
|
||||
// 传统用法(不推荐)
|
||||
// XmlBeanFactory factory = new XmlBeanFactory(new ClassPathResource("beans.xml"));
|
||||
|
||||
// 现代替代方案
|
||||
import org.springframework.context.support.ClassPathXmlApplicationContext;
|
||||
|
||||
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("beans.xml");
|
||||
MyService service = context.getBean("myService", MyService.class);
|
||||
```
|
||||
|
||||
### StaticListableBeanFactory
|
||||
静态Bean工厂,适用于Bean集合固定的场景:
|
||||
|
||||
```java
|
||||
import org.springframework.beans.factory.support.StaticListableBeanFactory;
|
||||
|
||||
StaticListableBeanFactory factory = new StaticListableBeanFactory();
|
||||
factory.addBean("myService", new MyService());
|
||||
factory.addBean("anotherService", new AnotherService());
|
||||
|
||||
MyService service = factory.getBean("myService", MyService.class);
|
||||
```
|
||||
|
||||
### ApplicationContext实现类
|
||||
作为BeanFactory的高级实现,提供更多企业级特性:
|
||||
|
||||
```java
|
||||
// 注解配置
|
||||
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
|
||||
|
||||
AnnotationConfigApplicationContext context =
|
||||
new AnnotationConfigApplicationContext(AppConfig.class);
|
||||
|
||||
// XML配置
|
||||
import org.springframework.context.support.ClassPathXmlApplicationContext;
|
||||
|
||||
ClassPathXmlApplicationContext xmlContext =
|
||||
new ClassPathXmlApplicationContext("applicationContext.xml");
|
||||
|
||||
// Web环境
|
||||
import org.springframework.web.context.support.AnnotationConfigWebApplicationContext;
|
||||
|
||||
AnnotationConfigWebApplicationContext webContext =
|
||||
new AnnotationConfigWebApplicationContext();
|
||||
webContext.register(WebConfig.class);
|
||||
```
|
||||
|
||||
### 实际应用示例
|
||||
结合Bean定义构建器的完整示例:
|
||||
|
||||
```java
|
||||
import org.springframework.beans.factory.support.BeanDefinitionBuilder;
|
||||
import org.springframework.beans.factory.support.DefaultListableBeanFactory;
|
||||
|
||||
public class CustomBeanFactoryDemo {
|
||||
public static void main(String[] args) {
|
||||
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
|
||||
|
||||
// 使用BeanDefinitionBuilder构建复杂Bean
|
||||
BeanDefinitionBuilder builder = BeanDefinitionBuilder
|
||||
.rootBeanDefinition(DatabaseService.class)
|
||||
.addPropertyValue("url", "jdbc:mysql://localhost:3306/mydb")
|
||||
.addPropertyValue("username", "root")
|
||||
.setScope("singleton")
|
||||
.setLazyInit(true);
|
||||
|
||||
factory.registerBeanDefinition("dbService", builder.getBeanDefinition());
|
||||
|
||||
// 懒加载验证
|
||||
System.out.println("Bean定义已注册,但未实例化");
|
||||
|
||||
DatabaseService dbService = factory.getBean("dbService", DatabaseService.class);
|
||||
System.out.println("现在Bean被实例化了");
|
||||
}
|
||||
}
|
||||
|
||||
class DatabaseService {
|
||||
private String url;
|
||||
private String username;
|
||||
|
||||
// getters and setters
|
||||
public void setUrl(String url) { this.url = url; }
|
||||
public void setUsername(String username) { this.username = username; }
|
||||
|
||||
public void connect() {
|
||||
System.out.println("连接到: " + url + " 用户: " + username);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## BeanFactory 与 ApplicationContext 的区别
|
||||
- 预实例化策略
|
||||
- BeanFactory:单例默认懒加载。
|
||||
- ApplicationContext:默认预实例化单例(提高启动后首次访问的吞吐)。
|
||||
- 扩展能力
|
||||
- ApplicationContext 额外提供国际化、事件发布、AOP自动代理、资源模式解析等企业特性。
|
||||
- 适用场景
|
||||
- BeanFactory:资源受限、极致冷启动、强控制懒加载/条件加载。
|
||||
- ApplicationContext:大多数应用优先选择。
|
||||
- 调优提示
|
||||
- 需要懒加载时,可结合ApplicationContext + @Lazy 或者使用ObjectProvider/Provider按需获取。
|
||||
|
||||
# FactoryBean
|
||||
在Spring中,所有的Bean都是由BeanFactory管理的(IOC容器),
|
||||
这个FactoryBean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,它的实现与设计模式中的工厂模式和修饰器模式类似。
|
||||
|
||||
|
||||
## FactoryBean 的作用
|
||||
|
||||

|
||||
|
||||
- 将“复杂对象的创建逻辑”封装到工厂Bean中,对外暴露的是“产品对象”而不是工厂本身。
|
||||
- 常用于:动态代理(AOP/远程代理)、框架桥接(如MyBatis的SqlSessionFactoryBean)、复杂构建(连接池、客户端SDK)。
|
||||
|
||||
## 核心接口方法
|
||||
- getObject(): 返回实际产品对象(对外暴露的Bean)。
|
||||
- getObjectType(): 返回产品类型,便于类型匹配与自动装配。
|
||||
- isSingleton(): 决定产品是否为单例(影响缓存与生命周期)。
|
||||
|
||||
## 获取“产品”还是“工厂本身”
|
||||
- 普通名:context.getBean("beanName") 获取的是产品对象(getObject返回值)。
|
||||
- 带&前缀:context.getBean("&beanName") 获取的是FactoryBean自身。
|
||||
- 命名规则:注册名为 x 的 FactoryBean,会对外暴露“产品”名为 x,“工厂自身”为 &x。
|
||||
|
||||
## 最小可运行示例
|
||||
```java
|
||||
// 一个业务产品
|
||||
public class ApiClient {
|
||||
private final String endpoint;
|
||||
public ApiClient(String endpoint) { this.endpoint = endpoint; }
|
||||
public String call(String path) { return "GET " + endpoint + path; }
|
||||
}
|
||||
|
||||
// FactoryBean 实现
|
||||
import org.springframework.beans.factory.FactoryBean;
|
||||
import org.springframework.beans.factory.InitializingBean;
|
||||
import org.springframework.util.Assert;
|
||||
|
||||
public class ApiClientFactoryBean implements FactoryBean<ApiClient>, InitializingBean {
|
||||
private String endpoint;
|
||||
public void setEndpoint(String endpoint) { this.endpoint = endpoint; }
|
||||
|
||||
@Override
|
||||
public ApiClient getObject() {
|
||||
// 可在此放入复杂构建/代理/缓存等逻辑
|
||||
return new ApiClient(endpoint);
|
||||
}
|
||||
|
||||
@Override
|
||||
public Class<?> getObjectType() { return ApiClient.class; }
|
||||
|
||||
@Override
|
||||
public boolean isSingleton() { return true; }
|
||||
|
||||
@Override
|
||||
public void afterPropertiesSet() {
|
||||
Assert.hasText(endpoint, "endpoint must not be empty");
|
||||
}
|
||||
}
|
||||
|
||||
// Java 配置注册 FactoryBean
|
||||
import org.springframework.context.annotation.Bean;
|
||||
import org.springframework.context.annotation.Configuration;
|
||||
|
||||
@Configuration
|
||||
public class AppConfig {
|
||||
@Bean(name = "apiClient")
|
||||
public ApiClientFactoryBean apiClientFactoryBean() {
|
||||
ApiClientFactoryBean fb = new ApiClientFactoryBean();
|
||||
fb.setEndpoint("https://api.example.com");
|
||||
return fb;
|
||||
}
|
||||
}
|
||||
|
||||
// 取产品与取工厂本身
|
||||
import org.springframework.context.ApplicationContext;
|
||||
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
|
||||
|
||||
public class Demo {
|
||||
public static void main(String[] args) {
|
||||
ApplicationContext ctx = new AnnotationConfigApplicationContext(AppConfig.class);
|
||||
ApiClient client = ctx.getBean("apiClient", ApiClient.class); // 产品
|
||||
ApiClientFactoryBean fb = ctx.getBean("&apiClient", ApiClientFactoryBean.class); // 工厂本身
|
||||
System.out.println(client.call("/ping"));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 常见坑与最佳实践
|
||||
- getObjectType 切勿返回 null:尽量返回接口/具体类型,便于按类型注入与AOT分析。
|
||||
- isSingleton 与产品生命周期:单例将被容器缓存;非单例每次getBean都会重新创建产品。
|
||||
- 懒加载与预实例化:在ApplicationContext中,如希望延迟创建可使用@Lazy或将FactoryBean产品设为非单例。
|
||||
- 自动装配歧义:按类型注入时,注入到的是产品类型而非FactoryBean;需要注入工厂本身时使用@Qualifier("&name")或@Resource(name="&name")。
|
||||
- 原型产品与循环依赖:原型产品不参与循环依赖的三级缓存提前暴露,避免在原型链路中引入循环依赖。
|
||||
- 命名规范:确保文档/注释标明“&”语义,避免团队误用。
|
||||
|
||||
## 什么时候用哪一个?
|
||||
- 仅需容器功能:优先ApplicationContext(功能更全,默认预实例化)。
|
||||
- 需要懒加载到极致:考虑BeanFactory或在ApplicationContext中对关键Bean标注@Lazy。
|
||||
- 对象构建复杂/需代理/外部SDK桥接:使用FactoryBean封装构建细节,对外仅暴露产品。
|
||||
|
||||
## 小结
|
||||
- BeanFactory 是IoC容器的最小抽象;ApplicationContext在其上增强了企业级特性。
|
||||
- FactoryBean 是“创建Bean的Bean”,对外暴露产品;使用“&name”获取工厂本身。
|
||||
- 合理利用FactoryBean可显著简化复杂对象创建,并保持应用装配的清晰与解耦。
|
||||
172
src/content/posts/Java/Spring/Spring常见面试题.md
Normal file
172
src/content/posts/Java/Spring/Spring常见面试题.md
Normal file
@@ -0,0 +1,172 @@
|
||||
---
|
||||
title: Spring常见面试题
|
||||
published: 2025-07-28
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ["Spring","Java"]
|
||||
category: 'Java > Spring'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# @Autowired 和 @Resource 的区别是什么?
|
||||
|
||||
@Autowired属于Spring内置的注解,默认的注入方式是byType,也就是根据类型匹配,当有多个实现时
|
||||
byType就没办法正确注入了,这个时候可以结合@Qualifier注解一起使用,指定注入的名称。当然也可以使用byName,也就是根据名称注入,但是需要结合@Qualifier注解一起使用。
|
||||
|
||||
@Resource 是Java自带注解,属于J2EE的,默认注入方式是byName,也就是根据名称注入,当找不到与名称匹配的bean时,根据类型注入。当然也可以结合@Qualifier注解一起使用,指定注入的名称。
|
||||
|
||||
@Resource 有两个比较重要且日常开发常用的属性:name(名称)、type(类型)。
|
||||
如果仅指定 name 属性则注入方式为byName,如果仅指定type属性则注入方式为byType,如果同时指定name 和type属性(不建议这么做)则注入方式为byType+byName。
|
||||
|
||||
@Autowired 支持在构造函数、方法、字段和参数上使用。
|
||||
@Resource 主要用于字段和方法上的注入,不支持在构造函数或参数上使用。
|
||||
|
||||
|
||||
# Bean 的生命周期
|
||||
|
||||

|
||||
|
||||
Bean生命周期可以粗略的划分为五大步:
|
||||
|
||||
第一步:实例化Bean
|
||||
第二步:Bean属性赋值
|
||||
第三步:初始化Bean
|
||||
第四步:使用Bean
|
||||
第五步:销毁Bean
|
||||

|
||||
|
||||
```java
|
||||
package com.powercode.spring6.beans;
|
||||
|
||||
public class User {
|
||||
private String name;
|
||||
public User() {
|
||||
System.out.println("1.实例化Bean");
|
||||
}
|
||||
|
||||
public void setName(String name) {
|
||||
this.name = name;
|
||||
System.out.println("2.Bean属性赋值");
|
||||
}
|
||||
|
||||
public void initBean(){
|
||||
System.out.println("3.初始化Bean");
|
||||
}
|
||||
|
||||
public void destroyBean(){
|
||||
System.out.println("5.销毁Bean");
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
2024-01-11 12:21:23 618 [main] DEBUG org.springframework.context.support.ClassPathXmlApplicationContext - Refreshing org.springframework.context.support.ClassPathXmlApplicationContext@183e8023
|
||||
2024-01-11 12:21:23 715 [main] DEBUG org.springframework.beans.factory.xml.XmlBeanDefinitionReader - Loaded 1 bean definitions from class path resource [spring12.xml]
|
||||
2024-01-11 12:21:23 732 [main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'userBean'
|
||||
1.实例化Bean
|
||||
2.Bean属性赋值
|
||||
3.初始化Bean
|
||||
4.使用Bean
|
||||
2024-01-11 12:21:23 774 [main] DEBUG org.springframework.context.support.ClassPathXmlApplicationContext - Closing org.springframework.context.support.ClassPathXmlApplicationContext@183e8023, started on Thu Jan 11 12:21:23 CST 2024
|
||||
5.销毁Bean
|
||||
2024-01-11 12:21:23 774 [main] DEBUG org.springframework.beans.factory.support.DisposableBeanAdapter - Custom destroy method 'destroyBean' on bean with name 'userBean' completed
|
||||
|
||||
进程已结束,退出代码为 0
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
## Bean后处理器
|
||||
加上后处理器就变成七步了:
|
||||

|
||||
|
||||
|
||||
### BeanPostProcessor 的核心作用
|
||||
BeanPostProcessor 本身并不属于某个特定 Bean 的生命周期,而是作用于容器中所有 Bean 的 “全局处理器”。它的核心功能是:在 Bean 完成实例化和属性赋值后、初始化方法(如 afterPropertiesSet() 或 init-method)执行前后,对 Bean 进行加工或增强。
|
||||
|
||||
上图中检查Bean是否实现了Aware的相关接口是什么意思?
|
||||
|
||||
|
||||
## Aware相关接口
|
||||
Aware相关的接口包括:BeanNameAware、BeanClassLoaderAware、BeanFactoryAware
|
||||
|
||||
当Bean实现了BeanNameAware,Spring会将Bean的名字传递给Bean。
|
||||
当Bean实现了BeanClassLoaderAware,Spring会将加载该Bean的类加载器传递给Bean。
|
||||
当Bean实现了BeanFactoryAware,Spring会将Bean工厂对象传递给Bean。
|
||||
测试以上10步,可以让User类实现5个接口,并实现所有方法:
|
||||
- BeanNameAware
|
||||
- BeanClassLoaderAware
|
||||
- BeanFactoryAware
|
||||
- InitializingBean
|
||||
- DisposableBean
|
||||
|
||||
## InitializingBean 的核心作用
|
||||
当一个 Bean 实现了 InitializingBean 接口后,Spring 容器会在该 Bean 的所有属性都被成功设置(即完成属性注入)之后,自动调用其 afterPropertiesSet() 方法。这一特性使得开发者可以在 Bean 正式投入使用前,进行一些必要的初始化操作,例如数据校验、资源加载、状态初始化等。
|
||||
|
||||
## DisposableBean核心作用
|
||||
DisposableBean 是 Spring 提供的销毁回调接口,其核心作用是在 Bean 即将被容器销毁前,触发自定义的清理操作。
|
||||

|
||||
|
||||
```java
|
||||
package com.powercode.spring6.beans;
|
||||
|
||||
import org.springframework.beans.BeansException;
|
||||
import org.springframework.beans.factory.*;
|
||||
|
||||
/**
|
||||
* @author 动力节点
|
||||
* @version 1.0
|
||||
* @className User
|
||||
* @since 1.0
|
||||
**/
|
||||
public class User implements BeanNameAware, BeanClassLoaderAware, BeanFactoryAware, InitializingBean, DisposableBean {
|
||||
private String name;
|
||||
|
||||
public User() {
|
||||
System.out.println("1.实例化Bean");
|
||||
}
|
||||
|
||||
public void setName(String name) {
|
||||
this.name = name;
|
||||
System.out.println("2.Bean属性赋值");
|
||||
}
|
||||
|
||||
public void initBean(){
|
||||
System.out.println("6.初始化Bean");
|
||||
}
|
||||
|
||||
public void destroyBean(){
|
||||
System.out.println("10.销毁Bean");
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setBeanClassLoader(ClassLoader classLoader) {
|
||||
System.out.println("3.类加载器:" + classLoader);
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
|
||||
System.out.println("3.Bean工厂:" + beanFactory);
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setBeanName(String name) {
|
||||
System.out.println("3.bean名字:" + name);
|
||||
}
|
||||
|
||||
@Override
|
||||
public void destroy() throws Exception {
|
||||
System.out.println("9.DisposableBean destroy");
|
||||
}
|
||||
|
||||
@Override
|
||||
public void afterPropertiesSet() throws Exception {
|
||||
System.out.println("5.afterPropertiesSet执行");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
291
src/content/posts/Java/Spring/Spring配置相关的注解.md
Normal file
291
src/content/posts/Java/Spring/Spring配置相关的注解.md
Normal file
@@ -0,0 +1,291 @@
|
||||
---
|
||||
title: Spring配置相关的注解
|
||||
published: 2025-08-08
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ["Spring","Java"]
|
||||
category: 'Java > Spring'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
当然!这是一个非常重要且实用的主题。在 Spring 和 Spring Boot 中,与属性(Property)相关的注解是实现“配置与代码分离”这一核心原则的关键。
|
||||
|
||||
我将为你全面、系统地讲解这些注解,从最基础到最常用,再到高级用法,并配上清晰的示例。
|
||||
|
||||
我们将主要围绕以下几个核心注解展开:
|
||||
|
||||
1. **`@Value`**: 最基础的,用于注入单个属性值。
|
||||
2. **`@PropertySource`**: 用于加载指定的属性文件。
|
||||
3. **`@ConfigurationProperties`**: 最强大、最推荐的,用于类型安全地将一组属性绑定到Java对象上。
|
||||
4. **`@EnableConfigurationProperties`**: 与 `@ConfigurationProperties` 配合使用,用于激活属性绑定。
|
||||
5. **`@TestPropertySource`**: 在测试环境中加载或覆盖属性。
|
||||
|
||||
---
|
||||
|
||||
### 注解族谱概览
|
||||
|
||||
为了方便理解,我们可以把它们分为三类:
|
||||
|
||||
* **值注入 (Value Injection)**: `@Value`
|
||||
* **配置源 (Configuration Source)**: `@PropertySource`, `@TestPropertySource`
|
||||
* **批量绑定 (Bulk Binding)**: `@ConfigurationProperties`, `@EnableConfigurationProperties`
|
||||
|
||||
---
|
||||
|
||||
### 1. `@Value`:简单直接的“单兵作战”
|
||||
|
||||
这是注入属性最基本的方式。
|
||||
|
||||
* **作用**: 将 Spring 环境(Environment)中的单个属性值注入到类的字段或方法参数中。
|
||||
* **语法**: 使用 SpEL (Spring Expression Language) 表达式 `"${property.key}"`。
|
||||
* **优点**: 简单、直接,适合注入少量、分散的配置。
|
||||
* **缺点**:
|
||||
* 当属性很多时,代码会显得分散和混乱。
|
||||
* 类型安全性较弱(都是字符串,需要Spring转换)。
|
||||
* 重构时(如修改前缀)非常痛苦。
|
||||
|
||||
**示例:**
|
||||
|
||||
**`src/main/resources/application.properties`**
|
||||
```properties
|
||||
app.name=My Awesome App
|
||||
app.version=2.1.5
|
||||
app.author.name=Alex
|
||||
# 如果某个属性可能不存在,可以提供默认值
|
||||
# mail.default.sender=default@example.com
|
||||
```
|
||||
|
||||
**Java 类**
|
||||
```java
|
||||
import org.springframework.beans.factory.annotation.Value;
|
||||
import org.springframework.stereotype.Component;
|
||||
|
||||
@Component
|
||||
public class AppInfoService {
|
||||
|
||||
// 注入 app.name 属性
|
||||
@Value("${app.name}")
|
||||
private String appName;
|
||||
|
||||
// 注入 app.version 属性
|
||||
@Value("${app.version}")
|
||||
private String appVersion;
|
||||
|
||||
// 注入一个不存在的属性,但提供了默认值 "unknown"
|
||||
@Value("${app.description:unknown description}")
|
||||
private String appDescription;
|
||||
|
||||
// 也可以注入其他 Bean 的属性(使用 SpEL)
|
||||
@Value("#{someOtherBean.someProperty}")
|
||||
private String otherProperty;
|
||||
|
||||
public void printAppInfo() {
|
||||
System.out.println("App Name: " + appName);
|
||||
System.out.println("App Version: " + appVersion);
|
||||
System.out.println("App Description: " + appDescription);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 2. `@PropertySource`:指定“情报来源”
|
||||
|
||||
默认情况下,Spring Boot 会自动加载 `application.properties` 或 `application.yml`。如果你想加载其他配置文件,就需要用到 `@PropertySource`。
|
||||
|
||||
* **作用**: 将指定的属性文件加载到 Spring 的 `Environment` 中。
|
||||
* **使用场景**:
|
||||
* 模块化配置,将不同功能的配置放在不同文件里(如 `mail.properties`, `db.properties`)。
|
||||
* 加载 classpath 之外的文件系统中的配置。
|
||||
* **注意**: 它只负责**加载**,不负责注入。加载后,你可以用 `@Value` 或 `@ConfigurationProperties` 来使用这些属性。
|
||||
|
||||
**示例:**
|
||||
|
||||
**`src/main/resources/mail.properties`**
|
||||
```properties
|
||||
mail.host=smtp.gmail.com
|
||||
mail.port=587
|
||||
```
|
||||
|
||||
**Java 配置类**
|
||||
```java
|
||||
import org.springframework.context.annotation.Configuration;
|
||||
import org.springframework.context.annotation.PropertySource;
|
||||
import org.springframework.beans.factory.annotation.Value;
|
||||
|
||||
@Configuration
|
||||
// 加载 classpath 下的 mail.properties 文件
|
||||
@PropertySource("classpath:mail.properties")
|
||||
public class MailConfig {
|
||||
|
||||
@Value("${mail.host}")
|
||||
private String host;
|
||||
|
||||
@Value("${mail.port}")
|
||||
private int port;
|
||||
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 3. `@ConfigurationProperties`
|
||||
|
||||
这是 Spring Boot **最推荐**的属性管理方式。它将一组相关的属性映射到一个类型安全的 Java 对象(POJO)上。
|
||||
|
||||
* **作用**: 将具有相同前缀的属性批量绑定到一个 POJO 的字段上。
|
||||
* **优点**:
|
||||
* **类型安全**: 直接映射到 `int`, `List`, `Duration` 等各种类型。
|
||||
* **结构清晰**: 将相关配置聚合在一个类中,非常易于管理和维护。
|
||||
* **强大的绑定**: 支持复杂的对象图,比如嵌套对象、列表、Map等。
|
||||
* **IDE 友好**: 主流 IDE(如 IntelliJ IDEA)支持对 `application.properties` 中这类属性的自动补全和导航(需要添加 `spring-boot-configuration-processor` 依赖)。
|
||||
|
||||
**示例:**
|
||||
|
||||
**`application.properties`**
|
||||
```properties
|
||||
app.server.name=prod-server
|
||||
app.server.ip-address=192.168.1.100
|
||||
app.server.timeout=30s # Spring Boot 2.x 支持时间单位
|
||||
app.server.admins[0].name=admin1
|
||||
app.server.admins[0].email=admin1@corp.com
|
||||
app.server.admins[1].name=admin2
|
||||
app.server.admins[1].email=admin2@corp.com
|
||||
```
|
||||
|
||||
**Java 属性类 (POJO)**
|
||||
|
||||
```java
|
||||
import org.springframework.boot.context.properties.ConfigurationProperties;
|
||||
import java.time.Duration;
|
||||
import java.util.List;
|
||||
|
||||
// 告诉 Spring 这个类要绑定前缀为 "app.server" 的属性
|
||||
@ConfigurationProperties(prefix = "app.server")
|
||||
public class ServerProperties {
|
||||
|
||||
private String name;
|
||||
private String ipAddress;
|
||||
private Duration timeout; // 自动将 "30s" 转换为 Duration 对象
|
||||
private List<Admin> admins;
|
||||
|
||||
// 嵌套类
|
||||
public static class Admin {
|
||||
private String name;
|
||||
private String email;
|
||||
// Getters and Setters for Admin
|
||||
}
|
||||
|
||||
// ⭐ 重要: 必须为所有字段提供 public Getters and Setters
|
||||
// Spring 通过它们来注入值
|
||||
// ... Getters and Setters for ServerProperties ...
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 4. `@EnableConfigurationProperties`
|
||||
|
||||
`@ConfigurationProperties` 只是一个声明,它本身不会让这个 POJO 成为一个 Spring Bean。你需要一种方式来“激活”它。`@EnableConfigurationProperties` 就是这个开关。
|
||||
|
||||
* **作用**:
|
||||
1. 告诉 Spring 去处理被 `@ConfigurationProperties` 注解的类。
|
||||
2. 将被注解的类(如 `ServerProperties`)注册到 Spring 容器中,让它成为一个 Bean。这样你就可以在其他地方 `@Autowired` 注入它了。
|
||||
* **通常放在哪**: 主启动类或任何 `@Configuration` 类上。
|
||||
|
||||
**示例:**
|
||||
|
||||
```java
|
||||
import org.springframework.boot.SpringApplication;
|
||||
import org.springframework.boot.autoconfigure.SpringBootApplication;
|
||||
import org.springframework.boot.context.properties.EnableConfigurationProperties;
|
||||
|
||||
@SpringBootApplication
|
||||
// 激活对 ServerProperties 类的绑定,并将其注册为 Bean
|
||||
@EnableConfigurationProperties(ServerProperties.class)
|
||||
public class MyApplication {
|
||||
|
||||
public static void main(String[] args) {
|
||||
SpringApplication.run(MyApplication.class, args);
|
||||
}
|
||||
}
|
||||
|
||||
// 现在可以在任何其他组件中注入它
|
||||
@Service
|
||||
public class MyService {
|
||||
private final ServerProperties serverProps;
|
||||
|
||||
@Autowired
|
||||
public MyService(ServerProperties serverProps) {
|
||||
this.serverProps = serverProps;
|
||||
System.out.println("Server Name: " + serverProps.getName());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> **快捷方式**: 如果你在 `ServerProperties` 类上同时加上 `@Component` 和 `@ConfigurationProperties`,就可以省略 `@EnableConfigurationProperties`。但显式使用 `@EnableConfigurationProperties` 通常被认为是更清晰的做法,因为它明确表达了这是一个配置类。
|
||||
|
||||
---
|
||||
|
||||
### 5. `@TestPropertySource`:为测试“定制情报”
|
||||
|
||||
在进行单元测试或集成测试时,我们经常需要使用一套不同于生产环境的配置(比如连接到内存数据库 H2)。
|
||||
|
||||
* **作用**: 在测试上下文中加载属性,它可以覆盖`application.properties`中的属性或添加新属性。
|
||||
* **常用属性**:
|
||||
* `locations`: 指定要加载的属性文件路径。
|
||||
* `properties`: 以 `key=value` 形式直接定义内联属性。
|
||||
|
||||
**示例:**
|
||||
|
||||
```java
|
||||
import org.springframework.beans.factory.annotation.Autowired;
|
||||
import org.springframework.boot.test.context.SpringBootTest;
|
||||
import org.springframework.core.env.Environment;
|
||||
import org.springframework.test.context.TestPropertySource;
|
||||
import org.junit.jupiter.api.Test;
|
||||
import static org.assertj.core.api.Assertions.assertThat;
|
||||
|
||||
@SpringBootTest
|
||||
// 1. 加载 test.properties 文件
|
||||
// 2. 直接定义一个内联属性,它会覆盖 test.properties 或 application.properties 中的同名属性
|
||||
@TestPropertySource(
|
||||
locations = "classpath:test.properties",
|
||||
properties = "app.version=test-1.0"
|
||||
)
|
||||
public class AppInfoServiceTest {
|
||||
|
||||
@Autowired
|
||||
private Environment env;
|
||||
|
||||
@Test
|
||||
void testPropertiesAreLoaded() {
|
||||
// 来自 test.properties
|
||||
assertThat(env.getProperty("app.name")).isEqualTo("Test App");
|
||||
|
||||
// 被内联属性覆盖
|
||||
assertThat(env.getProperty("app.version")).isEqualTo("test-1.0");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 总结与最佳实践
|
||||
|
||||
| 注解 | 用途 | 何时使用 |
|
||||
| :--- | :--- | :--- |
|
||||
| **`@Value`** | 注入单个值 | 当你只需要一两个简单的配置时。 |
|
||||
| **`@PropertySource`** | 加载额外的属性文件 | 当你的配置分散在多个自定义文件中时。 |
|
||||
| **`@ConfigurationProperties`** | **批量**、**类型安全**地绑定属性到对象 | **首选方式**。当你有一组相关配置时(如数据库、邮件、API密钥等)。 |
|
||||
| **`@EnableConfigurationProperties`** | 激活 `@ConfigurationProperties` 的类 | 总是与 `@ConfigurationProperties` 配合使用(除非用了`@Component`快捷方式)。 |
|
||||
| **`@TestPropertySource`** | 在测试中覆盖或提供配置 | 编写需要特定配置的集成测试或单元测试时。 |
|
||||
|
||||
**最佳实践**:
|
||||
|
||||
* **优先使用 `@ConfigurationProperties`**:对于任何超过两三个的相关配置,都应创建一个专用的 `Properties` 类。这会让你的代码更健壮、更易于维护。
|
||||
* **集中管理**: 将 `@EnableConfigurationProperties` 放在主配置类或一个集中的 `AppConfig` 类中,而不是到处分散。
|
||||
* **利用元数据**: 添加 `spring-boot-configuration-processor` 依赖到 `pom.xml` 或 `build.gradle`,以获得强大的 IDE 支持。
|
||||
39
src/content/posts/Java/Spring/什么是循环依赖.md
Normal file
39
src/content/posts/Java/Spring/什么是循环依赖.md
Normal file
@@ -0,0 +1,39 @@
|
||||
---
|
||||
title: 什么是循环依赖
|
||||
published: 2025-09-16
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [Spring,循环依赖,Java]
|
||||
category: 'Java > Spring'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# 什么是循环依赖
|
||||
循环依赖就是指两个或者多个模块,类组件之间互相依赖,形成一个闭环
|
||||
|
||||
```java
|
||||
@Service
|
||||
public class A {
|
||||
@Autowired
|
||||
private B b;
|
||||
}
|
||||
|
||||
@Service
|
||||
public class B {
|
||||
@Autowired
|
||||
private A a;
|
||||
}
|
||||
|
||||
//或者自己依赖自己
|
||||
@Service
|
||||
public class A {
|
||||
@Autowired
|
||||
private A a;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
就像上面这种情况,就属于循环依赖
|
||||
|
||||
|
||||
109
src/content/posts/Java/Spring/如何解决循环依赖.md
Normal file
109
src/content/posts/Java/Spring/如何解决循环依赖.md
Normal file
@@ -0,0 +1,109 @@
|
||||
---
|
||||
title: Spring如何解决循环依赖
|
||||
published: 2025-09-16
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [Spring,循环依赖,Java]
|
||||
category: 'Java > Spring'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# Spring如何解决循环依赖
|
||||
|
||||
关键是`提前暴露未完全创建完毕的Bean`
|
||||
Spring中采用了`三级缓存`解决了循环依赖
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
我们拿下面这个例子来讲
|
||||
```java
|
||||
@Service
|
||||
public class A {
|
||||
@Autowired
|
||||
private B b;
|
||||
}
|
||||
|
||||
@Service
|
||||
public class B {
|
||||
@Autowired
|
||||
private A a;
|
||||
}
|
||||
|
||||
//或者自己依赖自己
|
||||
@Service
|
||||
public class A {
|
||||
@Autowired
|
||||
private A a;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
首先要创建Bean A,去一级缓存里面找,发现没有,二级缓存里面找,发现也没有,三级里面也没有
|
||||
这个时候进入Bean A 的对象创建流程
|
||||
|
||||
接下来我们利用反射创建对象A,调用其无参构造方法,创建一个对象A 的实例,并将其包装成ObjectFactory放入三级缓存中。
|
||||

|
||||
|
||||

|
||||
|
||||
接下来要填充属性
|
||||

|
||||
|
||||
因为A对象的属性是B对象
|
||||
|
||||
所以现在要开始创建Bean B
|
||||
到一级,二级,三级缓存中找B对象,发现不存在,所以进入B对象的创建流程
|
||||
|
||||
依然是通过反射,调用B的无参构造方法创建B的实例,并将其包装成ObjectFactory放入三级缓存中。
|
||||
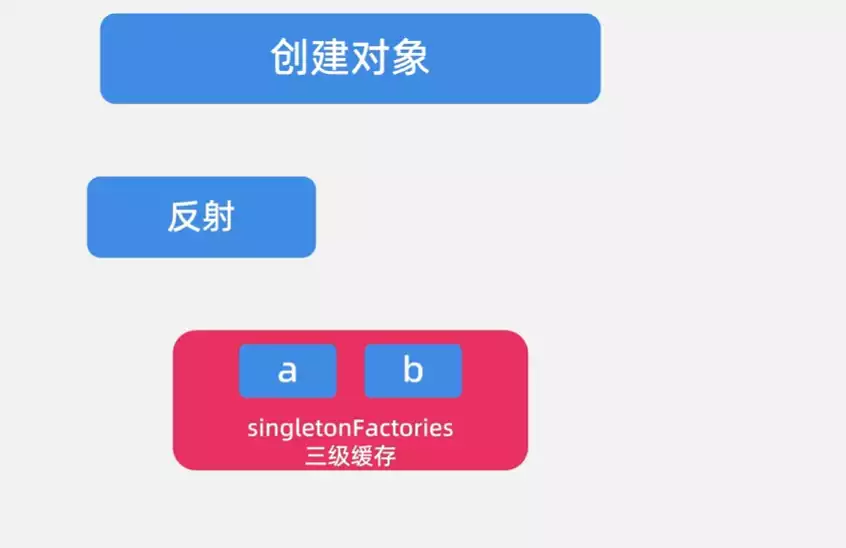
|
||||
|
||||
接下来要填充B对象的属性,就又要进入Bean A的创建流程中,再去缓存中查找A对象,我们能发现在三级缓存中已经有A的ObjectFactory了
|
||||
|
||||
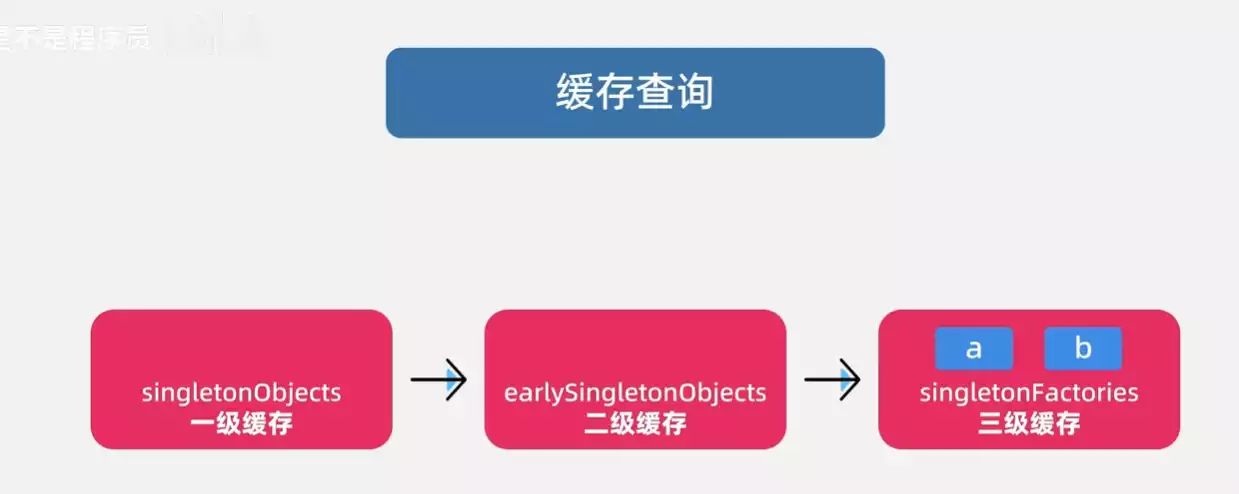
|
||||
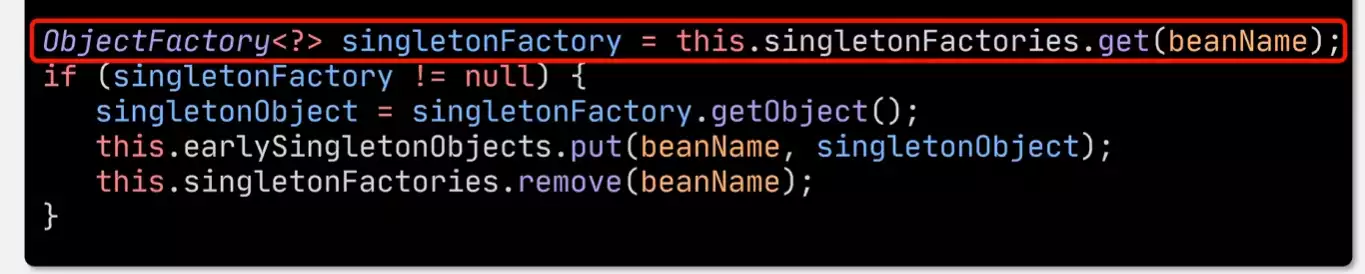
|
||||
|
||||
可以从源码中看到,我们会调用存放在三级缓存中A的ObjectFactory的getObject方法,创建单例对象,存放在earlySingletonObjects里面(二级缓存),然后从三级缓存中移除A的ObjectFactory
|
||||
|
||||

|
||||
|
||||
|
||||
好的,这样的话,我们就可以把A填充到B对象需要的属性里面了
|
||||
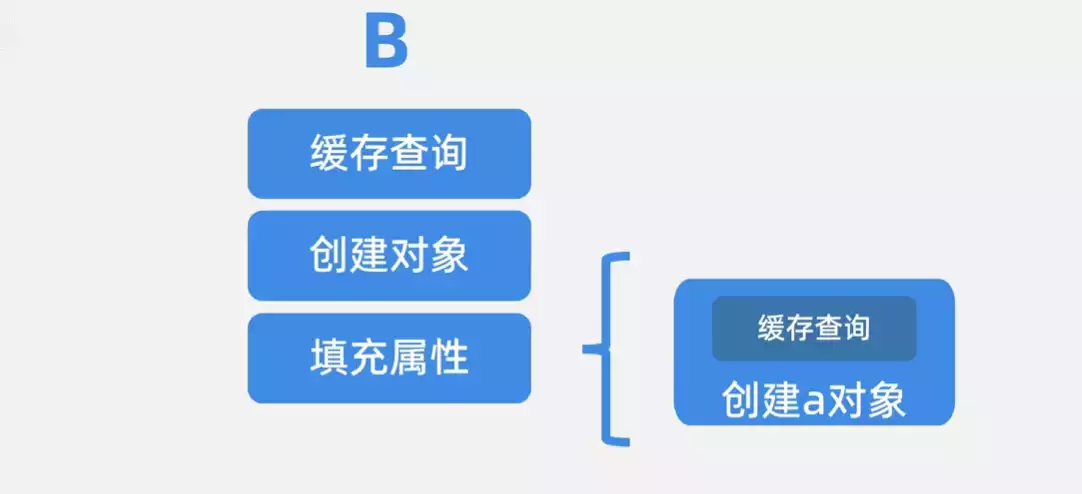
|
||||
|
||||

|
||||
|
||||
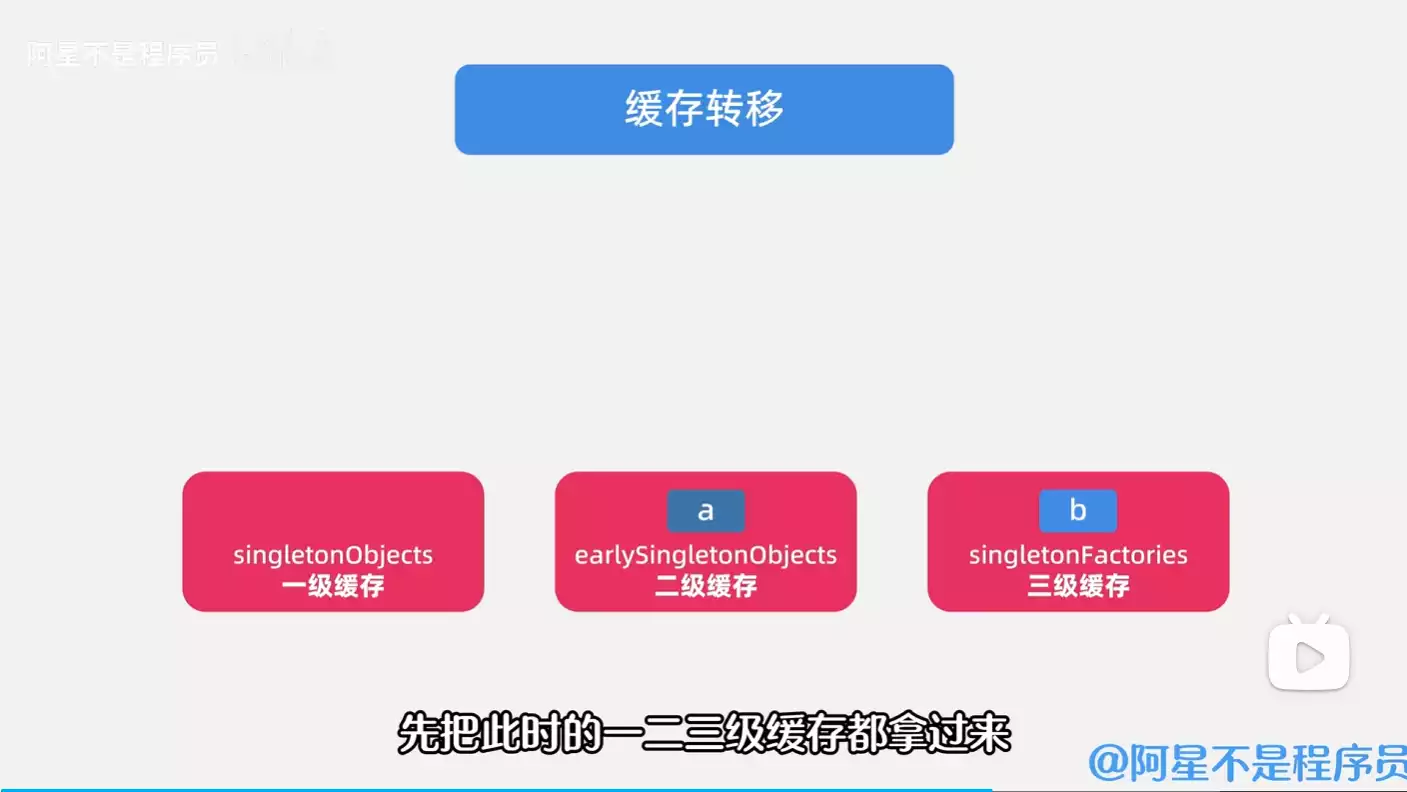
|
||||
|
||||
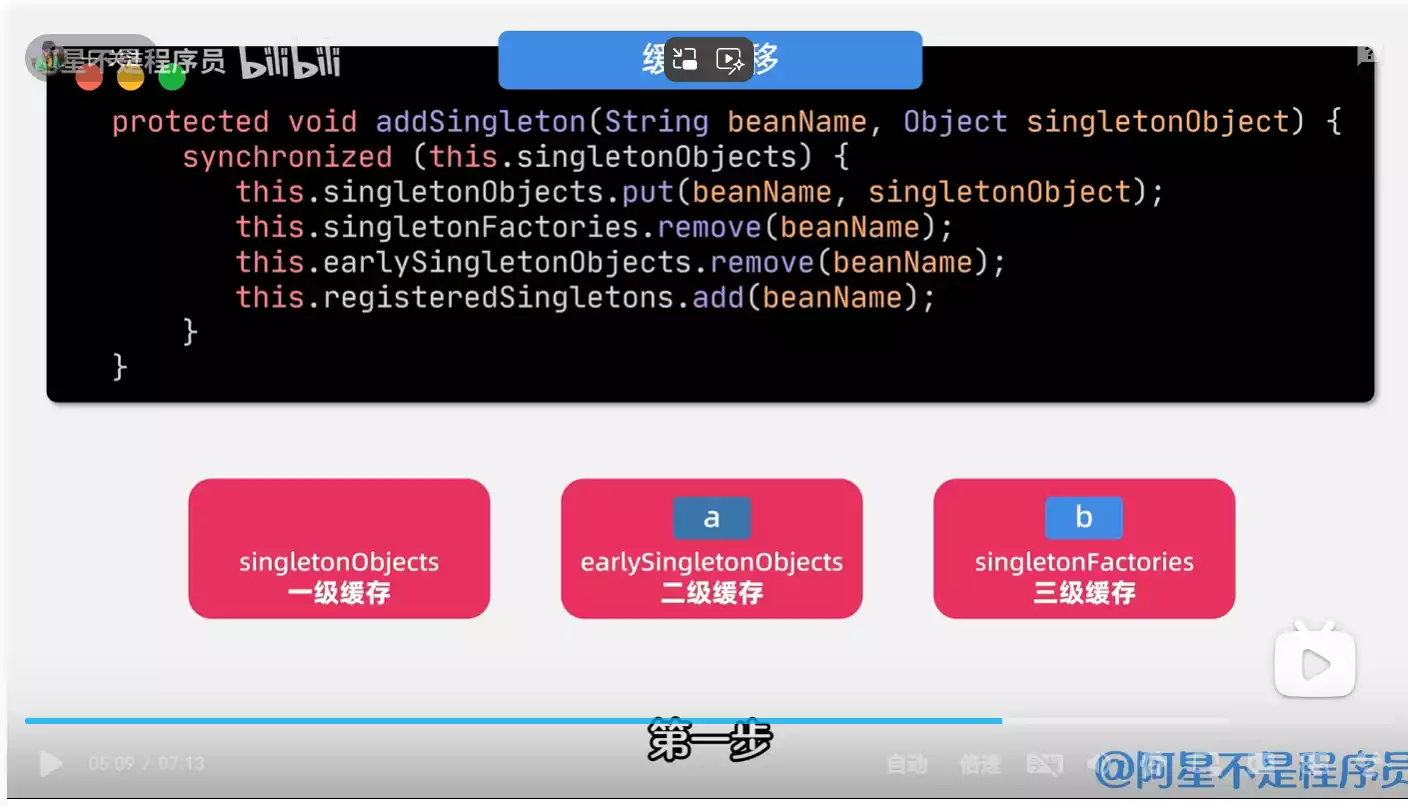
|
||||
|
||||
我们看看缓存转移的关键源码
|
||||
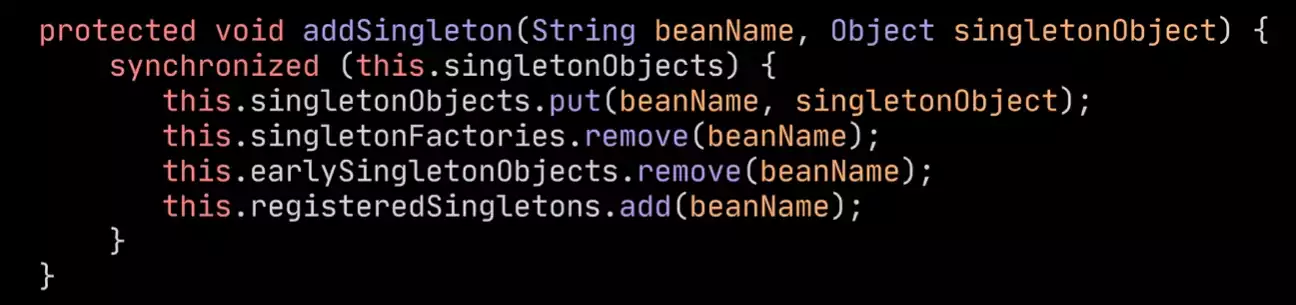
|
||||
第一步先把B的完整对象放到一级缓存中,然后从三级缓存中移除B的ObjectFactory,再从二级缓存中移除B(当然二级缓存中也没有B),接下来完成B的单例注册。这样缓存转移就完成了。
|
||||
|
||||
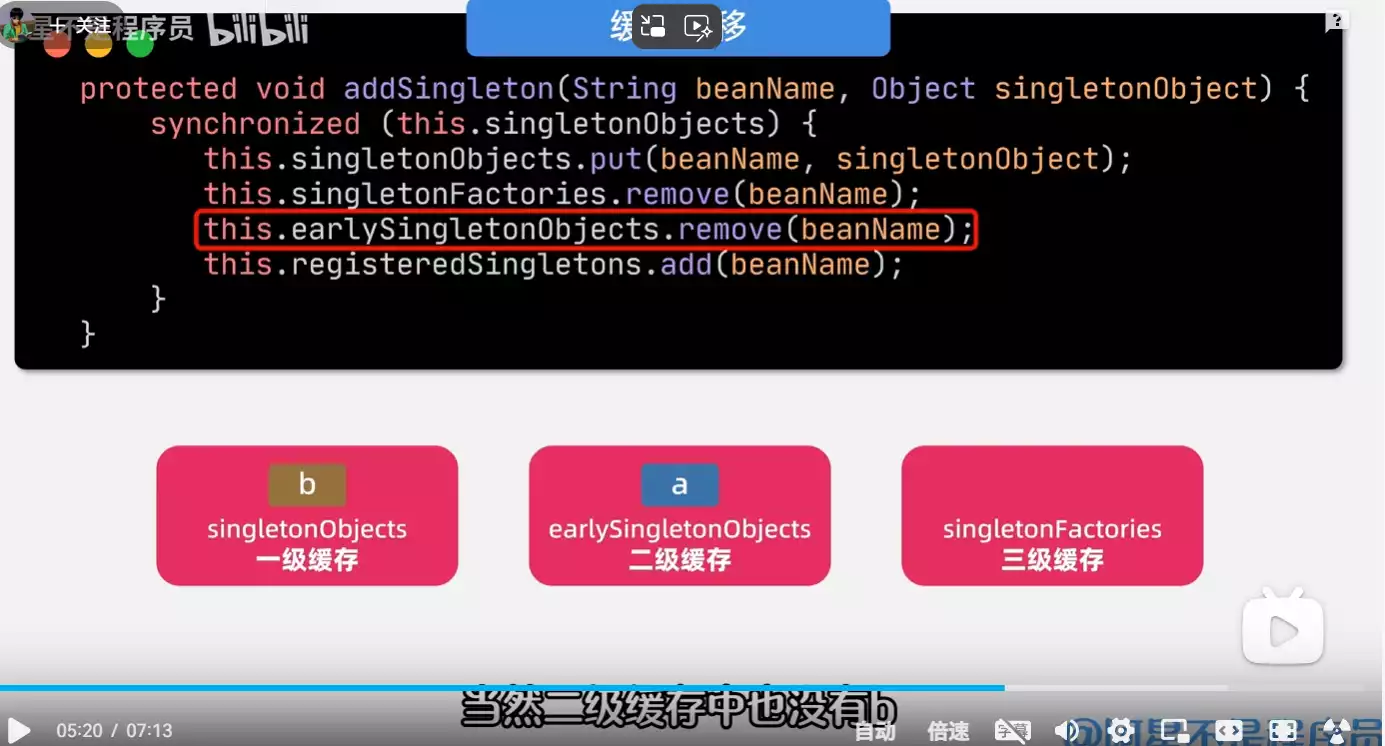
|
||||
这样就完成了B对象的初始化
|
||||

|
||||
|
||||
但是我们B对象的创建流程是在A对象的填充属性流程里,所以会继续A的填充属性流程,这个时候再去一级缓存里找B,就能找到B了,填充B并进行缓存转移,移除二级,三级缓存中的A对象,就可以注入B完成A初始化了
|
||||

|
||||
|
||||
|
||||
|
||||
# 三级缓存的作用
|
||||
为了AOP
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
当Spring没有循环依赖的情况下,是把普通对象创建好后再生成代理对象,Spring也没有办法提前知道对象之间的依赖关系。也不能把每个对象都创建出代理对象来,所以就需要把对象包装成objectFactory这个类型,通过其中的ObjectFactory对象中的getObject方法获取到生成的代理对象。
|
||||
|
||||
|
||||
261
src/content/posts/Java/java基础面试题.md
Normal file
261
src/content/posts/Java/java基础面试题.md
Normal file
@@ -0,0 +1,261 @@
|
||||
---
|
||||
title: java基础面试题
|
||||
published: 2025-07-25
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [Java,面试题]
|
||||
category: 'Java > 面试题'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
https://javaguide.cn/java
|
||||
|
||||
# Java基本数据类型
|
||||
|
||||
整数型,浮点型,布尔型,字符型
|
||||
整数型:
|
||||
byte,short,int,long
|
||||
浮点型: float,double
|
||||
布尔型: boolean
|
||||
字符型: char
|
||||
|
||||
|
||||
# 基本类型和包装类型的区别
|
||||
基本数据类型成员变量(未被static修饰) 存放在Java虚拟机的堆中
|
||||
|
||||
基本类型不一定被放在Java虚拟机的栈中,这取决于这个基本类型变量在哪个地方,如果它是作为方法中的局部变量,那么它是存放在栈中的,当这个基本类型变量被放在成员变量里面的时候,它才会被放到堆中。
|
||||
|
||||
当然被static修饰的基本类型一定是存放在Java虚拟机的堆中的。
|
||||
|
||||
# 包装类型的缓存机制
|
||||
Java基本数据类型的包装类大部分都用到了缓存机制来提升性能
|
||||
Byte,Short,Integer,Long这4种包装类默认创建了[-128,127]相应类型的缓存数据,Character创建了数值在[0,127]范围的缓存数据,Boolean直接返回TRUE或者FALSE
|
||||
|
||||
对于Integer,可以通过JVM参数 -XX:AutoBoxCacheMax 来设定范围,但是不能修改下限
|
||||
实际使用的时候,不建议设置过大的值,防止浪费内存,或者OOM
|
||||
|
||||
# equals方法和==的区别
|
||||
== 对于基本类型是判断值是否相等,对于引用类型是判断地址是否相等
|
||||
equals方法,因为所有类的顶层父类都是Object类,所以Object类中的equals方法判断的也是两个对象的内存地址是否相同
|
||||
因此需要重写equals方法,实现对象和对象之间的内容比较,当然了,重写equals方法的时候也需要重写hashCode方法,来保证在集合中使用的正确性。
|
||||
|
||||
# 自动装箱和自动拆箱
|
||||
什么是自动装箱?
|
||||
自动装箱是Java在基本数据和包装类型之间的自动转换,在基本类型到包装类型转换时,会调用包装类型的valueOf方法
|
||||
|
||||
|
||||
|
||||
什么是自动拆箱?
|
||||
|
||||
```java
|
||||
package cn.meowrain;
|
||||
|
||||
public class Main{
|
||||
public static void main(String[] args) {
|
||||
Integer i = Integer.valueOf(10);
|
||||
int j = i.intValue();
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
# 为什么浮点数运算的时候会有精度丢失的风险?
|
||||
计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况
|
||||
|
||||
# 如何解决浮点数运算的精度丢失问题?
|
||||
BigDecimal 可以实现对浮点数的运算,不会造成精度丢失。通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 BigDecimal 来做的。
|
||||
|
||||
BigDecimal的equals方法会比较精度还有值是否相等,BigDecimal的compareTo方法会比较值是否相等
|
||||
|
||||
# Java高精度
|
||||
BigDecimal, BigInteger
|
||||
|
||||
# 面向对象和面向过程的区别
|
||||
|
||||
面边过程编程和面向对象编程是两种常见的编程范式,两者的主要区别在于解决问题的方式不同:
|
||||
|
||||
面向过程编程: 面向过程会把解决问题的过程拆成一个一个方法,通过一个一个方法的执行去解决问题
|
||||
|
||||
面向对象编程: 会先抽象出对象,然后用对象执行方法的方式解决问题
|
||||
|
||||
面向对象编程开发的程序一般有下面的优点:
|
||||
- 易维护: 由于良好的结构和封装性,面向对象程序通常更容易维护
|
||||
- 易复用: 通过继承和多态,OOP设计使得代码更具有复用性,方便扩展功能
|
||||
- 易扩展: 模块化设计使得系统扩展变得更加容易和灵活。
|
||||
|
||||
|
||||
# 封装继承多态
|
||||
|
||||
封装是指将对象的属性和(数据)和方法(行为)捆绑在一起,并隐藏对象的内部实现细节,只暴露必要的接口给外部世界。有助于保护数据不被直接访问和修改,从而提高代码的安全性和可维护性。
|
||||
|
||||
继承是面向对象编程中的另外一个核心概念,允许一个类从另一个类中继承属性和方法,从而实现代码复用和层次结构,子类可以扩展或者修改父类的行为,不需要重新编写代码。
|
||||
|
||||
多态是指允许不同的对象对同一消息做出不同的响应,即同一方法可以根据发送对象的不同而采用多种不同的行为方式。多态的实现方式有:
|
||||
- 方法重载: 同一个类中,方法名相同,参数列表不同,返回值类型可以相同也可以不同
|
||||
- 方法重写: 子类中,方法名和参数列表与父类相同,返回值类型和异常类型也相同,但是方法体不同
|
||||
- 接口实现: 一个类实现了一个接口,那么这个类就可以被视为是这个接口的一个实例,从而可以调用接口中的方法。
|
||||
|
||||
|
||||
# 接口和抽象类的区别
|
||||
接口偏向于定义行为规范,是对行为的抽象,强调“能不能做”,“具备什么能力”
|
||||
抽象类偏向于定义共同的属性和方法,是对类的抽象,强调“是什么”的关系
|
||||
|
||||
共同点:
|
||||
接口和多态都不能被实例化,只能被实现或者继承后才能创建具体的对象。
|
||||
|
||||
# 为什么要有hashCode
|
||||
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashCode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashCode 值作比较,如果没有相符的 hashCode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashCode 值的对象,这时会调用 equals() 方法来检查 hashCode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
|
||||
|
||||
|
||||
那为什么 JDK 还要同时提供这两个方法呢?
|
||||
这是因为在一些容器(比如 HashMap、HashSet)中,有了 hashCode() 之后,判断元素是否在对应容器中的效率会更高(参考添加元素进HashSet的过程)!我们在前面也提到了添加元素进HashSet的过程,如果 HashSet 在对比的时候,同样的 hashCode 有多个对象,它会继续使用 equals() 来判断是否真的相同。也就是说 hashCode 帮助我们大大缩小了查找成本。
|
||||
|
||||
|
||||
equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
|
||||
|
||||
|
||||
# String类的不可变性是如何被保证的?
|
||||
1. String类被final修饰,也就是说String类是不可被继承的,不可被继承意味着没人能通过继承String类来修改String类的行为,从而保证了String类的不可变性。
|
||||
|
||||
2. 底层的字符数组被final修饰
|
||||
```java
|
||||
private final char value[];
|
||||
```
|
||||
这意味着这个value的引用是不可变的,不能指向其他数组,但是数组中的字符是可以变的。
|
||||
还需要进一步保护
|
||||
|
||||
3. 没有对外暴露value的引用,可以看到前面用了private修饰,无法被外部类通过数组引用修改数组内容
|
||||
|
||||
4. String类也没有提供可以修改String内部数组的方法
|
||||
|
||||
# String、StringBuffer、StringBuilder 的区别?
|
||||
|
||||
String是不可变的,StringBuilder和StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串,不过没有使用final和private关键字修饰
|
||||
|
||||
StringBuffer是线程安全的,里面大量使用了synchronized关键字来保证线程安全,而StringBuilder是线程不安全的。
|
||||
|
||||
|
||||
# String#equals() 和 Object#equals() 有何区别?
|
||||
因为String是引用类型,String中的equals方法是被重写过的,比较的是String字符串的值是否相等,Object中的equals方法是没有被重写的,比较的是对象的内存地址是否相等。
|
||||
|
||||
|
||||
|
||||
```java
|
||||
|
||||
/**
|
||||
* Compares this string to the specified object. The result is {@code
|
||||
* true} if and only if the argument is not {@code null} and is a {@code
|
||||
* String} object that represents the same sequence of characters as this
|
||||
* object.
|
||||
*
|
||||
* @param anObject
|
||||
* The object to compare this {@code String} against
|
||||
*
|
||||
* @return {@code true} if the given object represents a {@code String}
|
||||
* equivalent to this string, {@code false} otherwise
|
||||
*
|
||||
* @see #compareTo(String)
|
||||
* @see #equalsIgnoreCase(String)
|
||||
*/
|
||||
public boolean equals(Object anObject) {
|
||||
if (this == anObject) {
|
||||
return true;
|
||||
}
|
||||
if (anObject instanceof String) {
|
||||
String anotherString = (String)anObject;
|
||||
int n = value.length;
|
||||
if (n == anotherString.value.length) {
|
||||
char v1[] = value;
|
||||
char v2[] = anotherString.value;
|
||||
int i = 0;
|
||||
while (n-- != 0) {
|
||||
if (v1[i] != v2[i])
|
||||
return false;
|
||||
i++;
|
||||
}
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
# String#intern 方法有什么作用?
|
||||
String.intern() 是一个 native (本地) 方法,用来处理字符串常量池中的字符串对象引用。它的工作流程可以概括为以下两种情况:
|
||||
常量池中已有相同内容的字符串对象:如果字符串常量池中已经有一个与调用 intern() 方法的字符串内容相同的 String 对象,intern() 方法会直接返回常量池中该对象的引用。
|
||||
|
||||
常量池中没有相同内容的字符串对象:如果字符串常量池中还没有一个与调用 intern() 方法的字符串内容相同的对象,intern() 方法会将当前字符串对象的引用添加到字符串常量池中,并返回该引用。
|
||||
|
||||
```java
|
||||
package org.example;
|
||||
|
||||
public class Tests {
|
||||
|
||||
public static void main(String[] args) {
|
||||
// 已经有一个字符串常量 "abc"
|
||||
String abc = "abc";
|
||||
String str = new String("abc");
|
||||
System.out.println(str.intern() == str);
|
||||
System.out.println(abc == str.intern());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
可以看到,str.intern() 返回的是字符串常量池中的引用,而不是字符串对象的引用,所以 str.intern() != str。
|
||||
而 abc 是字符串常量池中的引用,所以 abc == str.intern()。
|
||||
|
||||
```java
|
||||
package org.example;
|
||||
|
||||
public class Tests {
|
||||
|
||||
public static void main(String[] args) {
|
||||
// 字符串常量池中之前没有"abc",所以 intern() 方法会将其添加到常量池中,并返回这个新创建的字符串对象的引用。
|
||||
String str = new String("abc");
|
||||
System.out.println(str.intern() == str);
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
这个例子中,str.intern() == str 为 false,因为 str.intern() 返回的是字符串常量池中的引用,而 str 是字符串对象的引用。
|
||||
|
||||
也就是说new String("abc")的时候,字面量"abc"在编译时就已经确定在常量池中了,运行时的new String()操作是基于已存在的字面量创建新对象,放在堆内存中。
|
||||
|
||||
|
||||
# 异常
|
||||
## Exception 和 Error 有什么区别?
|
||||
|
||||
在Java中,所有的异常都有一个共同的祖先java.lang包中的Throwable类,Throwable类有两个重要的子类:
|
||||
- Exception: 程序本身可以处理的异常,可以通过Catch进行捕获,Exception可以分为Checked Exception和Unchecked Exception。
|
||||
- Error: 程序无法处理的异常,Error类的异常是由JVM抛出的 语法上虽然可以捕获,但是一般不建议捕获Error类的异常,因为Error类的异常是由JVM抛出的,程序中无法捕获,也无法处理。
|
||||
|
||||
## Checked Exception 和 Unchecked Exception 有什么区别?
|
||||
Checked Exception 即 受检查异常 ,Java 代码在编译过程中,如果受检查异常没有被 catch或者throws 关键字处理的话,就没办法通过编译。
|
||||
|
||||
Unchecked Exception 即 非受检查异常 ,Java 代码在编译过程中,如果非受检查异常没有被 catch或者throws 关键字处理的话,也可以通过编译,但是在运行时会抛出异常。
|
||||
|
||||
|
||||
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。常见的受检查异常有:IO 相关的异常、ClassNotFoundException、SQLException...。
|
||||
|
||||
RuntimeException 及以下的异常类都被称为非受检查异常(Unchecked Exception),常见的非受检查异常有:ArrayIndexOutOfBoundsException、NullPointerException、ClassCastException...。
|
||||
|
||||
|
||||
|
||||
## Throwable 类常用方法有哪些?
|
||||
- String getMessage(): 返回异常发生时的详细信息
|
||||
- String toString(): 返回异常发生时的简要描述
|
||||
- String getLocalizedMessage(): 返回异常对象的本地化信息。使用 Throwable 的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与 getMessage()返回的结果相同
|
||||
- void printStackTrace(): 在控制台上打印 Throwable 对象封装的异常信息
|
||||
|
||||
> 不要在 finally 语句块中使用 return! 当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。
|
||||
|
||||
|
||||
# 什么是反射?
|
||||
反射是一种在程序运行的时候,动态地获取类的信息并且操作类或者对象的能力。
|
||||
|
||||
74
src/content/posts/Java/深入理解Java反射与泛型_类型擦除与强制类型转换.md
Normal file
74
src/content/posts/Java/深入理解Java反射与泛型_类型擦除与强制类型转换.md
Normal file
@@ -0,0 +1,74 @@
|
||||
---
|
||||
title: 深入理解Java反射与泛型_类型擦除与强制类型转换
|
||||
published: 2025-07-19
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [反射, 泛型, 类型擦除, 强制类型转换]
|
||||
category: 'Java'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
# 深入理解Java反射与泛型:类型擦除与强制类型转换
|
||||
|
||||
在 Java 编程中,反射(Reflection)和泛型(Generics)是两个强大且常用的特性。反射允许我们在运行时检查和操作类、方法、字段等,而泛型则允许我们编写更加通用和类型安全的代码。然而,Java 的泛型机制与类型擦除(Type Erasure)密切相关,这使得泛型在反射中的应用变得复杂。本文将深入探讨 Java 反射与泛型的结合使用,特别是类型擦除的影响以及如何通过强制类型转换来解决这些问题。
|
||||
|
||||
## 1. 泛型简介
|
||||
|
||||

|
||||
|
||||
## 类型擦除
|
||||
|
||||
### 1. 什么是类型擦除?
|
||||
|
||||
类型擦除(Type Erasure)是 Java 泛型的核心机制。它指的是**在编译阶段,Java 会移除所有泛型类型信息**,即只在源代码层面检查泛型参数的类型,到了运行时,相关类型信息就被“擦除”掉了。
|
||||
|
||||
### 2. 为什么会有类型擦除?
|
||||
|
||||
Java 为了兼容早期版本(Java 5 之前没有泛型),采用了类型擦除的方式实现泛型,这样泛型代码能够和老代码共存而不冲突。
|
||||
|
||||
### 3. 类型擦除具体表现
|
||||
|
||||
- **编译后不保留泛型类型参数信息。**
|
||||
示例:
|
||||
|
||||
```java
|
||||
List<String> stringList = new ArrayList<>();
|
||||
List<Integer> integerList = new ArrayList<>();
|
||||
System.out.println(stringList.getClass() == integerList.getClass()); // true
|
||||
```
|
||||
|
||||
运行时 `stringList` 和 `integerList` 其实都是 `ArrayList` 类型,不区分里面装的东西。
|
||||
|
||||
- **泛型类的字节码文件和“裸类型”一致。**
|
||||
例如 `List<String>`、`List<Integer>`、`List<Double>` 会被编译成一样的 `List` 类。
|
||||
|
||||
- **方法中的类型参数会被替换成它的限定类型(如果有),否则直接替换为 Object。**
|
||||
|
||||
```java
|
||||
class Box<T> {
|
||||
T value;
|
||||
}
|
||||
// 编译后其实相当于
|
||||
class Box {
|
||||
Object value;
|
||||
}
|
||||
```
|
||||
|
||||
### 4. 类型擦除带来的影响
|
||||
|
||||
- **运行时无法通过反射获得泛型参数的具体类型。** 除非通过继承和明确指定泛型参数,否则无法在运行时获得泛型具体类型。
|
||||
- **不能直接创建泛型数组。**
|
||||
- **某些类型强制转换失去编译器检查。**
|
||||
|
||||
### 5. 可以通过什么方式间接获取泛型类型?
|
||||
|
||||
- 通过创建“带泛型参数的子类”并用反射获取 `getGenericSuperclass()`,有时可以拿到实际类型参数。
|
||||
- 可以通过一些第三方库(如 Gson、Jackson)的特殊用法间接保存类型信息,但这些都是通过 hack 或特殊设计实现的。
|
||||
|
||||
---
|
||||
|
||||
### 总结一句话
|
||||
|
||||
Java 泛型只在编译阶段保证类型安全,运行阶段所有泛型信息都会被类型擦除,代码在运行时只知道原始类型,不再区分泛型参数。
|
||||
35
src/content/posts/Java/集合/ArrayList和LinkedList的区别.md
Normal file
35
src/content/posts/Java/集合/ArrayList和LinkedList的区别.md
Normal file
@@ -0,0 +1,35 @@
|
||||
---
|
||||
title: ArrayList和LinkedList的区别
|
||||
published: 2025-08-06
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['ArrayList', 'LinkedList']
|
||||
category: 'Java > 集合框架'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
# Java ArrayList和LinkedList的区别
|
||||
|
||||
ArrayList基于动态数组实现,LinkedList基于双向链表实现,这是它们所有性能差异的根本原因
|
||||
|
||||
ArrayList随机访问是O(1),但是中间插入是O(n),LinkedList则相反,随机访问是O(n),但在已知位置的插入删除是O(1)
|
||||
|
||||
LinkedList由于要存储前后节点的引用,每个元素的内存开销更大,ArrayList更节省内存,但可能因为扩容机制造成一定的浪费。
|
||||
|
||||
# 实际应用场景
|
||||
|
||||
在实际项目中,如果需要频繁随机访问元素,会选择ArrayList,如果需要频繁在两端添加删除元素,比如实现队列和栈,我会选择LinkedList
|
||||
|
||||
|
||||
|
||||
ArrayList和LinkedList都是Java中常见的集合类,它们都实现了List接口。
|
||||
底层数据结构不同:ArrayList使用数组实现,通过索引进行快速访问元素。
|
||||
LinkedList使用链表实现,通过节点之间的指针进行元素的访问和操作。
|
||||
插入和删除操作的效率不同:ArrayList在尾部的插入和删除操作效率较高,但在中间或开头的插入和删除操作效率较低,需要移动元素。
|
||||
LinkedList在任意位置的插入和删除操作效率都比较高,因为只需要调整节点之间的指针。随机访问的效率不同:ArrayList支持通过索引进行快速随机访问,时间复杂度为O(1)。
|
||||
LinkedList需要从头或尾开始遍历链表,时间复杂度为O(n)。
|
||||
空间占用:ArrayList在创建时需要分配一段连续的内存空间,因此会占用较大的空间。LinkedList每个节点只需要存储元素和指针,因此相对较小。
|
||||
使用场景:ArrayList适用于频繁随机访问和尾部的插入删除操作,而LinkedList适用于频繁的中间插入删除操作和不需要随机访问的场景。
|
||||
线程安全:这两个集合都不是线程安全的,Vector是线程安全的
|
||||
610
src/content/posts/Java/集合/HashMap原理.md
Normal file
610
src/content/posts/Java/集合/HashMap原理.md
Normal file
@@ -0,0 +1,610 @@
|
||||
---
|
||||
title: HashMap原理
|
||||
published: 2025-07-18
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [HashMap,Java]
|
||||
category: 'Java > 集合框架'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
# 说说HashMap的原理
|
||||
|
||||
HashMap是基于哈希表的数据结构,用于存储键值对。
|
||||
核心是将键的哈希值映射到数组索引位置,通过数组+链表+红黑树来解决哈希冲突。
|
||||
|
||||
HashMap使用键的hashCode()方法计算哈希值,通过`(n-1) &hash`确定元素在数组中的存储位置。
|
||||
|
||||
哈希值是经过一定的扰动处理的,防止哈希值分布不均,从而减少冲突,
|
||||
|
||||
HashMap的默认初始容量为16,负载因子为0.75,也就是说,当存储的元素数量超过16 * 0.75 = 12个的时候,HashMap会触发扩容操作,容量x2并重新分配元素位置,这种扩容是比较耗时的操作,频繁扩容会影响性能。
|
||||
|
||||
# 通过源码深入了解HashMap
|
||||
|
||||
```java
|
||||
// 默认初始容量 - 必须是 2 的幂次方。
|
||||
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 即 16
|
||||
|
||||
// 最大容量,如果构造函数中通过参数隐式指定了更高的值,则使用此最大容量。
|
||||
// 必须是小于等于 1 << 30 的 2 的幂次方。
|
||||
// 由于你可以随时指定非常大(甚至超过了1亿)的值,为了防止内存溢出或数组长度无效,HashMap内部通过MAXIMUM_CAPACITY做了一个“保险”,来确保容量不会超过某个安全极限。
|
||||
static final int MAXIMUM_CAPACITY = 1 << 30;
|
||||
|
||||
// 构造函数中未指定时使用的负载因子。
|
||||
static final float DEFAULT_LOAD_FACTOR = 0.75f;
|
||||
|
||||
// 在向存储单元添加元素时,存储单元使用树结构而不是链表结构的存储单元计数阈值。
|
||||
// 当向存储单元添加元素,且该存储单元至少有此数量的节点时,存储单元将转换为树结构。
|
||||
// 该值必须大于 2,并且应该至少为 8,以与移除元素时转换回普通存储单元的假设相匹配。
|
||||
static final int TREEIFY_THRESHOLD = 8;
|
||||
|
||||
// 在调整大小操作期间将(拆分的)存储单元转换为非树结构存储单元的存储单元计数阈值。
|
||||
// 应该小于 TREEIFY_THRESHOLD,并且最多为 6,以与移除元素时的收缩检测相匹配。
|
||||
static final int UNTREEIFY_THRESHOLD = 6;
|
||||
|
||||
// 存储单元可以树化的最小表容量。
|
||||
// (否则,如果存储单元中有太多节点,表将进行扩容。)
|
||||
// 应该至少是 4 * TREEIFY_THRESHOLD,以避免扩容和树化阈值之间的冲突。
|
||||
static final int MIN_TREEIFY_CAPACITY = 64;
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
# HashMap的存储结构
|
||||
|
||||
从源码上看,HashMap的每个存储单元都是一个链表或者红黑树,也就是下面的Node类,那么我们可以用下面的图来展示一个完成初始化的HashMap的存储结构。
|
||||
|
||||
|
||||
|
||||
### 为什么采用数组?
|
||||
|
||||
因为数组的随机访问速度非常快,HashMap通过哈希函数将键映射到数组索引位置,从而实现快速查找。
|
||||
|
||||
数组的每一个元素称为一个桶(bucket),对于一个给定的键值对key,value,HashMap会计算出一个哈希值(计算的是key的hash),然后通过`(n-1) & hash`来确定该键值对在数组中的位置。
|
||||
|
||||
### 如何定位key value该存储在桶数组的哪个位置上?(获取index)
|
||||
|
||||
HashMap通过`(n - 1) & hash`来计算索引位置,其中n是数组的长度,hash是键的哈希值。
|
||||
|
||||
### 如何计算hash值?
|
||||
|
||||
HashMap使用键的`hashCode()`方法计算哈希值,然后对哈希值进行扰动处理,最后通过`(n-1) & hash`来确定元素在数组中的存储位置。
|
||||
|
||||
### 为什么要扰动处理?
|
||||
|
||||
扰动处理是为了减少哈希冲突,防止哈希值分布不均。HashMap会对哈希值进行扰动处理,以确保不同的键能够更均匀地分布在数组中,从而减少冲突。
|
||||
|
||||
在Java 8中,HashMap使用了一个扰动函数来优化hash值的分布:
|
||||
|
||||
```java
|
||||
static final int hash(Object key) {
|
||||
int h;
|
||||
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
|
||||
}
|
||||
```
|
||||
|
||||
这个函数的作用是:
|
||||
|
||||
1. 首先获取key的hashCode()值
|
||||
2. 将hashCode的高16位与低16位进行异或运算
|
||||
|
||||
### 为什么用的是&运算而不是取模运算?
|
||||
|
||||
在java中,我们会让HashMap的容量是2的幂次方,这样可以通过`(n-1) & hash`来快速计算出索引位置,避免了取模运算的性能开销。
|
||||
|
||||
这里`(n - 1) & hash` == `hash % n`,但&运算比取模运算更高效。
|
||||
|
||||
n是数组的长度,hash是键的哈希值。
|
||||
|
||||
### 为什么要让HashMap的容量是2的幂次方?
|
||||
|
||||
因为当容量是2的幂次方时,`(n-1) & hash`可以快速计算出索引位置,而不需要进行取模运算。
|
||||
|
||||
|
||||
|
||||
### 为什么会用到链表?
|
||||
|
||||
我们在HashMap的使用过程中,可能会遇到哈希冲突的情况,也就是不同的键经过哈希函数计算后得到了相同的索引位置,使用链表我们可以把这些冲突的键值对存储在同一个桶中,用链表连接在一起,jdk8开始,链表节点不再使用头插法,而是使用尾插法,这样可以减少链表的长度,提升查找效率。
|
||||
|
||||
头插法还可能造成链表形成环形,导致死循环。
|
||||
|
||||
|
||||
|
||||
## Node
|
||||
|
||||
```java
|
||||
static class Node<K,V> implements Map.Entry<K,V> {
|
||||
final int hash;
|
||||
final K key;
|
||||
V value;
|
||||
Node<K,V> next;
|
||||
|
||||
Node(int hash, K key, V value, Node<K,V> next) {
|
||||
this.hash = hash;
|
||||
this.key = key;
|
||||
this.value = value;
|
||||
this.next = next;
|
||||
}
|
||||
|
||||
public final K getKey() { return key; }
|
||||
public final V getValue() { return value; }
|
||||
public final String toString() { return key + "=" + value; }
|
||||
|
||||
public final int hashCode() {
|
||||
return Objects.hashCode(key) ^ Objects.hashCode(value);
|
||||
}
|
||||
|
||||
public final V setValue(V newValue) {
|
||||
V oldValue = value;
|
||||
value = newValue;
|
||||
return oldValue;
|
||||
}
|
||||
|
||||
public final boolean equals(Object o) {
|
||||
if (o == this)
|
||||
return true;
|
||||
|
||||
return o instanceof Map.Entry<?, ?> e
|
||||
&& Objects.equals(key, e.getKey())
|
||||
&& Objects.equals(value, e.getValue());
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
# HashMap的Put方法
|
||||
|
||||
HashMap的put方法是用来添加键值对到HashMap中的核心方法。它的实现逻辑如下:
|
||||
|
||||
```java
|
||||
/**
|
||||
* 实现 Map.put 和相关方法。
|
||||
*
|
||||
* @param hash key的哈希值
|
||||
* @param key 键
|
||||
* @param value 要放入的值
|
||||
* @param onlyIfAbsent 如果为 true,则不更改现有值
|
||||
* @param evict 如果为 false,则表处于创建模式。
|
||||
* @return 返回先前的值,如果没有则返回 null
|
||||
*/
|
||||
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
|
||||
boolean evict) { // 📌 定义 putVal 方法,用于将键值对放入 HashMap
|
||||
Node<K,V>[] tab; Node<K,V> p; int n, i; // 🏷️ 声明局部变量:tab (哈希表数组), p (当前节点), n (数组长度), i (数组索引)
|
||||
// 检查哈希表是否为空或长度为0
|
||||
if ((tab = table) == null || (n = tab.length) == 0)
|
||||
// 🏗️ 如果为空,则调用 resize() 方法初始化或扩容哈希表,并获取新的长度
|
||||
n = (tab = resize()).length;
|
||||
// 🎯 计算键在哈希表中的索引位置 i,并检查该位置是否为空
|
||||
if ((p = tab[i = (n - 1) & hash]) == null)
|
||||
// ✨ 如果为空,直接在该位置创建一个新节点
|
||||
tab[i] = newNode(hash, key, value, null);
|
||||
else { // 🤔 如果该位置不为空(发生哈希冲突)
|
||||
Node<K,V> e; K k; // 🏷️ 声明局部变量:e (用于找到的已存在节点或新节点), k (临时键)
|
||||
// 🔑 检查桶中第一个节点的哈希值和键是否与要插入的键值对匹配
|
||||
if (p.hash == hash &&
|
||||
((k = p.key) == key || (key != null && key.equals(k))))
|
||||
// ✅ 如果匹配,将 e 指向该节点 p (表示键已存在)
|
||||
e = p;
|
||||
// 🌳 检查桶中的节点是否为 TreeNode (红黑树节点)
|
||||
else if (p instanceof TreeNode)
|
||||
// 🌲 如果是红黑树,调用 putTreeVal 方法将键值对插入红黑树
|
||||
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
|
||||
else { // 🔗 如果是链表
|
||||
// 🔄 遍历链表
|
||||
for (int binCount = 0; ; ++binCount) {
|
||||
// نهاية 检查当前节点的下一个节点是否为空 (到达链表尾部)
|
||||
if ((e = p.next) == null) {
|
||||
// ➕ 在链表尾部插入新节点
|
||||
p.next = newNode(hash, key, value, null);
|
||||
// 🌲❓ 检查链表长度是否达到树化阈值 (TREEIFY_THRESHOLD - 1 因为 binCount 从0开始计数,且当前p是尾部的前一个节点)
|
||||
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
|
||||
// 🌳🔗➡️🌳 如果达到阈值,将链表转换为红黑树
|
||||
treeifyBin(tab, hash);
|
||||
break; // 🛑 跳出循环,因为新节点已插入
|
||||
}
|
||||
// 🔑 检查链表中节点的哈希值和键是否与要插入的键值对匹配
|
||||
if (e.hash == hash &&
|
||||
((k = e.key) == key || (key != null && key.equals(k))))
|
||||
break; // ✅ 如果匹配,跳出循环 (表示键已存在,e 指向该节点)
|
||||
// 👉 将 p 指向下一个节点,继续遍历
|
||||
p = e;
|
||||
}
|
||||
}
|
||||
// 🔑❓ 检查 e 是否不为 null (表示键已存在于哈希表中,或者在红黑树中找到了/插入了节点)
|
||||
if (e != null) { // existing mapping for key
|
||||
// 💾 获取旧值
|
||||
V oldValue = e.value;
|
||||
// 🔄❓ 根据 onlyIfAbsent 参数决定是否更新值 (如果 onlyIfAbsent 为 false,或者旧值为 null,则更新)
|
||||
if (!onlyIfAbsent || oldValue == null)
|
||||
// ⬆️ 更新节点的值
|
||||
e.value = value;
|
||||
// 🔗 回调方法,用于 LinkedHashMap 等子类记录节点访问
|
||||
afterNodeAccess(e);
|
||||
// ↩️ 返回旧值
|
||||
return oldValue;
|
||||
}
|
||||
}
|
||||
// 🛠️ 修改计数器加1,用于迭代器快速失败机制
|
||||
++modCount;
|
||||
// 📈 检查当前元素数量是否超过阈值 (threshold = capacity * loadFactor)
|
||||
if (++size > threshold)
|
||||
// 🏗️ 如果超过阈值,调用 resize() 方法扩容哈希表
|
||||
resize();
|
||||
// 🔗 回调方法,用于 LinkedHashMap 等子类记录节点插入
|
||||
afterNodeInsertion(evict);
|
||||
// ↩️ 如果是新插入的键值对,返回 null
|
||||
return null;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
# HashMap的Get方法
|
||||
|
||||
```java
|
||||
/**
|
||||
* 实现 Map.get 和相关方法。
|
||||
*
|
||||
* @param key 要查找的键
|
||||
* @return 返回找到的节点,如果没有找到则返回 null
|
||||
*/
|
||||
final Node<K,V> getNode(Object key) { // 📌 定义 getNode 方法,用于根据键查找节点
|
||||
Node<K,V>[] tab; Node<K,V> first, e; int n, hash; K k; // 🏷️ 声明局部变量:tab (哈希表数组), first (桶中第一个节点), e (当前节点), n (数组长度), hash (键的哈希值), k (临时键)
|
||||
// 🔍 检查哈希表是否不为空且长度大于0,并且根据键的哈希值计算出的桶位置有节点
|
||||
if ((tab = table) != null && (n = tab.length) > 0 &&
|
||||
(first = tab[(n - 1) & (hash = hash(key))]) != null) {
|
||||
// 🎯 首先检查桶中第一个节点的哈希值和键是否与要查找的键匹配
|
||||
if (first.hash == hash && // always check first node 总是先检查第一个节点
|
||||
((k = first.key) == key || (key != null && key.equals(k))))
|
||||
// ✅ 如果匹配,直接返回第一个节点
|
||||
return first;
|
||||
// 🔗 检查第一个节点是否有下一个节点(链表或红黑树)
|
||||
if ((e = first.next) != null) {
|
||||
// 🌳 如果第一个节点是 TreeNode(红黑树节点)
|
||||
if (first instanceof TreeNode)
|
||||
// 🌲 在红黑树中查找并返回节点
|
||||
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
|
||||
// 🔄 如果是链表,遍历链表查找节点
|
||||
do {
|
||||
// 🔑 检查当前节点的哈希值和键是否与要查找的键匹配
|
||||
if (e.hash == hash &&
|
||||
((k = e.key) == key || (key != null && key.equals(k))))
|
||||
// ✅ 如果匹配,返回当前节点
|
||||
return e;
|
||||
// 👉 移动到下一个节点,继续遍历直到链表末尾
|
||||
} while ((e = e.next) != null);
|
||||
}
|
||||
}
|
||||
// ❌ 如果没有找到匹配的节点,返回 null
|
||||
return null;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
# HashMap的扩容
|
||||
|
||||
HashMap的扩容是指当存储的元素数量超过负载因子所允许的最大数量时,HashMap会自动增加其容量。
|
||||
扩容的过程包括以下几个步骤:
|
||||
|
||||
1. **计算新的容量**:新的容量通常是当前容量的两倍。
|
||||
2. **创建新的数组**:创建一个新的数组来存储扩容后的元素。
|
||||
3. **重新计算索引位置**:对于每个元素,重新计算其在新数组中的索引位置,并将其移动到新数组中。
|
||||
|
||||
源码中是resize()函数
|
||||
|
||||
```java
|
||||
/**
|
||||
* 初始化或将表大小扩大一倍。如果为null,则根据字段threshold中保存的初始容量目标进行分配。
|
||||
* 否则,因为我们使用的是2的幂次方扩展,每个桶中的元素必须保持在相同的索引位置,
|
||||
* 或者在新表中以2的幂次方偏移量移动。
|
||||
*
|
||||
* @return 返回新的哈希表
|
||||
*/
|
||||
final Node<K,V>[] resize() { // 📏 定义扩容方法
|
||||
Node<K,V>[] oldTab = table; // 🗂️ 保存旧的哈希表引用
|
||||
int oldCap = (oldTab == null) ? 0 : oldTab.length; // 📊 获取旧表的容量,如果为null则容量为0
|
||||
int oldThr = threshold; // 📋 保存旧的阈值
|
||||
int newCap, newThr = 0; // 🆕 声明新容量和新阈值变量
|
||||
|
||||
// 🔍 如果旧容量大于0(表已初始化)
|
||||
if (oldCap > 0) {
|
||||
// ⚠️ 如果旧容量已达到最大值,则不再扩容
|
||||
if (oldCap >= MAXIMUM_CAPACITY) {
|
||||
threshold = Integer.MAX_VALUE; // 🔢 将阈值设为最大整数值
|
||||
return oldTab; // ↩️ 直接返回旧表,不扩容
|
||||
}
|
||||
// 🔢 新容量 = 旧容量 * 2,且不超过最大容量,且旧容量 >= 默认初始容量
|
||||
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
|
||||
oldCap >= DEFAULT_INITIAL_CAPACITY)
|
||||
newThr = oldThr << 1; // 📈 新阈值 = 旧阈值 * 2
|
||||
}
|
||||
// 🎯 如果旧容量为0但旧阈值大于0(通过构造函数指定了初始容量)
|
||||
else if (oldThr > 0)
|
||||
newCap = oldThr; // 🆕 新容量等于旧阈值
|
||||
// 🌟 如果旧容量和旧阈值都为0(使用默认值初始化)
|
||||
else {
|
||||
newCap = DEFAULT_INITIAL_CAPACITY; // 🔢 新容量设为默认初始容量16
|
||||
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); // 📊 新阈值 = 0.75 * 16 = 12
|
||||
}
|
||||
|
||||
// 🔧 如果新阈值为0,需要重新计算
|
||||
if (newThr == 0) {
|
||||
float ft = (float)newCap * loadFactor; // 📐 计算新阈值 = 新容量 * 负载因子
|
||||
// ✅ 确保新阈值不超过最大值
|
||||
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
|
||||
(int)ft : Integer.MAX_VALUE);
|
||||
}
|
||||
|
||||
threshold = newThr; // 📋 更新阈值
|
||||
@SuppressWarnings({"rawtypes","unchecked"})
|
||||
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 🏗️ 创建新的哈希表数组
|
||||
table = newTab; // 🔄 将新表赋值给table字段
|
||||
|
||||
// 📦 如果旧表不为空,需要转移元素
|
||||
if (oldTab != null) {
|
||||
// 🔄 遍历旧表的每个桶
|
||||
for (int j = 0; j < oldCap; ++j) {
|
||||
Node<K,V> e; // 🏷️ 当前节点
|
||||
// 🔍 如果当前桶不为空
|
||||
if ((e = oldTab[j]) != null) {
|
||||
oldTab[j] = null; // 🧹 清空旧桶,帮助GC
|
||||
|
||||
// 🔗 如果桶中只有一个节点(没有链表或红黑树)
|
||||
if (e.next == null)
|
||||
newTab[e.hash & (newCap - 1)] = e; // 🎯 直接重新计算位置并放入新表
|
||||
|
||||
// 🌳 如果是红黑树节点
|
||||
else if (e instanceof TreeNode)
|
||||
((TreeNode<K,V>)e).split(this, newTab, j, oldCap); // 🌲 调用红黑树的分割方法
|
||||
|
||||
// 🔗 如果是链表
|
||||
else {
|
||||
Node<K,V> loHead = null, loTail = null; // 🔻 低位链表的头和尾节点
|
||||
Node<K,V> hiHead = null, hiTail = null; // 🔺 高位链表的头和尾节点
|
||||
Node<K,V> next; // ➡️ 下一个节点
|
||||
|
||||
// 🔄 遍历链表中的所有节点
|
||||
do {
|
||||
next = e.next; // 📍 保存下一个节点
|
||||
|
||||
// 🎲 通过 (e.hash & oldCap) 判断节点应该放在哪个位置
|
||||
if ((e.hash & oldCap) == 0) {
|
||||
// 🔻 放在原位置(低位链表)
|
||||
if (loTail == null)
|
||||
loHead = e; // 🎯 如果低位链表为空,设置头节点
|
||||
else
|
||||
loTail.next = e; // 🔗 连接到低位链表尾部
|
||||
loTail = e; // 📍 更新尾节点
|
||||
}
|
||||
else {
|
||||
// 🔺 放在原位置+oldCap的位置(高位链表)
|
||||
if (hiTail == null)
|
||||
hiHead = e; // 🎯 如果高位链表为空,设置头节点
|
||||
else
|
||||
hiTail.next = e; // 🔗 连接到高位链表尾部
|
||||
hiTail = e; // 📍 更新尾节点
|
||||
}
|
||||
} while ((e = next) != null); // 🔄 继续遍历直到链表末尾
|
||||
|
||||
// 🔻 如果低位链表不为空,放入原位置
|
||||
if (loTail != null) {
|
||||
loTail.next = null; // ✂️ 断开链表尾部
|
||||
newTab[j] = loHead; // 📍 放入新表的原位置
|
||||
}
|
||||
|
||||
// 🔺 如果高位链表不为空,放入新位置
|
||||
if (hiTail != null) {
|
||||
hiTail.next = null; // ✂️ 断开链表尾部
|
||||
newTab[j + oldCap] = hiHead; // 📍 放入新表的 j + oldCap 位置
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
return newTab; // ↩️ 返回新的哈希表
|
||||
}
|
||||
```
|
||||
|
||||
## 扩容的时候高位和低位链表详解
|
||||
|
||||
```java
|
||||
else {
|
||||
Node<K,V> loHead = null, loTail = null; // 🔻 低位链表的头和尾节点
|
||||
Node<K,V> hiHead = null, hiTail = null; // 🔺 高位链表的头和尾节点
|
||||
Node<K,V> next; // ➡️ 下一个节点
|
||||
|
||||
// 🔄 遍历链表中的所有节点
|
||||
do {
|
||||
next = e.next; // 📍 保存下一个节点
|
||||
|
||||
// 🎲 通过 (e.hash & oldCap) 判断节点应该放在哪个位置
|
||||
if ((e.hash & oldCap) == 0) {
|
||||
// 🔻 放在原位置(低位链表)
|
||||
if (loTail == null)
|
||||
loHead = e; // 🎯 如果低位链表为空,设置头节点
|
||||
else
|
||||
loTail.next = e; // 🔗 连接到低位链表尾部
|
||||
loTail = e; // 📍 更新尾节点
|
||||
}
|
||||
else {
|
||||
// 🔺 放在原位置+oldCap的位置(高位链表)
|
||||
if (hiTail == null)
|
||||
hiHead = e; // 🎯 如果高位链表为空,设置头节点
|
||||
else
|
||||
hiTail.next = e; // 🔗 连接到高位链表尾部
|
||||
hiTail = e; // 📍 更新尾节点
|
||||
}
|
||||
} while ((e = next) != null); // 🔄 继续遍历直到链表末尾
|
||||
|
||||
// 🔻 如果低位链表不为空,放入原位置
|
||||
if (loTail != null) {
|
||||
loTail.next = null; // ✂️ 断开链表尾部
|
||||
newTab[j] = loHead; // 📍 放入新表的原位置
|
||||
}
|
||||
|
||||
// 🔺 如果高位链表不为空,放入新位置
|
||||
if (hiTail != null) {
|
||||
hiTail.next = null; // ✂️ 断开链表尾部
|
||||
newTab[j + oldCap] = hiHead; // 📍 放入新表的 j + oldCap 位置
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 核心原理
|
||||
|
||||
当HashMap从容量n扩容到2n时,每个元素的新位置只有两种可能:
|
||||
|
||||
- **保持原位置**(低位链表)
|
||||
- **移动到原位置+n**(高位链表)
|
||||
|
||||
判断依据: `(e.hash & oldCap) == 0`,如果为0,则放在原位置,否则放在原位置+n。 n是旧容量。
|
||||
|
||||
- 低位链表(lo list):满足 `(e.hash & oldCap) == 0` 的节点,扩容后**继续放在原位置** `j`。
|
||||
- 高位链表(hi list):满足 `(e.hash & oldCap) != 0` 的节点,扩容后放在新位置 `j + oldCap`。
|
||||
|
||||
#### 举例子
|
||||
|
||||
假设oldCap = 16,newCap = 32
|
||||
|
||||
oldCap=16 // 10000
|
||||
|
||||
newCap=32 // 100000
|
||||
|
||||
```
|
||||
hash1 = 5; // 000101
|
||||
|
||||
扩容前(cap = 16)计算index
|
||||
|
||||
index1 = hash1 & (oldCap - 1) ==> 5 & 15
|
||||
000101
|
||||
&000111
|
||||
`--------`
|
||||
000101 ==> 5
|
||||
|
||||
扩容后(cap = 32)计算index
|
||||
我们要看要不要移动这个kv到桶中的新位置
|
||||
判断 (hash & oldCap) == 0
|
||||
|
||||
hash1 & oldCap ==> 5 & 16
|
||||
00000101
|
||||
& 00010000
|
||||
`-----------`
|
||||
00000000 ==> 0
|
||||
所以这个kv会放在原位置5
|
||||
```
|
||||
|
||||
再举个例子
|
||||
|
||||
```
|
||||
hash2 = 20; // 10100
|
||||
|
||||
扩容前(cap = 16)计算index
|
||||
|
||||
index2 = hash2 & (oldCap - 1) ==> 20 & 15
|
||||
10100
|
||||
& 01111
|
||||
--------------
|
||||
00100 ==> 4
|
||||
|
||||
扩容后(cap = 32)计算index
|
||||
要先看hash & oldCap == 0 ?
|
||||
|
||||
hash2 & oldCap ==> 20 & 16
|
||||
00010100
|
||||
& 00010000
|
||||
--------------
|
||||
00010000 ==> 16
|
||||
|
||||
不为0,所以这个20会放在新的位置 原来的位置+ 旧桶数组容量 = 4 + 16 = 20
|
||||
|
||||
```
|
||||
|
||||
你的理解非常正确!🎉👍
|
||||
|
||||
你已经掌握了HashMap扩容时分桶位置变更的本质原理,让我们用你的描述稍作归纳和梳理,验证你的思路:
|
||||
|
||||
---
|
||||
|
||||
### 为什么判断的是与oldCap相与得到的值是1还是0来决定搬迁位置?
|
||||
|
||||
当HashMap扩容时,容量从 `oldCap` 扩展到 `newCap`,比如从 16 扩展到 32。
|
||||
|
||||
- 原来 HashMap 的下标计算是:`index = hash & (oldCap-1)`,比如 `00001111`(低4位)。
|
||||
- 扩容后,计算下标变为:`index = hash & (newCap-1)`,比如 `00011111`(低5位),也就是多了一位。
|
||||
- 和 `oldCap`(如 `00010000`)相与,就相当于“掐头去尾”地只关注扩容新增的那一位:
|
||||
- 如果 `(hash & oldCap) == 0`,说明这位是0,**扩容后的位置等于原index**
|
||||
- 如果 `(hash & oldCap) != 0`,说明这位是1,**扩容后的位置等于原index + oldCap**
|
||||
- 这种判断,让你高效知道节点该不该搬迁以及搬去哪里,无需重新完全计算index。
|
||||
|
||||
---
|
||||
|
||||
#### 举例验证(巩固印象)
|
||||
|
||||
假如:
|
||||
|
||||
- oldCap = 16 ⇒ 00010000
|
||||
- oldCap-1 = 15 ⇒ 00001111
|
||||
- newCap = 32 ⇒ 00100000
|
||||
- newCap-1 = 31 ⇒ 00011111
|
||||
- hash = 21 ⇒ 10101
|
||||
|
||||
**扩容前下标:**
|
||||
|
||||
```java
|
||||
index = 10101 & 01111 = 00101 = 5
|
||||
```
|
||||
|
||||
**扩容后下标:**
|
||||
|
||||
```java
|
||||
index = 10101 & 11111 = 10101 = 21
|
||||
```
|
||||
|
||||
**oldCap这一位的判断:**
|
||||
|
||||
```java
|
||||
10101 & 10000 = 10000 ≠ 0
|
||||
```
|
||||
|
||||
说明这位是1,扩容后下标变成原index+16=21。
|
||||
|
||||
---
|
||||
|
||||
### 扩容的条件是什么?
|
||||
|
||||
当 HashMap 中存储的元素数量超过了「阈值」(threshold)时,就会进行扩容。
|
||||
这个「阈值」的计算公式是:
|
||||
|
||||
```
|
||||
threshold = capacity * loadFactor
|
||||
```
|
||||
|
||||
loadFactor 是负载因子,默认值为 0.75。
|
||||
|
||||
### 为什么要进行搬迁呢?
|
||||
|
||||
HashMap扩容的主要目的是:
|
||||
减少哈希冲突,提高查找、插入效率。
|
||||
让更多桶可用,降低碰撞链表队列的长度。
|
||||
|
||||
# jdk1.7和jdk1.8中hashmap的区别
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
# 链表什么时候转红黑树?
|
||||
|
||||
桶数组中某个桶的链表长度>=8 而且桶数组长度> 64的时候,hashmap会转换为红黑树
|
||||
|
||||

|
||||
25
src/content/posts/Java/集合/HashMap和ConcurrentHashMap的区别.md
Normal file
25
src/content/posts/Java/集合/HashMap和ConcurrentHashMap的区别.md
Normal file
@@ -0,0 +1,25 @@
|
||||
---
|
||||
title: HashMap和ConcurrentHashMap的区别
|
||||
published: 2025-08-11
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [ConcurrentHashMap,Java]
|
||||
category: 'Java > 集合框架'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# JDK1.7版本
|
||||
- 内存结构: HashMap采用数组+链表的结构,数组是HashMap的主体,链表用于解决哈希冲突。当两个不同的键通过哈希函数计算得到相同的索引时,它们会被存储在同一个数组位置的链表中。ConcurrentHashMap在JDK1.7中采用了分段锁的机制,内部是一个Segment数组,每个Segment类似一个小的HashMap,有自己的数组和链表。
|
||||
|
||||
- 线程安全性: HashMap不是线程安全的,在多线程环境下,如果多个线程同时对HashMap进行读写操作,可能会导致数据不一致,死循环的问题。ConcurrentHashMap是线程安全的,它通过分段锁的机制来保证并发访问时的线程安全。只有当多个线程访问同一个Segment时,才会发生锁竞争,从而提高了并发性能。
|
||||
|
||||
- 性能: hashmap由于没有锁的开销,所以在单线程环境下性能较好,但是在多线程环境下,为了保证线程安全,需要额外的同步机制,这回降低性能。但是ConcurrentHashMap通过分段所机制,在多线程环境下可以实现更高的并发性能,不同的线程可以同时访问不同的Segment,从而减少了锁竞争的可能性。
|
||||
|
||||
|
||||
# JDK1.8版本
|
||||
内存结构: hashMap引入了红黑树,从Jdk1.8开始,hashmap采用数组+ 链表+ 红黑树的结构。当链表长度超过一定阈值(8)的时候,链表会转换为红黑树,小于6的时候会转换为链表,以提高查找效率。ConcurrentHashMap放弃了分段锁机制,采用`CAS + synchronized`的方式保证线程安全,内部结构和HashMap一样,也引入了红黑树,是数组+ 链表+ 红黑树的结构。
|
||||
|
||||
线程安全性: ConcurrentHashMap通过CAS和synchronized的方式保证线程安全。在插入元素的时候,首先会尝试用CAS更新节点,如果CAS失败,则使用synchronized锁住当前节点,再进行插入操作。
|
||||
|
||||
性能: hashmap在单线程环境下,由于红黑树的引入,当链表较长的时候查找效率会有所提升。ConcurrentHashMap在多线程环境下,由于摒弃了分段锁,减少了锁的粒度,进一步提高了并发性能。同时,红黑树的引入也提高了查找效率。
|
||||
40
src/content/posts/Java/集合/JavaHashMap为什么在jdk8引入红黑树.md
Normal file
40
src/content/posts/Java/集合/JavaHashMap为什么在jdk8引入红黑树.md
Normal file
@@ -0,0 +1,40 @@
|
||||
---
|
||||
title: Java HashMap为什么在jdk8引入红黑树
|
||||
published: 2025-08-05
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['红黑树','HashMap']
|
||||
category: 'Java > 集合框架'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
# Java HashMap为什么在jdk8引入红黑树
|
||||
|
||||
在JDK8之前,HashMap的内部实现主要依赖于数组+链表的结构
|
||||
当多个元素的哈希值相同的时候(也就是发生哈希冲突的时候),这些元素会被存储在同一个桶里面,形成一个链表。
|
||||
但这种实现方式在特定情况下会导致性能问题。
|
||||
|
||||
# JDK8之前的问题
|
||||
|
||||
1. 时间复杂度退化: 在最坏情况下(大量元素哈希到同一个桶),查找,插入和删除操作的时间复杂度会从理想的O(1)退化为O(n),其中n是链表的长度
|
||||
2. 哈希冲突攻击: 恶意攻击者可以构造大量哈希冲突的数据,使得HashMap的性能急剧下降,导致潜在的拒接服务攻击。
|
||||
|
||||
# 红黑树的引入
|
||||
JDK8对HashMap进行了优化,引入了红黑树来解决上面的问题:
|
||||
- 性能提升: 当一个桶中的元素数量超过一定阈值的时候,链表会被转换成红黑树。红黑树是一种自平衡的二叉搜索树,即使在最坏的情况下,它查找,插入和删除操作的时间复杂度也能保持在O(logn),大大提高了性能。
|
||||
|
||||
- 阈值机制:
|
||||
- 当桶中元素超过8个的时候,链表转换为红黑树
|
||||
- 当桶中元素少于6个的时候,红黑树会退化回链表
|
||||
|
||||
- 安全性增强: 通过引入红黑树,即使面对哈希冲突的攻击,HashMap也能保持相对稳定的性能,提高系统安全性
|
||||
|
||||
|
||||
# 为什么选择红黑树
|
||||
平衡性: 红黑树是一种近似平衡的二叉搜索树,能保证最坏情况下的O(logn)的性能。
|
||||
|
||||
内存占用: 相比AVL树等其它平衡树,红黑树的平衡条件较为宽松,旋转操作更少,内存占用更小。
|
||||
|
||||
实现更好的复杂度与性能平衡
|
||||
14
src/content/posts/Java/集合/Java迭代器Iterator和Iterable.md
Normal file
14
src/content/posts/Java/集合/Java迭代器Iterator和Iterable.md
Normal file
@@ -0,0 +1,14 @@
|
||||
---
|
||||
title: Java迭代器Iterator和Iterable
|
||||
published: 2025-08-05
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [Iterator,Iterable]
|
||||
category: 'Java > 集合框架'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# Java迭代器Iterator和Iterable
|
||||
|
||||
|
||||
69
src/content/posts/Java/集合/concurrenthashmap的实现原理.md
Normal file
69
src/content/posts/Java/集合/concurrenthashmap的实现原理.md
Normal file
@@ -0,0 +1,69 @@
|
||||
---
|
||||
title: concurrenthashmap的实现原理
|
||||
published: 2025-08-06
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [ConcurrentHashMap,Java]
|
||||
category: 'Java > 集合框架'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
# ConcurrentHashMap实现原理
|
||||
|
||||
ConcurrentHashMap是Java并发包中一种线程安全的哈希表实现。
|
||||
HashMap在多线程环境下扩容会出现CPU接近100%的情况,因为HashMap并不是线程安全的,我们可以通过Collections里面的Map<K,V> synchronizedMap(Map<K,V> m) 把HashMap包装成一个线程安全的map
|
||||
|
||||
比如SynchronizedMap的put方法就是加锁过的
|
||||
|
||||
|
||||
# ConcurrentHashMap的变化
|
||||
ConcurrentHashMap在JDK1.7中,提供了一种粒度更细的加锁机制,这种机制叫分段锁,整个哈希表被分为多个段,每个段都独立锁定。读取操作不需要锁,写入操作仅锁定相关的段,这减小了锁冲突的几率,提高了并发性能。
|
||||
|
||||
这种机制的优点是: 在并发环境下将实现更高的吞吐量,在单线程环境下只损失非常小的性能。
|
||||
|
||||
可以这样理解分段锁,就是将数据分段,对每一段数据分配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
|
||||
|
||||
有些方法需要跨段,比如size(),isEmpty(),containsValue(),它们可能需要锁定整个表而不仅仅是某个段,这需要按顺序锁定所有段,操作完以后,再按顺序释放所有段的锁。
|
||||
|
||||
|
||||
ConcurrentHashMap是由Segment数组结构和HashEntry构成的,Segment是一种可重入的锁,HashEntry则用于存储键值对数据。
|
||||
|
||||
一个ConcurrentHashMap里面包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构,一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当HashEntry数组的数据进行修改的时候,必须首先获得它对应的Segment锁。
|
||||
|
||||
在外部:有一个 Segment 数组,作为并发控制的“总入口”,每个 Segment 都是一个独立的锁喵~
|
||||
在内部:每个 Segment 自己就是一个完整的小型 HashMap!它有自己的哈希表数组,里面的每个桶都可以通过 next 指针挂着一个或多个 Entry 组成的链表.
|
||||
|
||||
|
||||
|
||||
# ConcurrentHashMap 读写过程
|
||||
|
||||
## get方法
|
||||
- 为输入的key做hash运算,得到hash值
|
||||
- 通过Hash值,定位到对应的Segment对象
|
||||
- 再次通过hash值,定位到Segment当中数组的具体位置
|
||||
|
||||
|
||||
## put方法
|
||||
- 为输入的key做hash运算,得到hash值
|
||||
- 通过hash值,定位到对应的Segment对象
|
||||
- 获取可重入锁
|
||||
- 再次通过hash值,定位到Segment当中数组的具体位置
|
||||
- 插入或者覆盖HashEntry对象
|
||||
- 释放锁
|
||||
|
||||
|
||||
# JDK1.8
|
||||
在JDK1.8中,ConcurrentHashMap主要做了两个优化:
|
||||
- 和HashMap一样,链表也会在长度到达8的时候转换为红黑树,这样可以提升大量冲突的时候的查询效率。
|
||||
- 以某个位置的头结点为锁,配合自旋 + CAS 避免不必要的锁开销,进一步提升并发性能。
|
||||
- 相比JDK1.7中的ConcurrentHashMap,JDK1.8的ConcurrentHashMap取消了Segment分段锁,采用CAS + synchronized来保证并发安全性。整个容器只分为一个Segment,也就是table数组。
|
||||
- JDK1.8中的ConcurrentHashMap对节点Node类中的共享变量,和JDK1.7一样,使用volatile关键字,保证多线程操作的时候,变量的可见性。
|
||||
|
||||
|
||||
# ConcurrentHashMap的字段
|
||||
1. table
|
||||
这个装载Node的数组,作为ConcurrentHashMap的底层容器,采用加载的方式,直到第一次插入数据的时候才会进行初始化操作
|
||||
数组的大小是2的幂次方。
|
||||
|
||||
105
src/content/posts/中间件/MySQL/MVCC.md
Normal file
105
src/content/posts/中间件/MySQL/MVCC.md
Normal file
@@ -0,0 +1,105 @@
|
||||
---
|
||||
title: MVCC-多版本并发控制
|
||||
published: 2025-08-09
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [MVCC]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
# MVCC
|
||||
MVCC,也就是多版本并发控制
|
||||
|
||||
它的目的是: 提高数据库并发性能,用更好的方式处理读写冲突,也就是即使有读写冲突的时候,也能做到不加锁。
|
||||
|
||||
|
||||
## 并发控制的挑战
|
||||
在数据库系统中,同时执行的事务可能涉及相同的数据,因此需要一种机制来保证数据的一致性,传统的锁机制可以实现并发控制,但会导致阻塞和死锁等问题。
|
||||
|
||||
## 传统锁机制
|
||||
|
||||
|
||||
## 当前读和快照读
|
||||
|
||||
### 当前读
|
||||
在MySQL中,当前读是一种读取数据的操作方式,它可以直接读取最新的数据版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁,MySQL提供了两种实现当前读的机制:
|
||||
|
||||
- 锁定读:
|
||||
- 锁定读是一种特殊情况下的当前读方式,在某些场景下使用
|
||||
- 在使用锁定读的时候,MySQL会在执行读取操作前获取共享锁或者排他锁,确保数据一致性。
|
||||
- 共享锁允许多个事务读取统一数据,而排他锁组织其他事务读取或者写入该数据。
|
||||
- 锁定读适用于需要严格控制并发访问的场景,但是由于加锁带来的性能开销较大,所以只在必要的时候才使用。
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
这种就属于悲观锁实现。
|
||||
|
||||
### 快照读
|
||||
快照读就是在读取数据的时候,读取一个一致性视图中的数据,MySQL通过MVCC机制来支持快照读。
|
||||
|
||||
具体而言,每个食物在开始的时候都会创建一个一致性视图,这个一致性视图会记录当前事务开始时已经提交的数据版本。
|
||||
|
||||
执行查询的时候,MySQL会根据事务的一致性视图来决定可见的数据版本。只有那些在事务开始之前就已经提交的数据版本才是可见的,未提交或在事务开始后修改的数据则对当前事务不可见。
|
||||
|
||||
像不加锁的select操作就是快照读,也就是不加锁的非阻塞读。
|
||||
|
||||
|
||||
- 一致性读:
|
||||
- 默认隔离级别下(可重复读),MySQL使用一致性来实现当前读
|
||||
- 在事务开始的时候,MySQL会创建一个一致性视图,这个视图反映了事务开始时刻的数据库快照。
|
||||
- 在事务执行期间,无论其他事务对数据进行了何种修改,事务始终使用一致性视图来读取数据。
|
||||
- 可以保证在同一事务内多次查询返回的结果是一致的.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
快照读的前提是隔离级别不是串行级别,在串行级别下,事务之间完全串行执行,快照读会退化为当前读中的加锁读。
|
||||
|
||||
MVCC主要就是为了实现读-写冲突不加锁,这个读就是指的快照读,是乐观锁的实现。
|
||||
|
||||
|
||||
# 事务的mvcc机制原理是什么?
|
||||
MVCC允许多个事务同时读取同一行数据,而不会彼此阻塞,每个事务看到的数据版本是该事务开始时候的数据版本,这意味着,如果其他事务在此期间修改了数据,正在运行的事务仍然看到的是它开始时候的数据状态,从而实现了非阻塞读操作。
|
||||
|
||||
|
||||
对于 `读已提交` 和 `可重复读` 隔离级别的事务来说,它们是通过ReadView来实现的,它们的区别在于创建ReadView的时机不同。
|
||||
ReadView可以理解为当时的一个快照视图,它记录了在创建时刻可见的数据版本。
|
||||
|
||||
|
||||
读提交隔离级别: 在每个select语句执行前,都会重新生成一个ReadView。每个SELECT生成新的ReadView
|
||||
只能读到其他事务已提交的版本
|
||||
不能读到未提交事务的修改
|
||||
这保证了不会出现"脏读"
|
||||
但会出现"不可重复读"
|
||||
|
||||
可重复读隔离级别: 在事务中,执行第一条select语句的时候,生成一个ReadView,然后整个事务期间都在使用这个ReadView
|
||||
|
||||
ReadView有四个重要字段:
|
||||
- creator_trx_id 创建该Read View的事务的事务id
|
||||
- m_ids 创建ReadView的时候,当前数据库中活跃且未提交的事务id列表,所谓活跃事务,指的就是启动了但是还没提交的事务
|
||||
- min_trx_id 创建ReadView的时候当前数据库中活跃且未提交的事务中最小的事务的事务id
|
||||
- max_trx_id 创建ReadView的时候,当前数据库中应该给下一个事务的id值,也就是全局事务中最大的事务id + 1
|
||||
|
||||
对于使用InnoDB存储引擎的数据库表,它的聚簇索引记录中都包含下面两个隐藏列
|
||||
- trx_id 记录最后修改该行数据的事务的事务id
|
||||
- roll_pointer 记录该行数据的回滚指针,用于实现MVCC(也就是undo日志)
|
||||
|
||||
每次对某条聚簇索引记录进行改动的时候,都会把旧版本的记录写入到undo日志中,然后这个隐藏列是个指针,指向每个旧版本记录,于是就可以通过它找到修改前的记录。
|
||||
|
||||
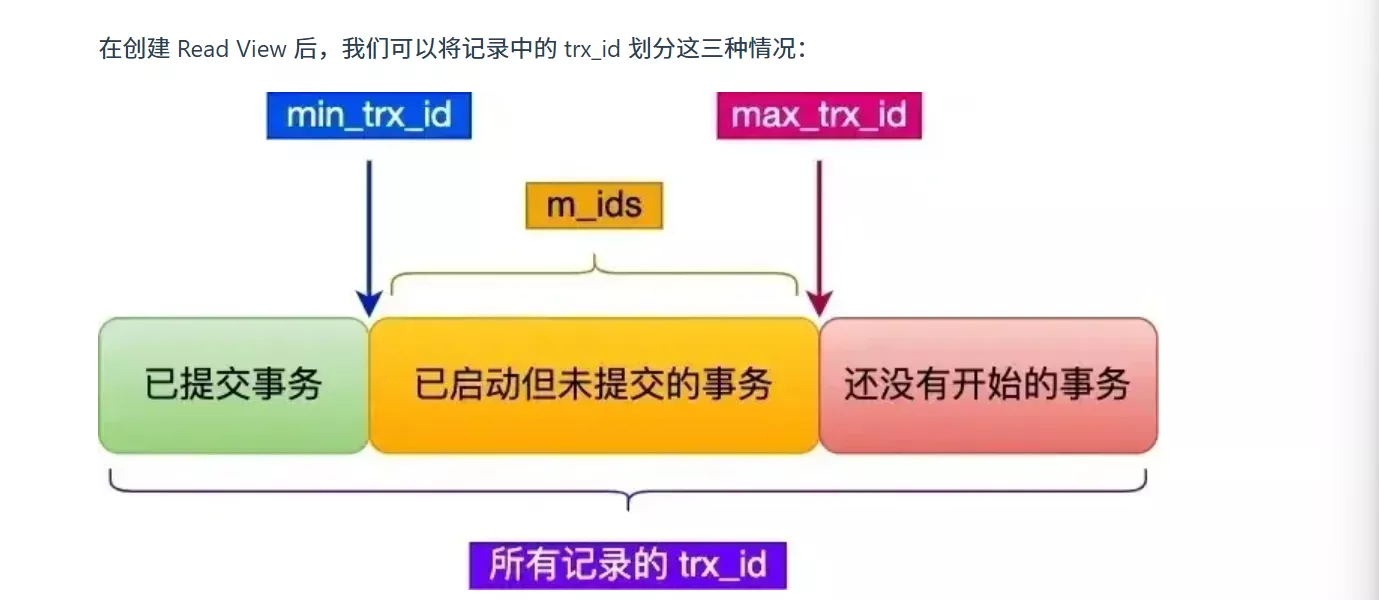
|
||||
|
||||
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
|
||||
|
||||
如果记录的 trx_id 值小于 Read View 中的 min_trx_id 值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。
|
||||
如果记录的 trx_id 值大于等于 Read View 中的 max_trx_id 值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。
|
||||
如果记录的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间,需要判断 trx_id 是否在 m_ids 列表中:
|
||||
如果记录的 trx_id 在 m_ids 列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。
|
||||
如果记录的 trx_id 不在 m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
|
||||
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
|
||||
59
src/content/posts/中间件/MySQL/MySQL-VARCHAR支持的最大长度.md
Normal file
59
src/content/posts/中间件/MySQL/MySQL-VARCHAR支持的最大长度.md
Normal file
@@ -0,0 +1,59 @@
|
||||
---
|
||||
title: MySQL-VARCHAR支持的最大长度
|
||||
published: 2025-09-07
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['MySQL', 'VARCHAR']
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
MySQL中,最大行长度限制为65535字节,如果一行中仅仅有一个varchar字段,它的最大长度是多少呢?
|
||||
(InnoDB/MyISAM 中一行最大长度限制是 65535 字节(65 KB 左右)。)
|
||||
长度> 255,存储varchar长度需要2字节,长度<255,存储varchar长度需要1字节。
|
||||
|
||||
所以
|
||||
- 当长度>255且非空的时候,可以存储65535 - 2 = 65533 字节。
|
||||
- 当长度>255且可以为空的时候,可以存储65535 - 2 - 1(存储NULL标志) = 65532字节。
|
||||
- 当长度<255且非空的时候,可以存储65535 - 1 = 65534 字节。
|
||||
- 当长度<255且可以为空的时候,可以存储65535 - 1 - 1(存储NULL标志) = 65533字节。
|
||||
|
||||
如果只有一个 VARCHAR 字段
|
||||
|
||||
假设表里只有这一列:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t (
|
||||
v VARCHAR(N)
|
||||
) ENGINE=InnoDB;
|
||||
```
|
||||
|
||||
行最大长度:65535 字节。
|
||||
|
||||
除了数据外,还有:
|
||||
|
||||
NULL 标志位(至少 1 字节,即使只有一列)。
|
||||
|
||||
VARCHAR 长度字节(1 或 2)。
|
||||
|
||||
所以最大能用来存储 v 的 = 65535 - 1 (NULL 标志) - 2 (长度字节) = 65532 字节。
|
||||
|
||||
因此:
|
||||
|
||||
✅ 单列 VARCHAR 最大可定义为 VARCHAR(65532)
|
||||
|
||||
|
||||
> 如果是非null,就不需要占用那一字节null标志位了
|
||||
```sql
|
||||
CREATE TABLE t (
|
||||
v VARCHAR(N) NOT NULL
|
||||
) ENGINE=InnoDB;
|
||||
```
|
||||
|
||||
这里N就可以是65533了
|
||||
|
||||
|
||||
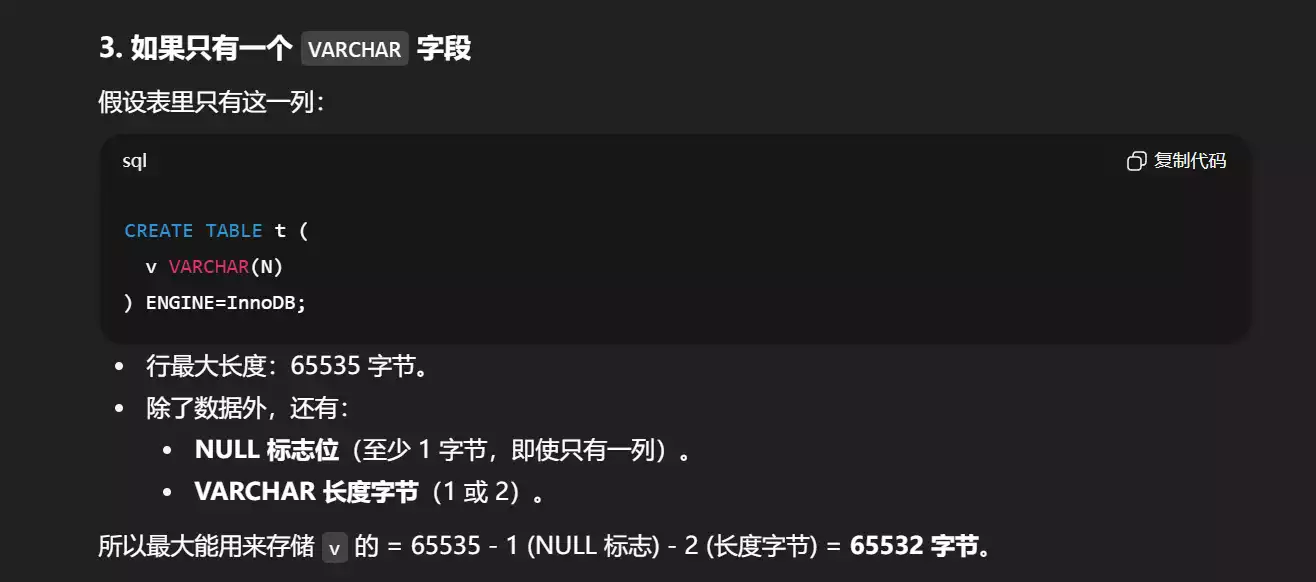
|
||||
|
||||
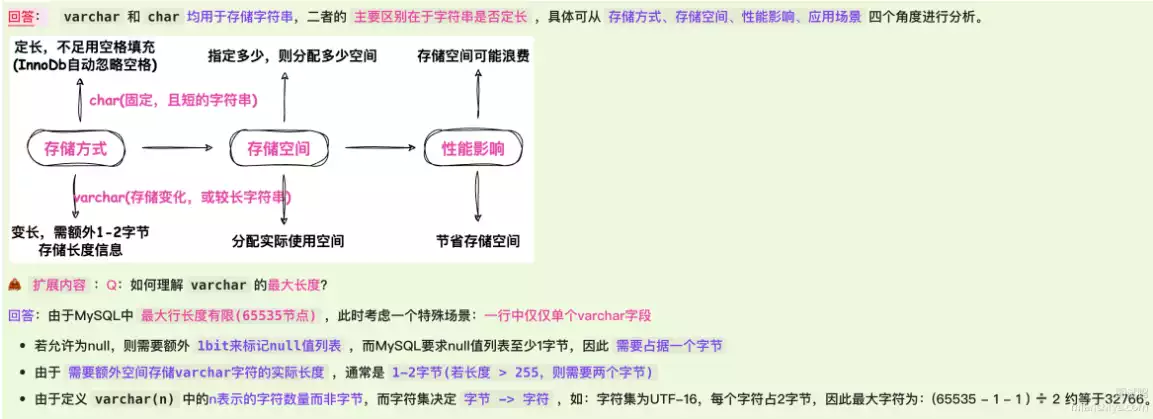
|
||||
39
src/content/posts/中间件/MySQL/MySQL-binlog.md
Normal file
39
src/content/posts/中间件/MySQL/MySQL-binlog.md
Normal file
@@ -0,0 +1,39 @@
|
||||
---
|
||||
title: MySQL-binlog
|
||||
published: 2025-09-16
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [MYSQL,binlog,MySQL]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
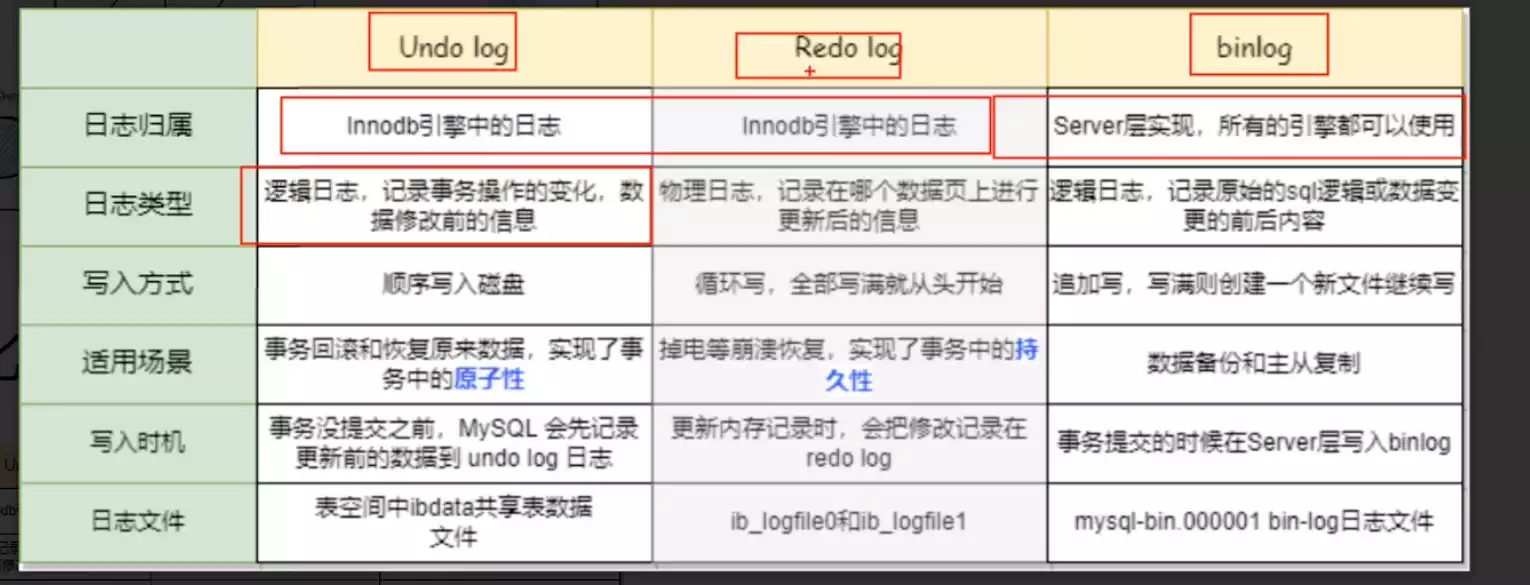
|
||||
# binlog(二进制日志)
|
||||
二进制日志主要用于记录所有针对数据库表结构的变更
|
||||
以及对表数据的修改操作,不包括SELECT,SHOW等读取类的操作。
|
||||
Binlog是在事务提交成功以后,在服务层生成的日志文件
|
||||
|
||||
作用:
|
||||
1. 数据恢复: 通过详尽的记录所有影响数据状态的SQL命令,binlog为从特定时间点或者由于意外操作导致的数据丢失提供了恢复手段。一旦发生数据损坏或者丢失事件,可以通过重放binlog中的历史更改来恢复到先前的状态。
|
||||
2. 主从复制: 对于需要跨多台服务器实现数据备份的应用场景,binlog提供了基础。通过将主服务器的binlog传输到从服务器,从服务器可以重放这些日志以实现数据的同步。
|
||||
|
||||
# binlog格式类型
|
||||
MySQL支持三种类型的binlog格式:
|
||||
`STATEMENT`,`ROW`和`MIXED `
|
||||
|
||||
- STATEMENT模式: 在这个模式下,每一条引起数据变化的SQL语句都会被记录下来。这种方式的优点在于减少了日志大小并且提高了处理速度。
|
||||
然而,如果使用了SYSDATE(),NOW()之类的非确定性函数,就有可能导致在执行数据恢复或主从复制过程中产生一致性问题。
|
||||
|
||||
- ROW模式: 与记录整个SQL不同,ROW模式仅追踪实际受到影响的数据行的变化情况。这种方法避免了STATEMENT模式下的动态内容带来的挑战,但是代价是增加了日志文件的体积
|
||||
|
||||
- MIXED模式: 前两者的折中方案。根据具体情况自动选择最合适的记录方式。当系统认为STATEMENT更优的时候,使用STATEMENT模式;当系统认为ROW更优的时候,使用ROW模式。
|
||||
|
||||
|
||||
# 记录方式
|
||||

|
||||
|
||||
# 主从复制
|
||||
|
||||
|
||||
39
src/content/posts/中间件/MySQL/MySQL-redolog.md
Normal file
39
src/content/posts/中间件/MySQL/MySQL-redolog.md
Normal file
@@ -0,0 +1,39 @@
|
||||
---
|
||||
title: MySQL-redolog
|
||||
published: 2025-09-16
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [MYSQL,redolog,MySQL]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||

|
||||
# Redo Log(实现持久化)
|
||||
在InnoDB存储引擎中,大部分Redo Log记录的是物理日志,也就是对特定数据页进行的具体修改。
|
||||
那么为啥要称呼它为大部分是物理日志呢?是因为Redo Log系统由两部分构成:
|
||||
- 一是位于内存中的重做日志缓冲区(redolog buffer),这部分信息容易因为断电等原因丢失。
|
||||
- 二是保存于磁盘上的重做日志文件(redolog file)提供持久化存储
|
||||
|
||||
## 引入redo log的必要性
|
||||
尽管buffer pool确实极大提升了数据库操作的性能,但是由于它基于内存的特点,存在着固有的不稳定性,一旦发生系统崩溃或断电等故障,内存中的数据就可能会丢失。为了避免这种情况,Redo Log应运而生。
|
||||
通过与buffer pool和change buffer协同工作,redolog负责记录所有尚未同步到磁盘的更改操作,确保即使发生故障重启以后也能恢复这些更新,直到相关页面被最终安全地写入到磁盘为止。
|
||||
|
||||

|
||||
|
||||
## redo log和undo log之间的差异
|
||||
|
||||
- Redo Log专注于 记录事务完成后的新状态,也就是变更后的值
|
||||
- Undo Log用来追踪事务开始前的原始状态,保存的是变更前的旧值
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
## 崩溃恢复
|
||||

|
||||
21
src/content/posts/中间件/MySQL/MySQL-relaylog.md
Normal file
21
src/content/posts/中间件/MySQL/MySQL-relaylog.md
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
title: MySQL-relaylog(中继日志)
|
||||
published: 2025-09-16
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [MYSQL,relaylog,MySQL]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# Relay Log(中继日志)
|
||||
|
||||
中继日志(relay log)只在主从服务器架构的从服务器上存在。从服务器(slave)为了与主服务器(Master)保持一致,要从主服务器读取二进制日志的内容,并且把读取到的信息写入本地的日志文件中,这个从服务器本地的日志文件就叫中继日志。然后,从服务器读取中继日志,并根据中继日志的内容对从服务器的数据进行更新,完成主从服务器的数据同步。
|
||||
|
||||
搭建好主从服务器之后,中继日志默认会保存在从服务器的数据目录下。
|
||||
|
||||
文件名的格式是:从服务器名 - relay-bin.序号。中继日志还有一个索引文件:从服务器名 - relay-bin.index,用来定位当前正在使用的中继日志。
|
||||
|
||||

|
||||
|
||||
|
||||
35
src/content/posts/中间件/MySQL/MySQL-undolog.md
Normal file
35
src/content/posts/中间件/MySQL/MySQL-undolog.md
Normal file
@@ -0,0 +1,35 @@
|
||||
---
|
||||
title: MySQL-undolog(回滚日志)
|
||||
published: 2025-09-16
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [MYSQL,undolog,MySQL]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||

|
||||
# 回滚日志 Undo Log
|
||||
|
||||
回滚日志是数据库引擎层生成的一种日志,主要用于确保事务的ACID特性中的`原子性`。它记录的是逻辑操作,也就是**数据在被修改之前的状态。**
|
||||
这些逻辑操作包括 插入,删除和更新
|
||||
|
||||
## 主要功能
|
||||
1. 事务回滚: 当事务需要回滚的时候,通过执行undo log记录的逆向操作来恢复到事务开始前的数据状态
|
||||
2. 多版本并发控制 MVCC: 结合ReadView机制,利用undo log实现多版本并发控制,从而支持高并发读写操作
|
||||
|
||||
## 记录内容
|
||||
|
||||
|
||||
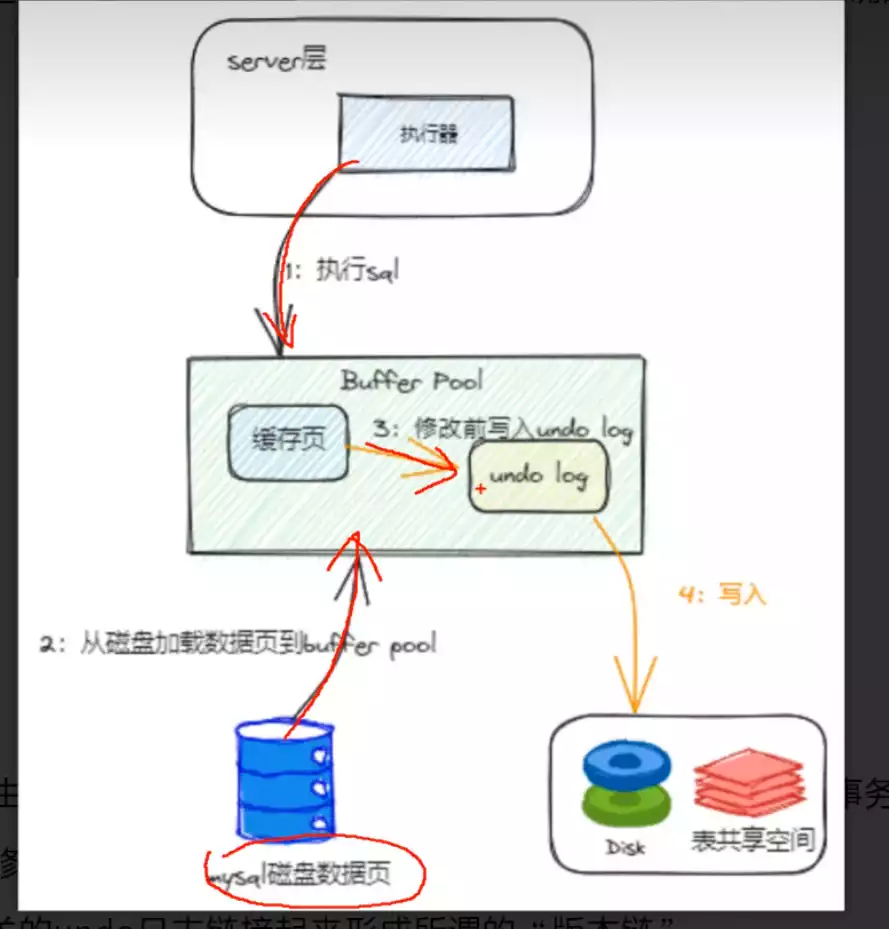
|
||||
|
||||
## 事务回滚
|
||||
每条记录在进行更新操作的时候,产生的undo日志都包含一个roll_pointer指针和一个trx_id事务标识符。
|
||||
- trx_id用于识别对特定记录执行修改的操作的具体事务
|
||||
- roll_pointer 则允许把一系列相关的undolog日志链接起来形成所谓的**版本链**
|
||||
|
||||
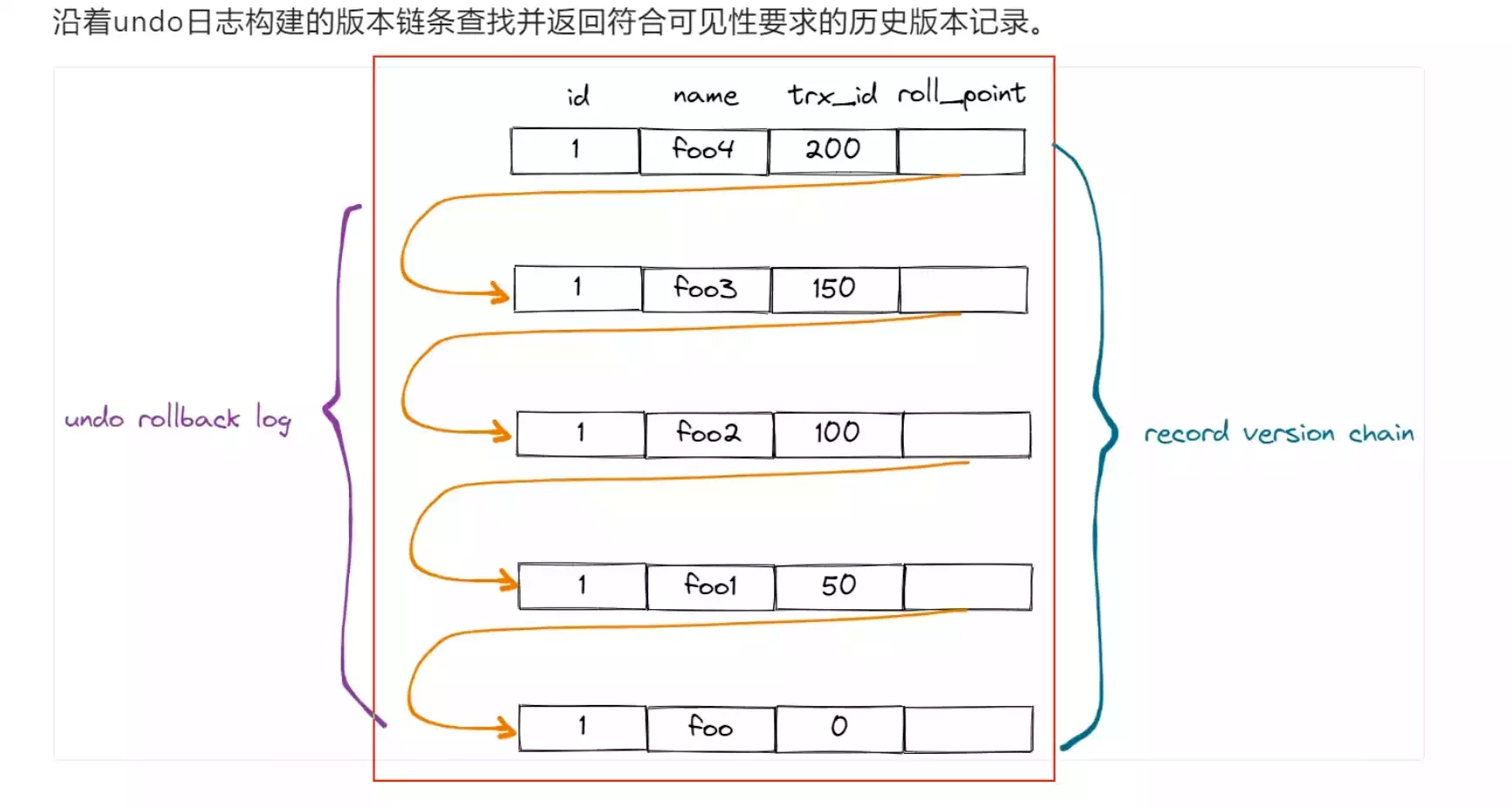
|
||||
|
||||
当某一个事务需要回滚的时候,并不是通过逆向执行SQL语句来恢复数据状态的,而是依据事务中roll_pointer指向的undolog日志条目来进行数据复原。
|
||||
|
||||

|
||||
42
src/content/posts/中间件/MySQL/MySQLbinlog,redolog和undolog.md
Normal file
42
src/content/posts/中间件/MySQL/MySQLbinlog,redolog和undolog.md
Normal file
@@ -0,0 +1,42 @@
|
||||
---
|
||||
title: MySQLbinlog,redolog和undolog
|
||||
published: 2025-08-09
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [MySQL, binlog, redolog, undolog]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# MySQL的binlog、redolog和undolog详解
|
||||

|
||||
|
||||
## binlog
|
||||
binlog
|
||||
用途:
|
||||
1. 主从复制
|
||||
2. 数据恢复
|
||||
3. 审计
|
||||
|
||||
## redolog(保证持久性)
|
||||
redo log
|
||||
目的: 确保事务的持久性
|
||||
作用: 记录了数据被修改之后的值。当事务提交以后,即使数据还没有完全写入磁盘,只要redo log已经落盘,数据库在发生宕机等意外情况之后,仍然可以通过redo log来'重做'这些修改,从而恢复到宕机前的最新状态,保证了已提交事务的数据不可丢失,这是一种前滚操作。
|
||||
|
||||
|
||||
## undolog(保证原子性)
|
||||
|
||||
目的: 保证事务的原子性和实现多版本并发控制。
|
||||
作用: 记录的是数据被修改之前的旧版本。当一个事务需要回滚的时候,数据库可以利用undo log中的信息将数据恢复到事务开始前的状态。
|
||||
|
||||

|
||||
|
||||
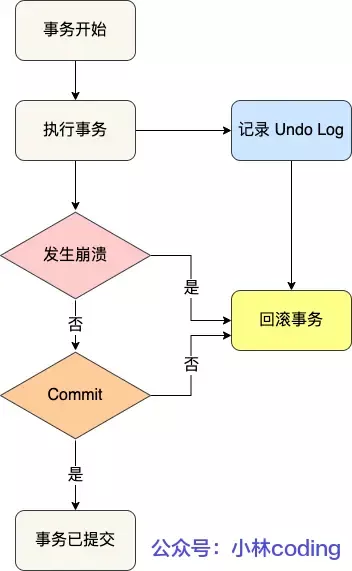
|
||||
|
||||
|
||||
|
||||
# 区别
|
||||

|
||||
|
||||

|
||||
21
src/content/posts/中间件/MySQL/MySQL中CHAR和VARCHAR的区别.md
Normal file
21
src/content/posts/中间件/MySQL/MySQL中CHAR和VARCHAR的区别.md
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
title: MySQL中CHAR和VARCHAR的区别
|
||||
published: 2025-09-07
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['MySQL', 'CHAR', 'VARCHAR']
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||

|
||||
|
||||
# CHAR(n)
|
||||
char(n) 是固定长度的字符串,CHAR列的长度是固定的,即使存储的字符串长度小于定义的长度,MySQL也会在字符串的末尾填充空格以达到指定的长度。
|
||||
|
||||
# VARCHAR(n)
|
||||
可变长度的字符串,varchar列的长度是可变的,存储的字符串长度与实际数据长度相等,并且在存储数据的时候会额外增加1到2个字节(字符串长度超过255,就用两个字节) 用于存储字符串的长度信息。
|
||||
|
||||
理论上char比varchar会快,因为varchar长度不固定,处理需要多一次运算,但是实际上这种运算耗时微乎其微,而固定大小在很多场景下比较浪费空间,除非存储的字符确认是固定大小或者本身就很短,不然业务上推荐使用varchar.
|
||||
|
||||
22
src/content/posts/中间件/MySQL/MySQL中几种count的区别.md
Normal file
22
src/content/posts/中间件/MySQL/MySQL中几种count的区别.md
Normal file
@@ -0,0 +1,22 @@
|
||||
---
|
||||
title: MySQL中几种count的区别
|
||||
published: 2025-09-07
|
||||
description: "MySQL中count(*),count(1)和count(字段名)的区别"
|
||||
image: ""
|
||||
tags: ["count", "MySQL"]
|
||||
category: "中间件 > MySQL"
|
||||
draft: false
|
||||
lang: ""
|
||||
---
|
||||
|
||||
# count(\*) 和 count(1)
|
||||
|
||||
是用来统计行数的聚合函数,统计表中的全部行的数量,包括 null 值
|
||||
|
||||
# count(字段名)
|
||||
|
||||
也是用来统计行数的聚合函数,会统计指定字段下不为 null 的行数,这种写法会对指定的字段进行计数,只会统计字段值不为 null 的行。
|
||||
|
||||

|
||||
|
||||
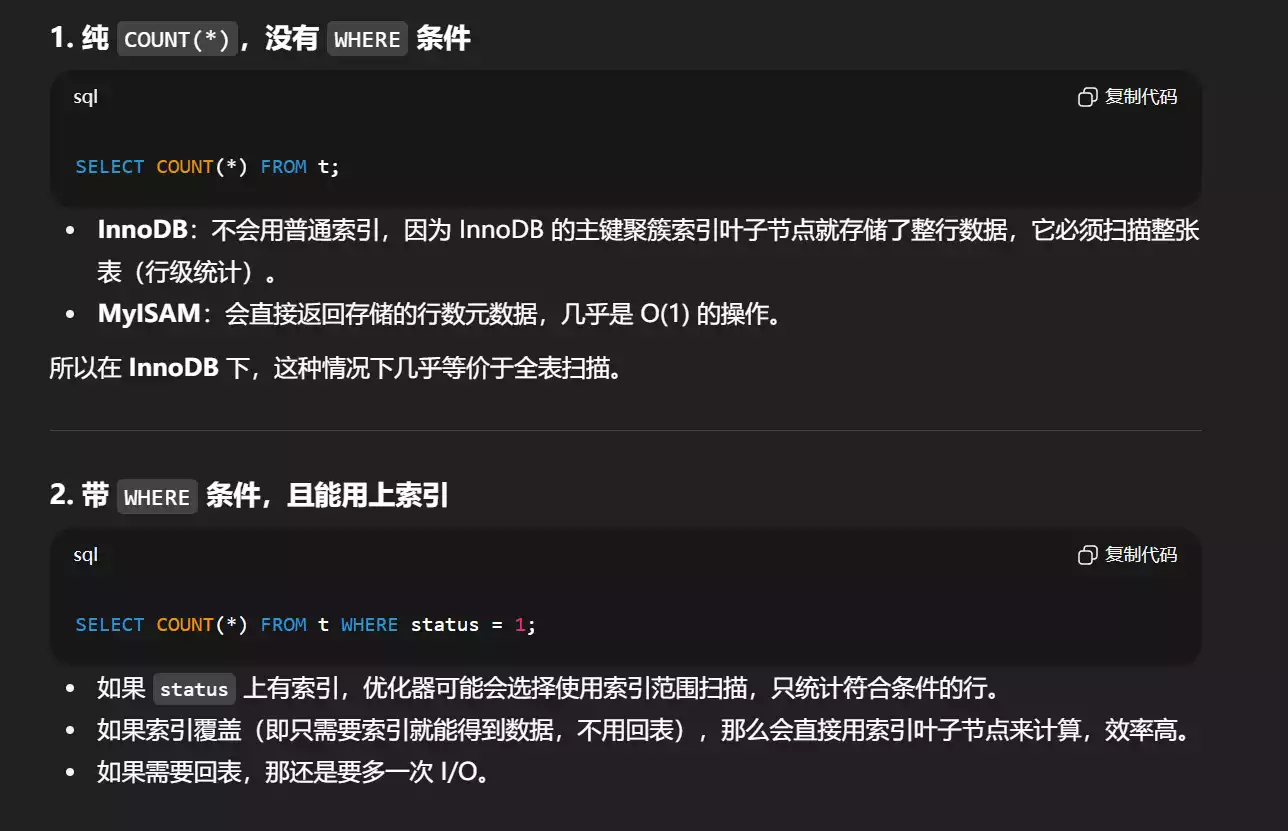
|
||||
238
src/content/posts/中间件/MySQL/MySQL中发生死锁如何解决.md
Normal file
238
src/content/posts/中间件/MySQL/MySQL中发生死锁如何解决.md
Normal file
@@ -0,0 +1,238 @@
|
||||
---
|
||||
title: MySQL中发生死锁如何解决
|
||||
published: 2025-09-08
|
||||
description: 'MySQL中发生死锁如何解决'
|
||||
image: ''
|
||||
tags: ['MySQL','死锁']
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
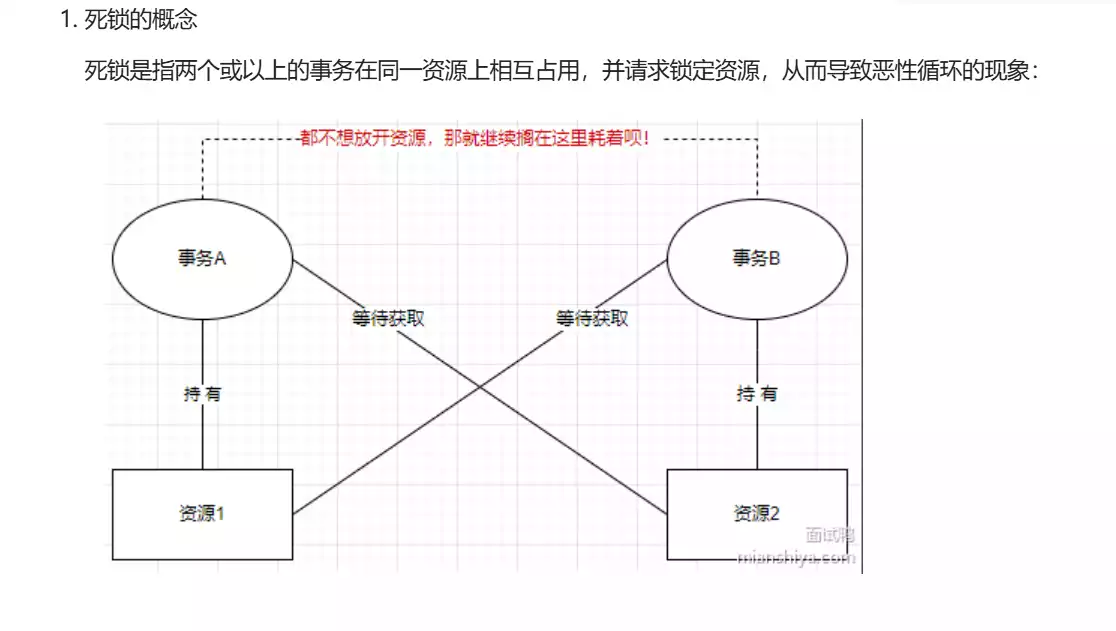
|
||||
|
||||
|
||||
|
||||
# 自动检测与回滚
|
||||
MySQL自带死锁检测机制(innodb_deadlock_detect),当检测到死锁的时候,数据库会自动回滚其中一个事务,以接触死锁,通常会回滚事务中持有最少资源的那个。
|
||||
|
||||
也有锁等待超时的参数(innodb_lock_wait_timeout),当锁等待超过这个时间后,MySQL会自动回滚。
|
||||
|
||||
# 手动kill发生死锁的语句
|
||||
可以通过命令,手动快速找出被阻塞的事务以及线程ID,然后手动Kill掉,及时释放资源。
|
||||
|
||||
# 常见降低/排除死锁出现情况的方法
|
||||
- 避免大事务: 大事务占据锁耗时长,可以把大事务拆分成多个小事务执行快速释放锁,可以降低死锁产生的概率和冲突
|
||||
- 调整申请锁的顺序: 在写操作的时候保证能获得足够范围的锁,如修改操作的时候先获取排他锁再获取共享锁,固定顺序访问数据
|
||||
- 更改数据隔离级别: 可重复读比读已提交多了间隙锁和临键锁,使用读已提交能降低死锁出现的情况。
|
||||
- 合理建立索引,减少加锁范围
|
||||
- 开启死锁检测,适当调整锁等待超时时间
|
||||
|
||||
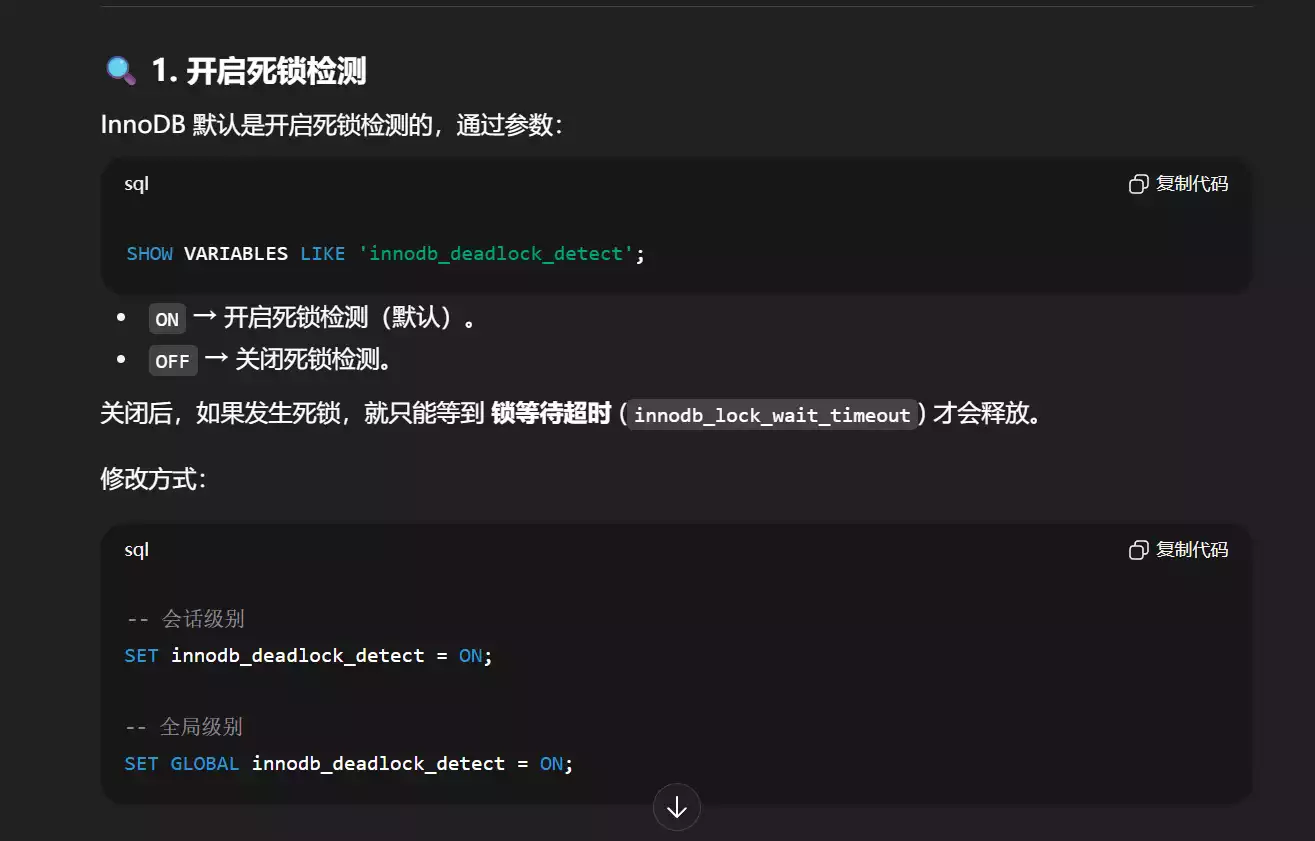
|
||||
|
||||
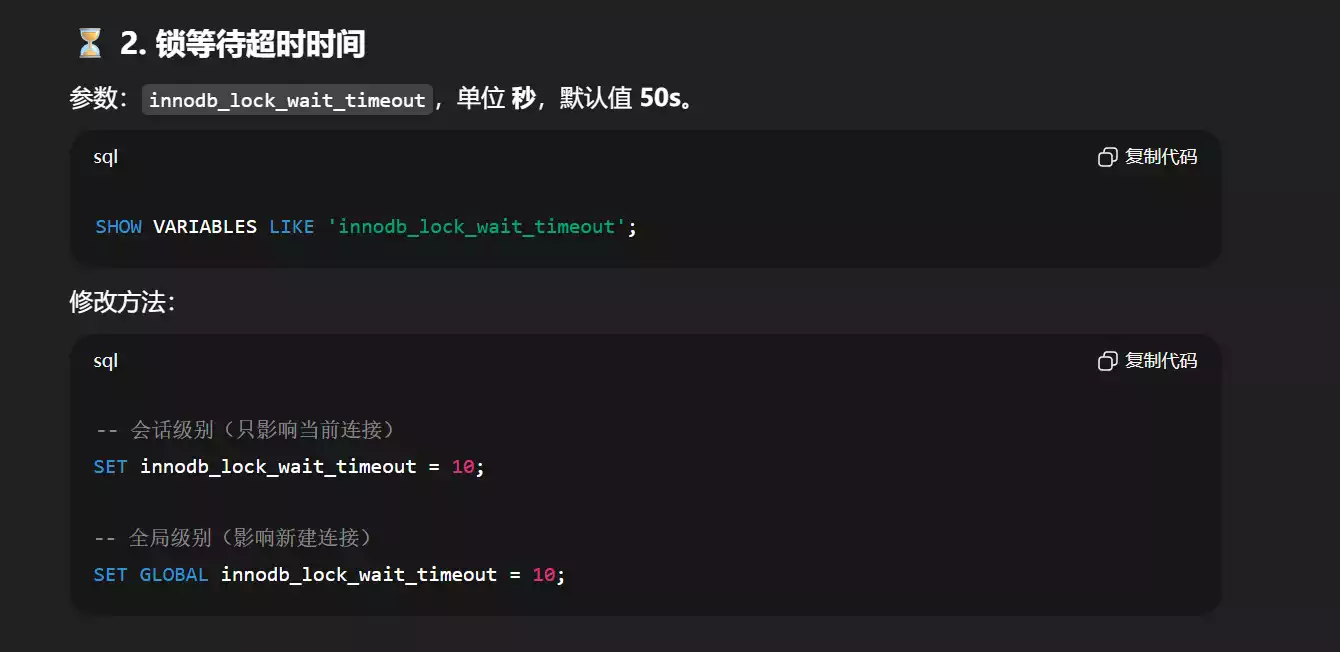
|
||||
|
||||
# 实际测试
|
||||
innodb_print_all_deadlocks:开启死锁打印
|
||||
```sql
|
||||
show VARIABLES like 'innodb_print_all_deadlocks';
|
||||
|
||||
set GLOBAL innodb_print_all_deadlocks = 1;
|
||||
|
||||
flush PRIVILEGES;
|
||||
|
||||
```
|
||||
|
||||
```sql
|
||||
|
||||
create table deadlock_test (
|
||||
id bigint not null,
|
||||
name varchar(255),
|
||||
primary key(id)
|
||||
);
|
||||
insert into deadlock_test values(1, 'zhangsan');
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
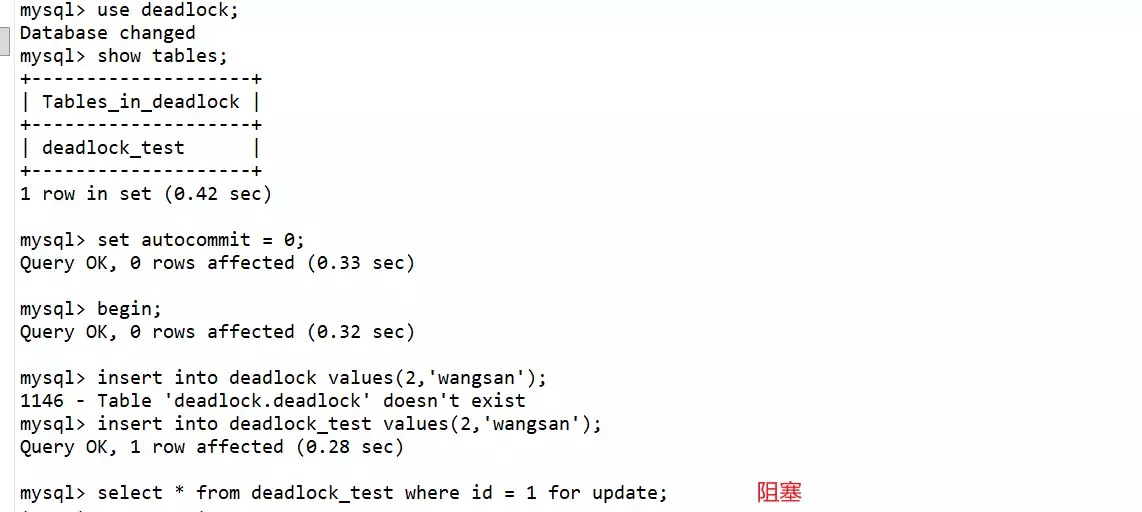
|
||||
|
||||
|
||||
```sql
|
||||
show engine innodb status;
|
||||
```
|
||||
|
||||
|
||||
经典“交叉持锁、互等”死锁:
|
||||
事务 (1) 当前语句是 select * from deadlock_test where id = 1 for update,日志显示它已持有 id=2 的记录锁,正等待获取 id=1 的锁。
|
||||
事务 (2) 当前语句是 select * from deadlock_test where id = 2 for update,日志显示它已持有 id=1 的记录锁,正等待获取 id=2 的锁。
|
||||
二者形成环:T1 持 id=2 等 id=1;T2 持 id=1 等 id=2。
|
||||
锁类型:lock_mode X locks rec but not gap 为记录级行锁(非 GAP 锁),锁定的是主键记录本身。
|
||||
仲裁结果:InnoDB 回滚了事务 (2)(“WE ROLL BACK TRANSACTION (2)”),说明它评估回滚成本更低(未必是开始时间靠后)。
|
||||
|
||||
```
|
||||
------------------------
|
||||
LATEST DETECTED DEADLOCK
|
||||
------------------------
|
||||
2025-09-08 14:25:29 138110019045056
|
||||
*** (1) TRANSACTION:
|
||||
TRANSACTION 48777, ACTIVE 96 sec starting index read
|
||||
mysql tables in use 1, locked 1
|
||||
LOCK WAIT 3 lock struct(s), heap size 1128, 2 row lock(s), undo log entries 1
|
||||
MySQL thread id 638, OS thread handle 138111594002112, query id 479129 10.0.0.8 root statistics
|
||||
select * from deadlock_test where id = 1 for update
|
||||
|
||||
*** (1) HOLDS THE LOCK(S):
|
||||
RECORD LOCKS space id 76 page no 4 n bits 72 index PRIMARY of table `deadlock`.`deadlock_test` trx id 48777 lock_mode X locks rec but not gap
|
||||
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
|
||||
0: len 8; hex 8000000000000002; asc ;;
|
||||
1: len 6; hex 00000000be89; asc ;;
|
||||
2: len 7; hex 82000001230110; asc # ;;
|
||||
3: len 7; hex 77616e6773616e; asc wangsan;;
|
||||
|
||||
|
||||
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
|
||||
RECORD LOCKS space id 76 page no 4 n bits 72 index PRIMARY of table `deadlock`.`deadlock_test` trx id 48777 lock_mode X locks rec but not gap waiting
|
||||
Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
|
||||
0: len 8; hex 8000000000000001; asc ;;
|
||||
1: len 6; hex 00000000be80; asc ;;
|
||||
2: len 7; hex 01000000be2b14; asc + ;;
|
||||
3: len 4; hex 6c697369; asc lisi;;
|
||||
|
||||
|
||||
*** (2) TRANSACTION:
|
||||
TRANSACTION 48768, ACTIVE 149 sec starting index read
|
||||
mysql tables in use 1, locked 1
|
||||
LOCK WAIT 3 lock struct(s), heap size 1128, 2 row lock(s), undo log entries 1
|
||||
MySQL thread id 636, OS thread handle 138111598196416, query id 479151 10.0.0.8 root statistics
|
||||
select * from deadlock_test where id = 2 for update
|
||||
|
||||
*** (2) HOLDS THE LOCK(S):
|
||||
RECORD LOCKS space id 76 page no 4 n bits 72 index PRIMARY of table `deadlock`.`deadlock_test` trx id 48768 lock_mode X locks rec but not gap
|
||||
Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
|
||||
0: len 8; hex 8000000000000001; asc ;;
|
||||
1: len 6; hex 00000000be80; asc ;;
|
||||
2: len 7; hex 01000000be2b14; asc + ;;
|
||||
3: len 4; hex 6c697369; asc lisi;;
|
||||
|
||||
|
||||
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
|
||||
RECORD LOCKS space id 76 page no 4 n bits 72 index PRIMARY of table `deadlock`.`deadlock_test` trx id 48768 lock_mode X locks rec but not gap waiting
|
||||
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
|
||||
0: len 8; hex 8000000000000002; asc ;;
|
||||
1: len 6; hex 00000000be89; asc ;;
|
||||
2: len 7; hex 82000001230110; asc # ;;
|
||||
3: len 7; hex 77616e6773616e; asc wangsan;;
|
||||
|
||||
*** WE ROLL BACK TRANSACTION (2)
|
||||
------------
|
||||
TRANSACTIONS
|
||||
------------
|
||||
Trx id counter 48783
|
||||
Purge done for trx's n:o < 48783 undo n:o < 0 state: running but idle
|
||||
History list length 1
|
||||
LIST OF TRANSACTIONS FOR EACH SESSION:
|
||||
---TRANSACTION 419586600079360, not started
|
||||
0 lock struct(s), heap size 1128, 0 row lock(s)
|
||||
---TRANSACTION 419586600080976, not started
|
||||
0 lock struct(s), heap size 1128, 0 row lock(s)
|
||||
---TRANSACTION 419586600080168, not started
|
||||
0 lock struct(s), heap size 1128, 0 row lock(s)
|
||||
---TRANSACTION 419586600078552, not started
|
||||
0 lock struct(s), heap size 1128, 0 row lock(s)
|
||||
---TRANSACTION 419586600077744, not started
|
||||
0 lock struct(s), heap size 1128, 0 row lock(s)
|
||||
---TRANSACTION 419586600076936, not started
|
||||
0 lock struct(s), heap size 1128, 0 row lock(s)
|
||||
---TRANSACTION 48777, ACTIVE 121 sec
|
||||
5 lock struct(s), heap size 1128, 2 row lock(s), undo log entries 1
|
||||
MySQL thread id 638, OS thread handle 138111594002112, query id 479167 10.0.0.8 root
|
||||
```
|
||||
|
||||
通过MySQL系统库查询被阻塞的事务以及线程ID,手动kill释放资源
|
||||
|
||||
查询锁信息表:
|
||||
```sql
|
||||
-- 8.0 版本以前
|
||||
select * from information_schema.innodb_locks;
|
||||
-- 8.0版本开始
|
||||
select * from performance_schema.data_locks;
|
||||
```
|
||||
|
||||
## 关闭死锁检测
|
||||
```sql
|
||||
SHOW VARIABLES LIKE 'innodb_deadlock_detect';
|
||||
```
|
||||
|
||||
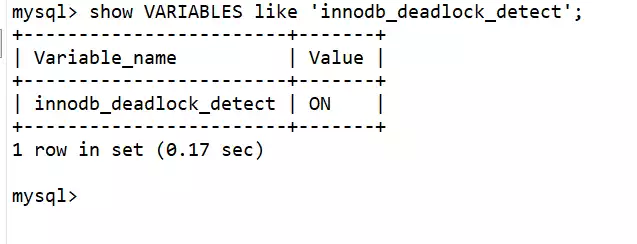
|
||||
|
||||
|
||||
```sql
|
||||
|
||||
SET GLOBAL innodb_deadlock_detect = 0;
|
||||
```
|
||||
|
||||
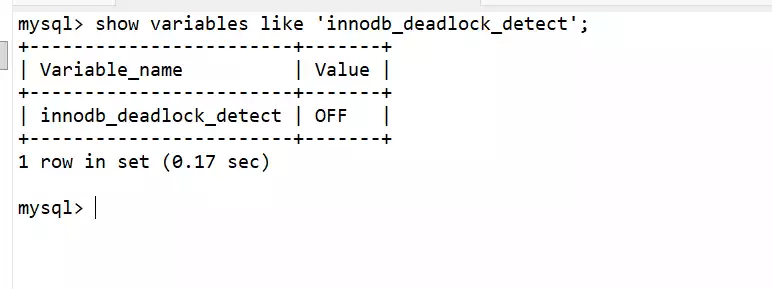
|
||||
|
||||
|
||||
接下来我们再次开两个事务
|
||||
|
||||
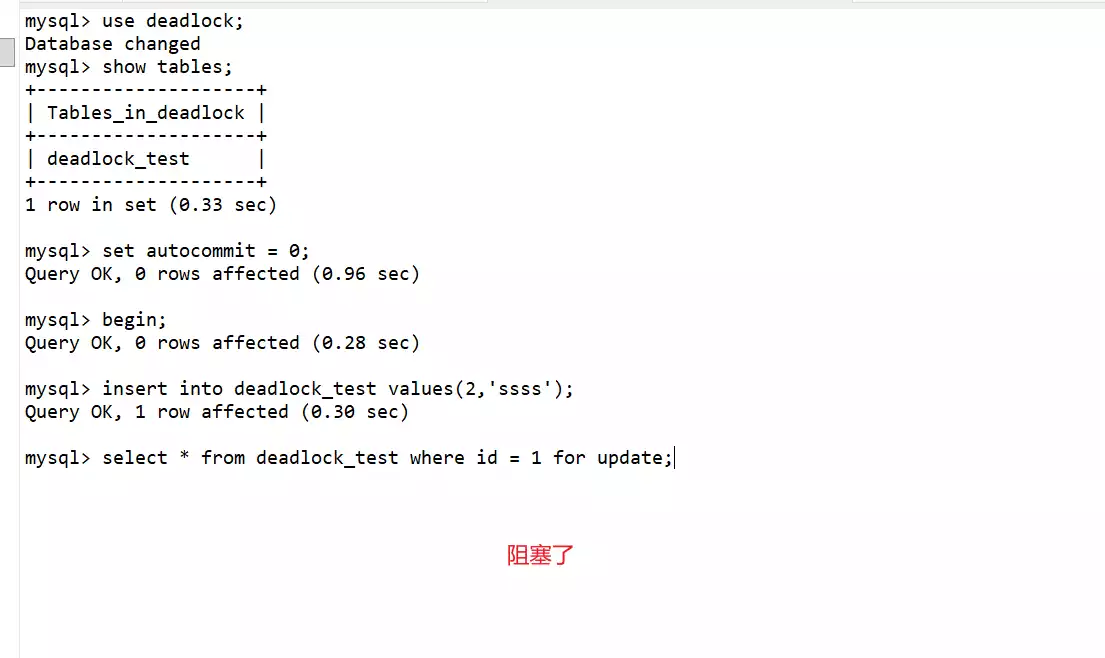
|
||||
|
||||
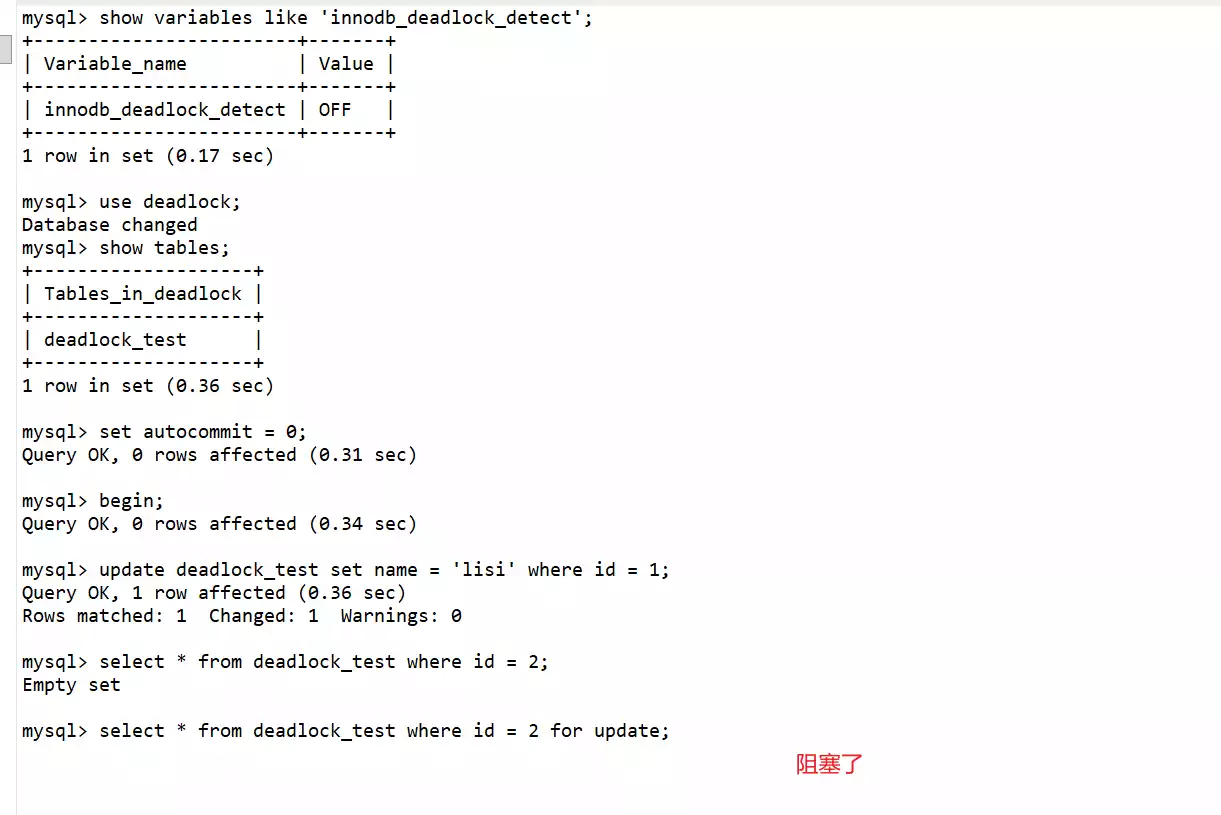
|
||||
|
||||
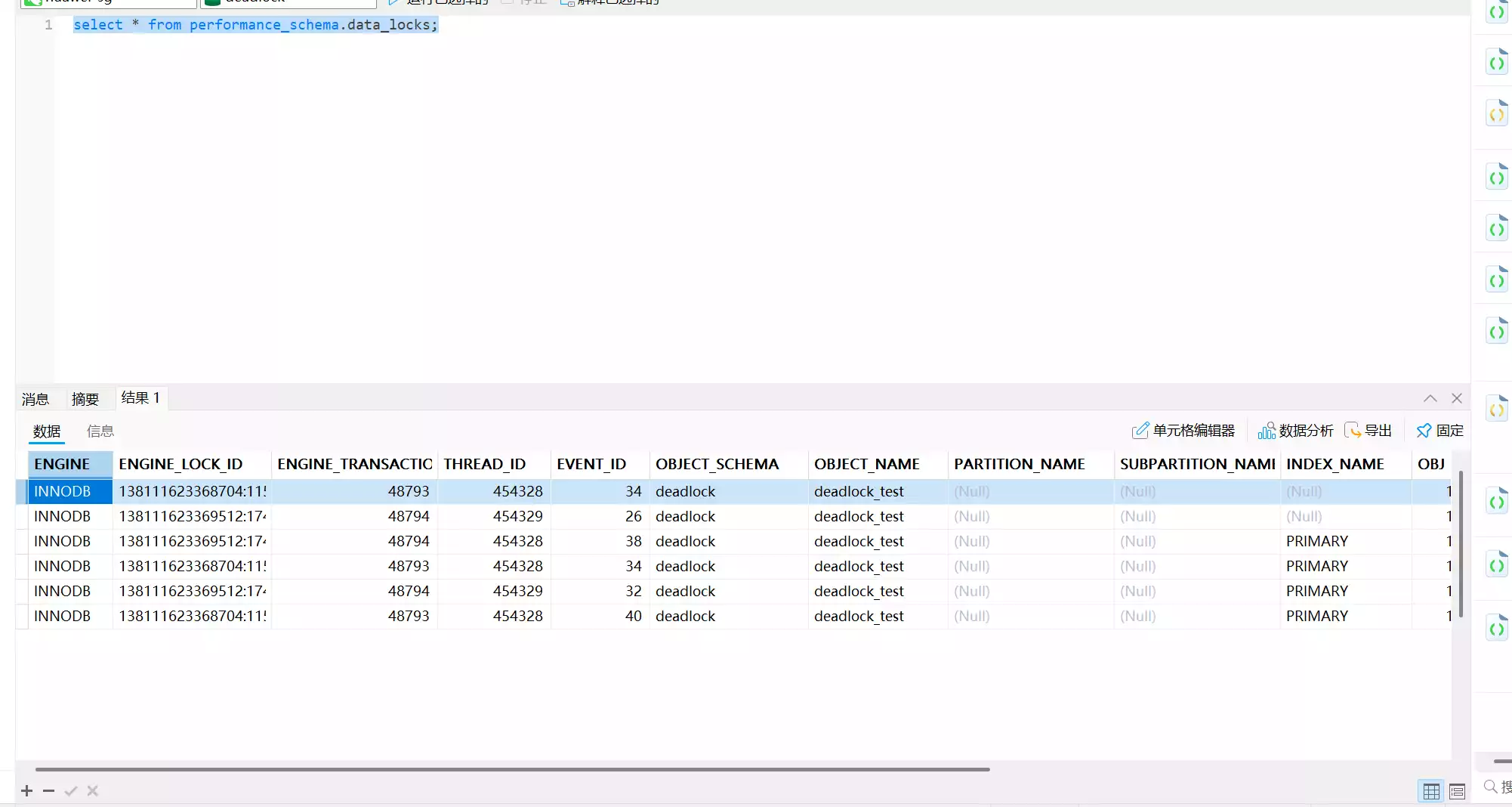
|
||||
|
||||
|
||||
查询锁等待信息表
|
||||
```sql
|
||||
-- 8.0版本之前
|
||||
select * from information_schema.innodb_lock_waits;
|
||||
-- 8.0版本开始
|
||||
select * from performance_schema.data_lock_waits;
|
||||
```
|
||||
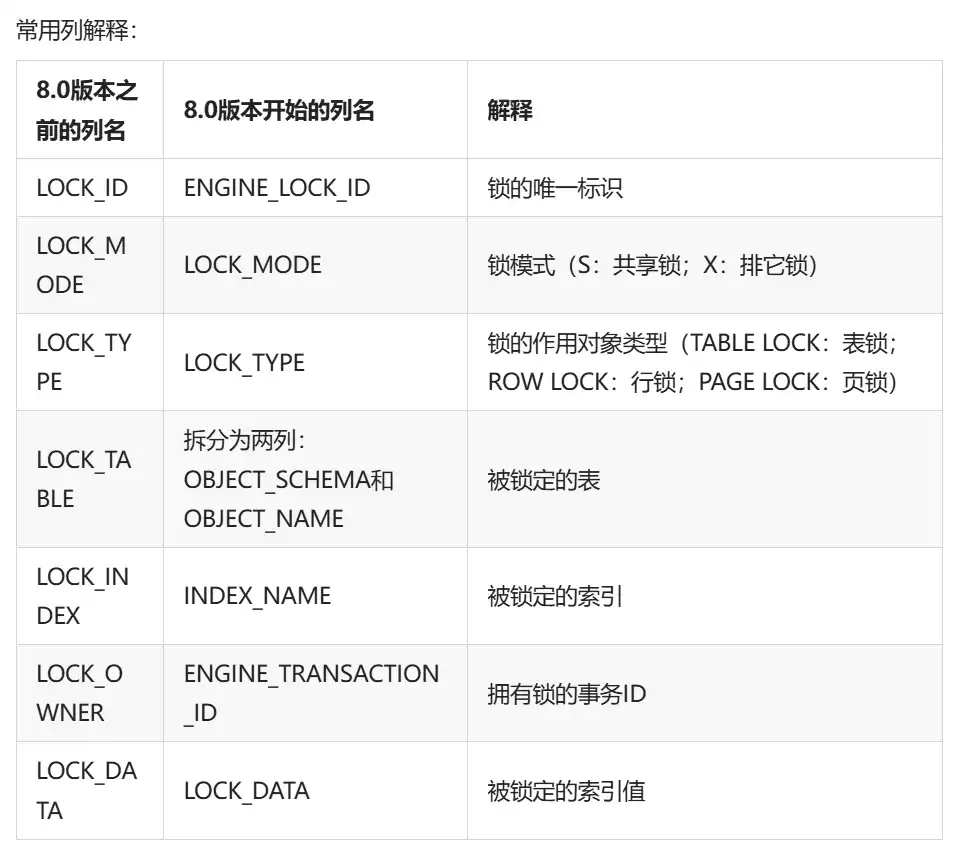
|
||||
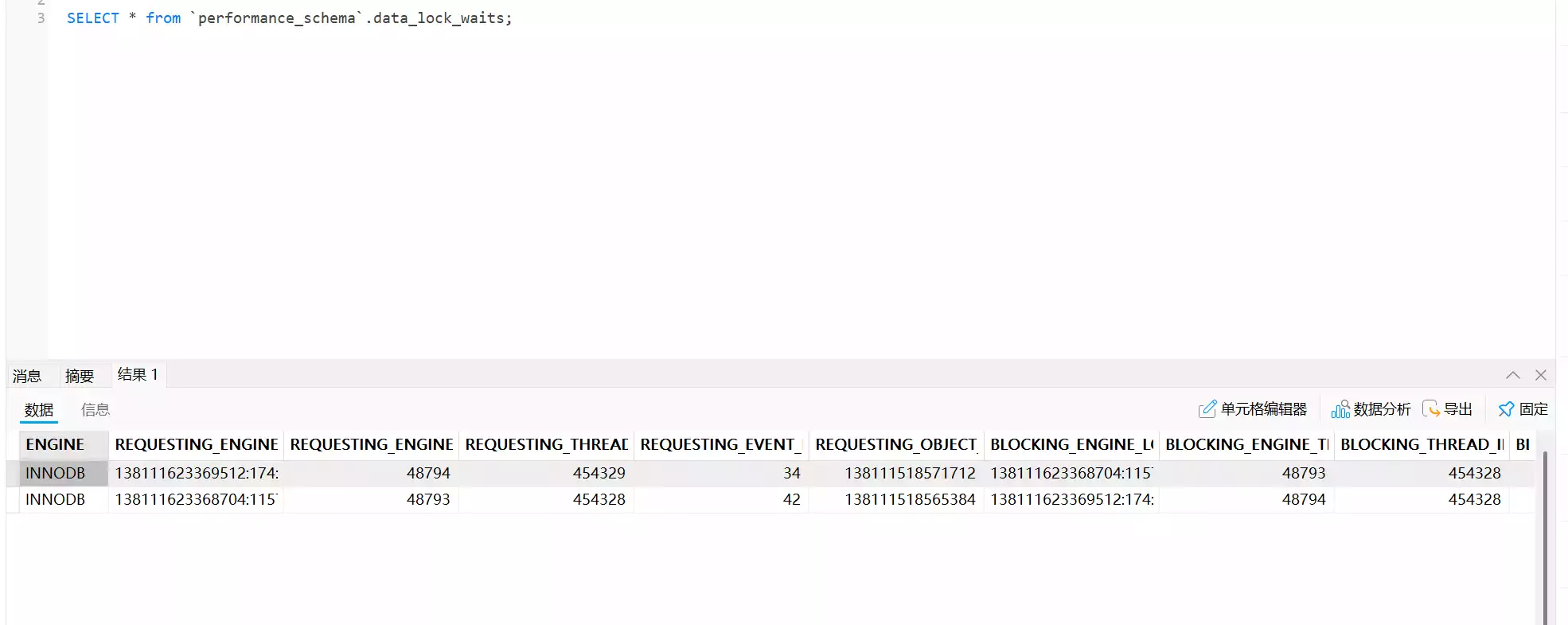
|
||||
|
||||

|
||||
|
||||
查询innodb事务信息
|
||||
```sql
|
||||
SELECT * from information_schema.INNODB_TRX;
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
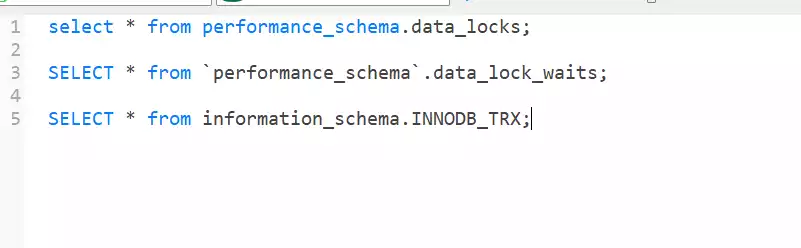
|
||||
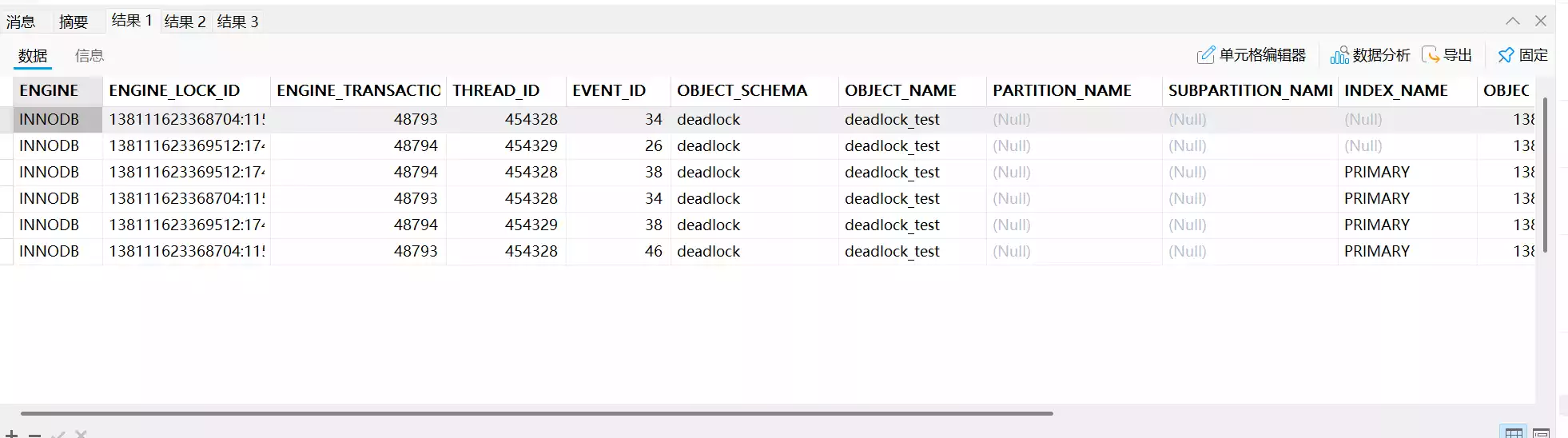
|
||||

|
||||

|
||||
|
||||
|
||||
|
||||
```sql
|
||||
-- 列出当前的阻塞者(含可直接 KILL 的进程号)
|
||||
SELECT
|
||||
b.ENGINE_TRANSACTION_ID AS blocking_trx_id,
|
||||
th.PROCESSLIST_ID AS blocking_pid,
|
||||
trx.trx_started,
|
||||
trx.trx_state,
|
||||
trx.trx_rows_locked,
|
||||
trx.trx_query
|
||||
FROM performance_schema.data_lock_waits w
|
||||
JOIN performance_schema.data_locks b
|
||||
ON w.blocking_engine_lock_id = b.engine_lock_id
|
||||
JOIN information_schema.INNODB_TRX trx
|
||||
ON b.engine_transaction_id = trx.trx_id
|
||||
JOIN performance_schema.threads th
|
||||
ON b.thread_id = th.thread_id
|
||||
GROUP BY blocking_trx_id, blocking_pid, trx.trx_started, trx.trx_state, trx.trx_rows_locked, trx.trx_query;
|
||||
|
||||
-- 杀掉阻塞会话
|
||||
KILL CONNECTION <blocking_pid>;
|
||||
```
|
||||
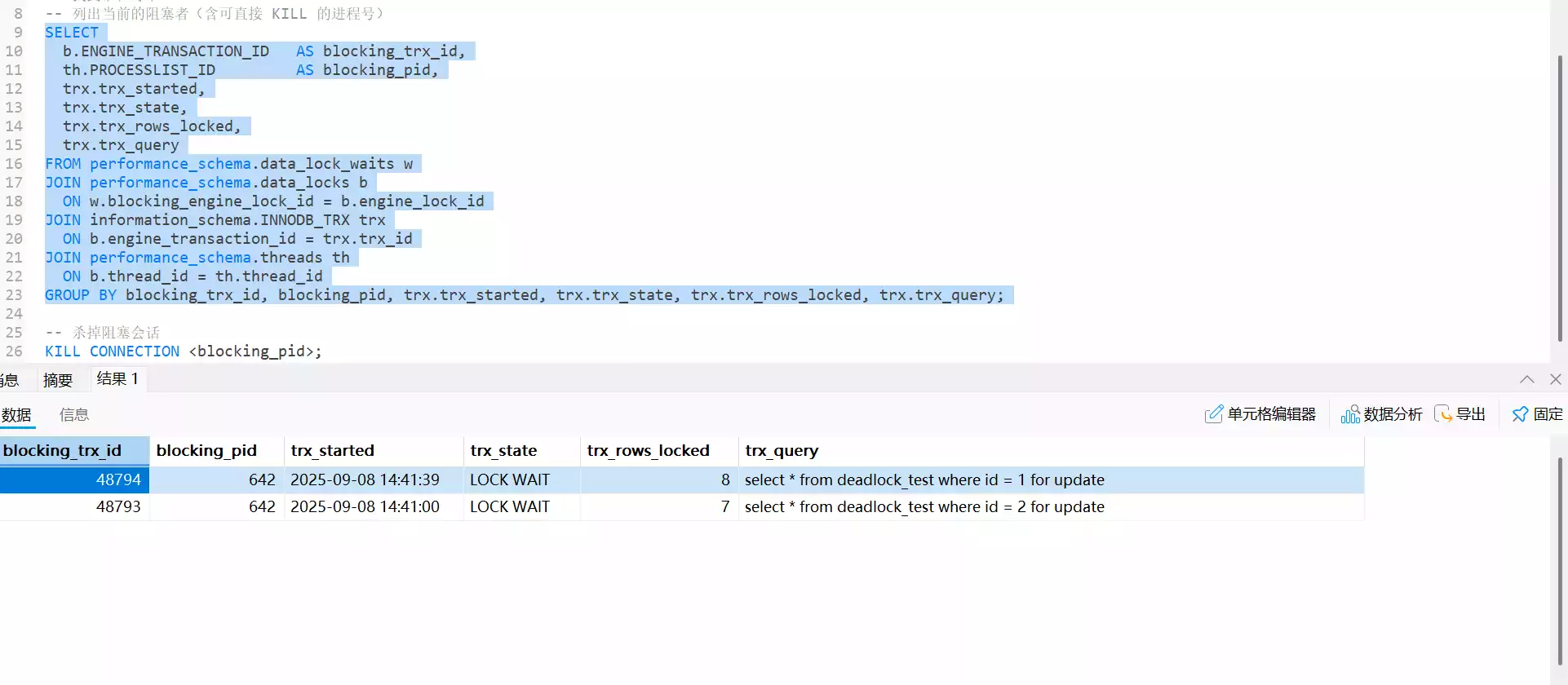
|
||||
|
||||
141
src/content/posts/中间件/MySQL/MySQL中如何解决深度分页问题.md
Normal file
141
src/content/posts/中间件/MySQL/MySQL中如何解决深度分页问题.md
Normal file
@@ -0,0 +1,141 @@
|
||||
---
|
||||
title: MySQL中如何解决深度分页问题
|
||||
published: 2025-09-09
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['MySQL', '分页','深度分页']
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# MySQL中如何解决深度分页问题
|
||||
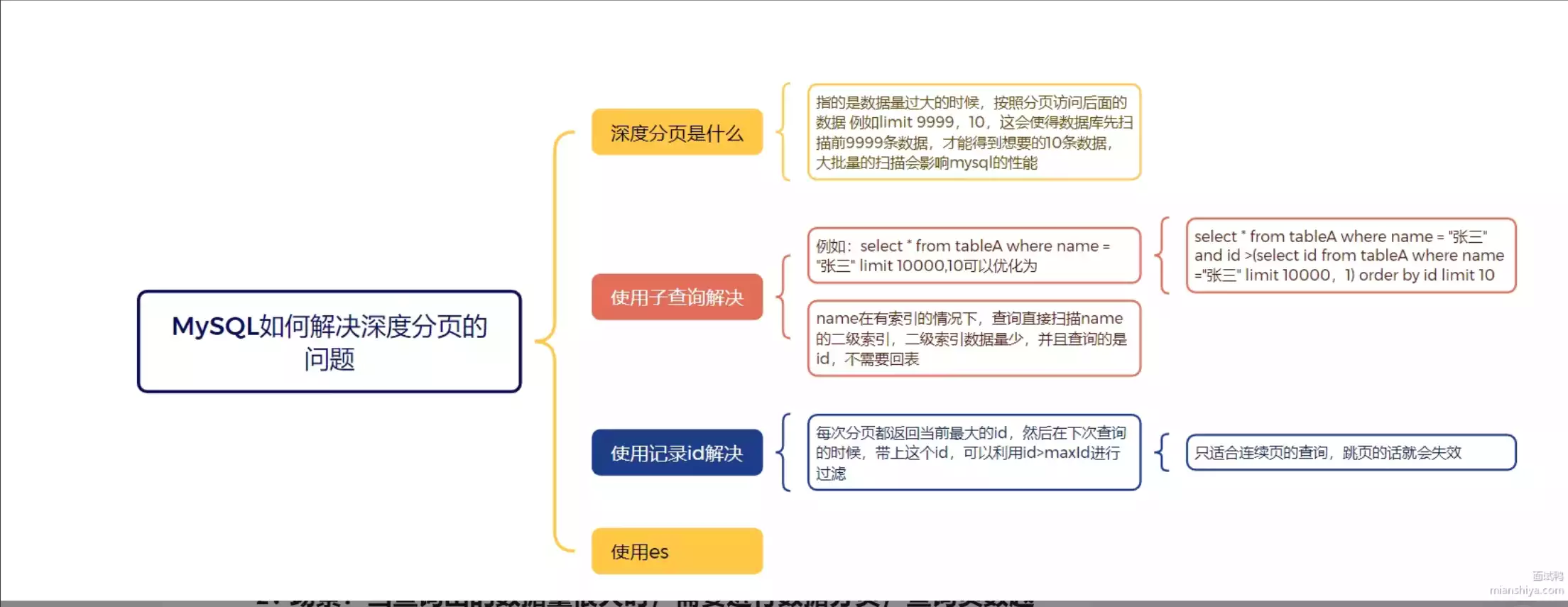
|
||||
|
||||

|
||||
## 问题描述
|
||||
|
||||
深度分页,指的是当数据量很大的时候,按照分页访问后面的数据,例如 `limit 9999990,10` 这会使得数据库要扫描前面的9999990条数据,才能得到最终的10条数据,大批量的扫描数据会增加数据库的负载,影响性能。
|
||||
|
||||
|
||||
## 三种优化方式
|
||||
### 记录id
|
||||
每次分页都返回当前的最大id,然后下次查询的时候,带上这个id,就能利用id > maxid过滤了。
|
||||
这种查询适合 连续查询的情况,如果跳页的话就不生效了。
|
||||
|
||||
普通分页的痛点:
|
||||
```sql
|
||||
SELECT * FROM article ORDER BY id LIMIT 10 OFFSET 100000;
|
||||
```
|
||||
MySQL 需要先扫描并跳过 前 100000 行,然后再返回后 10 行。(这里说下底层原因)
|
||||
|
||||
OFFSET 越大,性能越差。
|
||||
|
||||
我们每次查询时带上 上一次返回的最大 id,下一页就只要取 id > last_id 的记录。
|
||||
|
||||
不依赖 OFFSET,直接利用索引顺序扫描。
|
||||
|
||||
```sql
|
||||
select * from products limit 0,10; -- 第一页
|
||||
select * from products where id > 10 limit 10; -- 第二页
|
||||
select * from products where id > 20 limit 10; -- 第三页
|
||||
select * from products where id > 30 limit 10; -- 第四页
|
||||
```
|
||||
|
||||
### 子查询
|
||||
|
||||
这里其实和记录id的优化方式是一样的,只不过这里用的是子查询。理论上我们应该先去查询到上一页的最大id,然后再查询下一页的数据。
|
||||
|
||||
```sql
|
||||
SELECT * from products where id > (
|
||||
SELECT id from products order by created_at desc limit 199999,1) order by created_at desc limit 10;
|
||||
```
|
||||
这里我们给表的created_at建索引,可以利用created_at的二级索引进行扫描,然后利用id > 上一次查询的最大id进行过滤,最后再利用created_at的二级索引进行排序,最后再利用limit进行分页。
|
||||

|
||||
|
||||
子查询只读索引列(最好覆盖:筛选列 + 排序列 + id),IO 最小化。
|
||||
外层 JOIN 回表范围仅为一页大小(如 20 条),成本可控。
|
||||
|
||||
|
||||
相较于原来的
|
||||
```sql
|
||||
SELECT * FROM products order by created_at desc limit 200000,10;
|
||||
|
||||
```
|
||||
这个虽然可以利用created_at的二级索引进行扫描,但是它需要对每条记录进行一次回表操作,还要丢弃掉前200000条记录,性能较差。
|
||||
|
||||

|
||||
|
||||
|
||||
### join方法
|
||||
|
||||
```sql
|
||||
SELECT p.* FROM products p INNER JOIN (
|
||||
SELECT id FROM products ORDER BY created_at DESC limit 10 OFFSET 200000 ) AS page_results on p.id = page_results.id order by p.created_at desc;
|
||||
|
||||
```
|
||||
|
||||
这个和上面的子查询方式是一样的,只不过这里用的是join。
|
||||
|
||||
|
||||
### 使用es
|
||||
直接上elasticsearch,利用它本身分页的特性,进行优化。
|
||||
|
||||
---
|
||||
|
||||
```SQL
|
||||
use pages;
|
||||
-- 创建商品表
|
||||
CREATE TABLE `products` (
|
||||
`id` BIGINT AUTO_INCREMENT COMMENT '自增主键ID',
|
||||
`product_name` VARCHAR(255) NOT NULL COMMENT '商品名称',
|
||||
`category_id` INT NOT NULL COMMENT '分类ID',
|
||||
`price` DECIMAL(10, 2) NOT NULL COMMENT '价格',
|
||||
`created_at` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品表';
|
||||
|
||||
-- 在排序字段上创建索引,这是至关重要的
|
||||
CREATE INDEX `idx_created_at` ON `products` (`created_at`);
|
||||
|
||||
-- (可选)创建一个更实用的联合索引,例如按分类查找再按时间排序
|
||||
CREATE INDEX `idx_category_created` ON `products` (`category_id`, `created_at`);
|
||||
|
||||
|
||||
-- 修改MySQL的语句结束符,以便在存储过程中使用分号
|
||||
DELIMITER $$
|
||||
|
||||
-- 创建一个名为 insert_mock_products 的存储过程
|
||||
CREATE PROCEDURE `insert_mock_products`(IN insert_count INT)
|
||||
BEGIN
|
||||
-- 定义一个循环计数器
|
||||
DECLARE i INT DEFAULT 1;
|
||||
|
||||
-- 开始循环
|
||||
WHILE i <= insert_count DO
|
||||
INSERT INTO `products` (
|
||||
`product_name`,
|
||||
`category_id`,
|
||||
`price`,
|
||||
`created_at`
|
||||
) VALUES (
|
||||
-- 生成一个像 'Product 123' 这样的随机商品名
|
||||
CONCAT('Product ', i),
|
||||
-- 生成一个 1 到 50 之间的随机分类ID
|
||||
FLOOR(1 + RAND() * 50),
|
||||
-- 生成一个 10.00 到 1000.99 之间的随机价格
|
||||
ROUND(10 + RAND() * 990.99, 2),
|
||||
-- 生成一个从现在开始,逐步往前推移的时间,确保时间戳的唯一和顺序性
|
||||
-- 这里用秒作为递减单位,可以确保排序的稳定性
|
||||
DATE_SUB(NOW(), INTERVAL i SECOND)
|
||||
);
|
||||
-- 计数器加1
|
||||
SET i = i + 1;
|
||||
END WHILE;
|
||||
END$$
|
||||
|
||||
-- 将语句结束符恢复为默认的分号
|
||||
DELIMITER ;
|
||||
|
||||
-- 调用存储过程,并传入你想要插入的数据量
|
||||
CALL insert_mock_products(1000000);
|
||||
```
|
||||
201
src/content/posts/中间件/MySQL/MySQL中的全局锁表级锁行级锁机制.md
Normal file
201
src/content/posts/中间件/MySQL/MySQL中的全局锁表级锁行级锁机制.md
Normal file
@@ -0,0 +1,201 @@
|
||||
---
|
||||
title: MySQL全局锁,表级锁,行级锁
|
||||
published: 2025-08-09
|
||||
description: 'MySQL中的全局锁,表级锁,行级锁机制'
|
||||
image: ''
|
||||
tags: [全局锁,表级锁,行级锁]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
# MySQL的锁
|
||||
## 全局锁
|
||||
如果要使用全局锁
|
||||
要执行下面的命令:
|
||||
```sql
|
||||
flush table with read lock
|
||||
```
|
||||
|
||||
|
||||
|
||||
执行全局锁以后,数据库就变成只读状态了,插入和更新操作都会被阻塞
|
||||
|
||||
这个全局锁一般是用于数据库全局备份的。在备份数据库期间,不会因为数据和表结构的更新,出现备份文件的数据和预期的不一样。
|
||||
|
||||
|
||||
|
||||
可以看到会卡主
|
||||
|
||||
|
||||
|
||||
解锁以后就可以插入了
|
||||
|
||||
备份数据库的时候又不想停机,可以在用 mysqldump的时候加上 --single-transaction参数,就会在备份数据之前先开启事务。这种方法只适用于支持可重复读隔离级别的事务的存储引擎。
|
||||
|
||||
|
||||
## 表级锁
|
||||
MySQL中的表级锁有哪些?
|
||||
- 表锁
|
||||
- 元数据锁
|
||||
- 意向锁
|
||||
- AUTO-INC锁
|
||||
|
||||
### 表锁
|
||||
如果我们相对student表加上表锁
|
||||
```sql
|
||||
-- 允许当前会话读取被锁定的表,但是会组织其他会话对这些表进行写操作
|
||||
lock table student_t read;
|
||||
|
||||
-- 表级别的独占锁,也就是写锁
|
||||
-- 允许当前会话对表进行读写操作,但会阻止其他会话对这些表进行任何操作
|
||||
lock table student_t write;
|
||||
```
|
||||
|
||||
需要注意的是,表锁除了会限制别的线程的读写外,也会限制本线程接下来的读写操作。
|
||||
|
||||
|
||||
### 元数据锁
|
||||
元数据锁不需要显示调用,因为当我们对数据库表进行操作的时候,会自动给这个表加上MDL
|
||||
|
||||
当我们对一张表进行CRUD操作的时候,加的是MDL读锁
|
||||
当我们对一张表做结构变更操作的时候,加的是MDL写锁
|
||||
|
||||
MDL是为了保证当用户对表执行CRUD操作的时候,防止其他线程对这个表结构做变更。
|
||||
|
||||
比如说,一个线程正在执行查询操作(加了MDL读锁),如果有其他线程来修改表结构,就会被阻塞,直到查询结束。
|
||||
同理,一个线程在修改表结构的时候(申请了MDL写锁),其他线程的查询操作就会被阻塞,直到说表结构变更完成
|
||||
|
||||
|
||||
### 意向锁
|
||||
- 在使用InnoDB引擎的表里对某些记录加上共享锁之前,需要先在表级别上加一个意向共享锁。
|
||||
- 在使用InnoDB引擎的表里对某些记录加上独占锁之前,需要先在表级别加上一个意向独占锁。
|
||||
|
||||
普通的select是不会加行级锁的,因为它是用MVCC(多版本并发控制)实现的,是无锁的。
|
||||
|
||||
不过select也是可以对记录加共享锁和独占锁的。
|
||||
|
||||
```sql
|
||||
//先在表上加上意向共享锁,然后对读取的记录加共享锁
|
||||
select ... lock in share mode;
|
||||
|
||||
//先表上加上意向独占锁,然后对读取的记录加独占锁
|
||||
select ... for update;
|
||||
```
|
||||
|
||||
|
||||
> 意向共享锁和意向独占锁是表级锁,不会和行级的共享锁和独占锁发生冲突,而且意向锁之间也不会发生冲突,只会和共享表锁和独占锁发生冲突。
|
||||
|
||||
意向锁的目的是为了快速判断表里是否有记录被加锁。
|
||||
比如说,当一个事务想要对某个记录加锁时,可以先检查表级的意向锁,如果表级的意向锁是共享锁,就说明有其他事务正在读取这个表中的记录;如果是独占锁,就说明有其他事务正在修改这个表中的记录。
|
||||
|
||||
如果表级的意向锁是共享锁,那么其他事务可以对表上共享锁,但是不能加独占锁。如果是表级意向锁是独占锁,其他事务就不能对表上加任何锁。
|
||||
|
||||
|
||||
### AUTO-INC锁
|
||||
表里的主键通常会设置成自增的,这是通过主键字段声明 AUTO_INCREMENT 属性实现的。
|
||||
|
||||
之后可以在插入数据的时候,可以不指定主键的值,数据库会自动给主键赋值递增的值,这主要是通过 AUTO-INC锁实现的。
|
||||
|
||||
AUTO-INC锁是特殊的表锁机制,锁不是在一个事务提交后才释放,而是在执行完插入语句后就会立刻释放。
|
||||
|
||||
在插入数据的时候,会加一个表级别的AUTO-INC锁,然后为被 `AUTO_INCREMENT` 修饰的字段赋值递增的值,等插入语句执行完成后,才会把AUTO-INC锁释放掉。
|
||||
|
||||
那么在一个事务持有AUTO-INC锁的过程中,其他事务如果要向该表插入语句都会被阻塞,从而保证了插入数据的时候,被AUTO_INCREMENT修饰的字段的值是连续递增的。
|
||||
|
||||
因此,在MySQL5.1.22开始,InnoDB存储引擎提供了一种轻量级的锁来实现自增。
|
||||
|
||||
一样也是在插入数据的时候,会为被auto_increment修饰的字段加上轻量级锁,然后给该字段赋值一个自增的值,然后就把这个轻量级锁释放了,不需要等待整个插入语句执行完成后才释放锁。
|
||||
|
||||
## 行级锁
|
||||
InnoDB引擎是支持行级锁的,而MyISAM不支持行级锁
|
||||
|
||||
可以使用下面这两个方式,这种查询会加锁的语句称为锁定读。
|
||||
```sql
|
||||
//对读取的记录加共享锁
|
||||
select ... lock in share mode;
|
||||
|
||||
//对读取的记录加独占锁
|
||||
select ... for update;
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 行级锁类型
|
||||
有三类:
|
||||
- Record Lock,记录锁,也就是仅仅把一条记录锁上
|
||||
- Gap Lock 间隙锁,锁定一个范围,但是不包含记录本身
|
||||
- Next-Key Lock: Record Lock + Gap Lock的组合,锁定一个范围,并且锁定记录本身
|
||||
|
||||
|
||||
### Record Lock 记录锁
|
||||
Record Lock被称为记录锁,锁住的锁一条记录,而且记录锁是有S锁和X锁之分的。
|
||||
|
||||
- 当一个事务对一条记录加了S型记录锁后,其他事务也可以继续对该记录加S型记录锁,但是不可以对该记录加X型记录锁
|
||||
- 当一个事务对一条记录加了X型记录锁后,其他事务不可以对该记录加S型记录锁,也不可对该记录加X型记录锁
|
||||
|
||||
|
||||

|
||||
|
||||
### Gap Lock 间隙锁
|
||||
|
||||
Gap Lock被称为间隙锁,存在于可重复读隔离级别和串行化隔离级别,目的是为了解决可重复读隔离级别下幻读的现象
|
||||
|
||||
|
||||
假设表中有一个范围id为(3,5)的间隙锁,那么其他事务就无法插入id = 4这条记录了,这样就有效地防止了幻读现象的发生。
|
||||
|
||||
间隙锁虽然也存在X型和S型间隙锁,但是没什么区别,间隙锁之间是兼容的,两个事务可以同时持有并包含共同间隙范围的间隙锁,并不存在互斥关系,因为间隙锁的目的是防止插入幻影记录而提出的。
|
||||
|
||||
|
||||
|
||||
|
||||
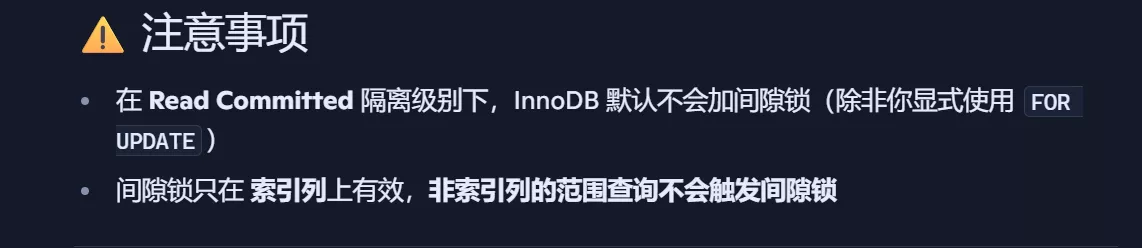
|
||||
|
||||

|
||||
|
||||
|
||||
### Next-Key Lock 临键锁
|
||||
|
||||
Next-Key-Lock称为临键锁,是Record Lock和Gap Lock的组合。锁定一个范围,并且锁定记录本身。
|
||||
假设表中有个范围id为(3,5]的next-key-lock,那么其它事务既不能插入id = 4的记录,也不能修改id = 5这条记录。
|
||||
|
||||
所以next-key lock既能保护该记录,又能阻止其它事务将新记录插入到被保护记录前面的间隙中。
|
||||
|
||||
Next-key lock 是数据库中 InnoDB 存储引擎(常见于 MySQL)使用的一种锁机制,主要用于防止 **幻读(Phantom Read)** 问题,确保事务在可重复读(Repeatable Read)隔离级别下的一致性。它的意义在于通过结合 **记录锁(Record Lock)** 和 **间隙锁(Gap Lock)**,对索引记录及其前后的间隙进行锁定,从而避免其他事务插入或修改数据导致的幻读现象。
|
||||
|
||||
#### 具体意义和作用:
|
||||
1. **防止幻读**:
|
||||
- 幻读是指在同一事务中,多次执行相同查询时,由于其他事务插入了新记录,导致查询结果集发生变化。
|
||||
- Next-key lock 锁定一个索引记录及其前后的间隙,防止其他事务插入新记录到这个范围内,从而保证查询结果的稳定性。
|
||||
|
||||
2. **结合记录锁和间隙锁**:
|
||||
- **记录锁**:锁定具体的索引记录,防止其他事务修改或删除该记录。
|
||||
- **间隙锁**:锁定索引记录之间的“间隙”,防止其他事务在该间隙内插入新记录。
|
||||
- Next-key lock 是两者的结合,锁定一个记录及其左侧或右侧的间隙。例如,对于索引值 10,Next-key lock 可能锁定 (5, 10] 范围(假设 5 是前一个索引值)。
|
||||
|
||||
3. **提高并发控制的精度**:
|
||||
- Next-key lock 是一种范围锁,比表级锁更精细,能够在保证数据一致性的同时,尽量减少锁的粒度,提高并发性能。
|
||||
|
||||
4. **支持可重复读隔离级别**:
|
||||
- 在 MySQL 的可重复读(Repeatable Read)隔离级别下,Next-key lock 是默认的锁机制,用于确保事务在多次读取时看到一致的数据快照。
|
||||
|
||||
#### 工作原理:
|
||||
- 当事务对某一行记录进行操作(例如 SELECT ... FOR UPDATE 或 UPDATE),InnoDB 会锁定该记录以及其前后的间隙。
|
||||
- 例如,假设表中有一个索引列 `id` 包含值 10、20、30。如果事务 A 对 `id = 20` 加锁,Next-key lock 可能会锁定 (10, 20] 或 (20, 30] 的范围,防止其他事务插入值在该范围内的记录。
|
||||
|
||||
#### 注意事项:
|
||||
1. **性能影响**:Next-key lock 锁定范围较大,可能导致锁冲突,降低并发性能。
|
||||
2. **死锁风险**:多个事务竞争相同的间隙锁可能导致死锁,需要合理设计事务逻辑。
|
||||
3. **依赖索引**:Next-key lock 依赖于索引。如果查询没有使用索引,可能会退化为表级锁,影响性能。
|
||||
|
||||
总结来说,Next-key lock 的核心意义在于通过锁定记录和间隙,防止幻读,维护事务隔离级别的一致性,同时在高并发场景下提供较好的数据保护机制。
|
||||
|
||||
|
||||
### 插入意向锁
|
||||
一个事务在插入一条记录的时候,需要判断插入位置是否已被其他事务加了间隙锁(next-key lock 也包含间隙锁)。
|
||||
|
||||
如果有的话,插入操作就会发生阻塞,直到拥有间隙锁的那个事务提交为止(释放间隙锁的时刻),在此期间会生成一个插入意向锁,表明有事务想在某个区间插入新记录,但是现在处于等待状态。
|
||||
10
src/content/posts/中间件/MySQL/MySQL中的数据排序是怎么实现的.md
Normal file
10
src/content/posts/中间件/MySQL/MySQL中的数据排序是怎么实现的.md
Normal file
@@ -0,0 +1,10 @@
|
||||
---
|
||||
title: MySQL中的数据排序是怎么实现的
|
||||
published: 2025-09-07
|
||||
description: ''
|
||||
image: ''
|
||||
tags: []
|
||||
category: ''
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
10
src/content/posts/中间件/MySQL/MySQL事务的两阶段提交是什么.md
Normal file
10
src/content/posts/中间件/MySQL/MySQL事务的两阶段提交是什么.md
Normal file
@@ -0,0 +1,10 @@
|
||||
---
|
||||
title: MySQL事务的两阶段提交是什么
|
||||
published: 2025-09-08
|
||||
description: ''
|
||||
image: ''
|
||||
tags: []
|
||||
category: ''
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
30
src/content/posts/中间件/MySQL/MySQL事务隔离级别.md
Normal file
30
src/content/posts/中间件/MySQL/MySQL事务隔离级别.md
Normal file
@@ -0,0 +1,30 @@
|
||||
---
|
||||
title: MySQL事务隔离级别
|
||||
published: 2025-09-07
|
||||
description: ""
|
||||
image: ""
|
||||
tags: ["事务隔离级别", "MySQL"]
|
||||
category: "中间件 > MySQL"
|
||||
draft: false
|
||||
lang: ""
|
||||
---
|
||||
|
||||
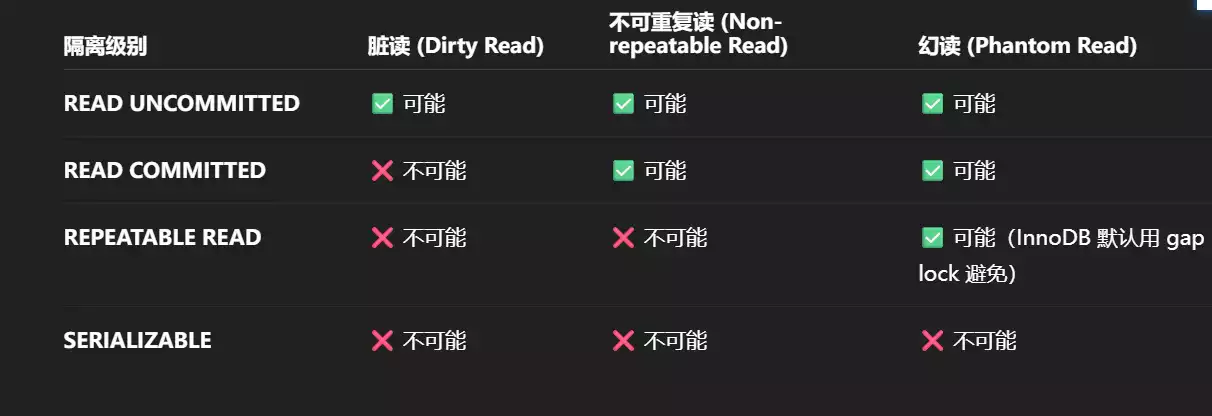
|
||||
|
||||
# 1 读未提交(脏读,不可重复读,幻读 问题)
|
||||
|
||||
最低的事务隔离级别,在这个事务隔离级别下,一个事务能看到另外一个事务未提交的数据修改,会导致 **脏读** 的问题(读取到其他事务未提交的数据)
|
||||
|
||||
# 2 读已提交(不可重复读,幻读)
|
||||
|
||||
这个事务隔离级别虽然解决了脏读问题,也就是只能读取到另外一个事务已经提交的数据,读取不到另外一个事务没有提交的数据,但是它有**不可重复读**的问题(同一个事务中,相同的查询会返回不同的结果)
|
||||
|
||||
# 3 可重复读(幻读) MySQL 默认事务隔离级别
|
||||
|
||||
这个事务隔离级别,使用 MVCC(快照读)的方式,解决了不可重复读的问题,但是还是有**幻读**的问题(幻读也就是在一个事务中,读取到另外一个事务插入的行,导致这个事务查询到的结果集行数不同)
|
||||
|
||||

|
||||
|
||||
# 4 串行化
|
||||
|
||||
最高的事务隔离级别,使用排他锁(Exclusive Lock)来保证事务的完全隔离。
|
||||
75
src/content/posts/中间件/MySQL/MySQL索引类型有哪些.md
Normal file
75
src/content/posts/中间件/MySQL/MySQL索引类型有哪些.md
Normal file
@@ -0,0 +1,75 @@
|
||||
---
|
||||
title: MySQL索引类型有哪些
|
||||
published: 2025-08-14
|
||||
description: ""
|
||||
image: ""
|
||||
tags: [索引, MySQL]
|
||||
category: "中间件 > MySQL"
|
||||
draft: false
|
||||
lang: ""
|
||||
---
|
||||
|
||||
# MySQL 索引类型有哪些
|
||||
|
||||
## 按数据结构分
|
||||
|
||||
分为
|
||||
|
||||
- B-Tree 索引
|
||||
- Hash 索引
|
||||
- Full-text 索引
|
||||
|
||||
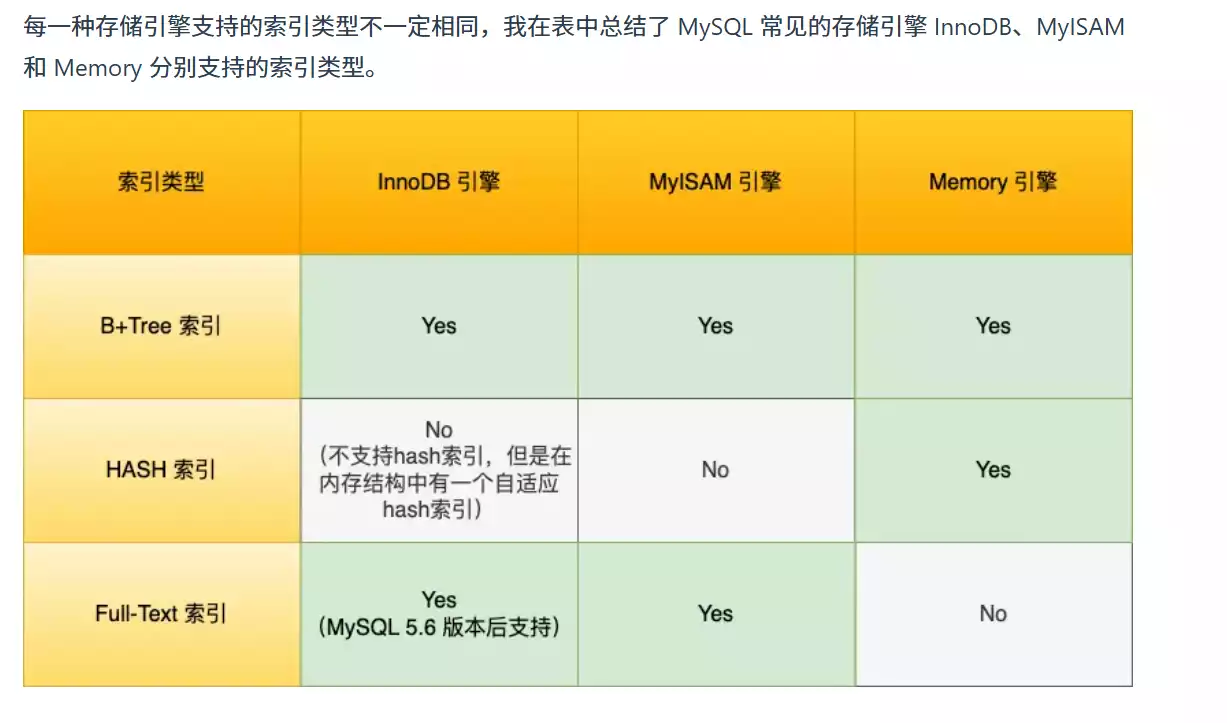
|
||||
|
||||
创建表的时候,InnoDB 存储引擎会根据不同的场景选择不同的列作为索引:
|
||||
|
||||
- 有主键:会使用主键作为聚簇索引的索引键
|
||||
- 没有主键: 选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键
|
||||
- 上面两个都没有的情况下,InnoDB 会自动生成一个隐式自增 id 列作为聚簇索引的索引键。
|
||||
|
||||
其他索引都属于辅助索引,也就是非聚簇索引或者二级索引。
|
||||
|
||||
## 按物理存储分
|
||||
|
||||
分为
|
||||
|
||||
- 聚簇索引(主键索引)
|
||||
- 二级索引(辅助索引)
|
||||
|
||||
## 按字段特性分
|
||||
|
||||
- 主键索引
|
||||
- 唯一索引
|
||||
- 普通索引
|
||||
- 前缀索引
|
||||
|
||||
主键索引是唯一的,且不允许为 NULL。每个表只能有一个主键索引。
|
||||
|
||||
## 按字段个数分
|
||||
|
||||
- 单列索引
|
||||
- 联合索引
|
||||
|
||||
---
|
||||
|
||||
# 按数据结构分
|
||||
|
||||
- B+树索引
|
||||
- 哈希索引
|
||||
- 倒排索引(Full-text 索引)
|
||||
- R-树索引 (多维树空间)
|
||||
|
||||
从 InnoDB b+树索引来看,分为聚簇索引和非聚簇索引
|
||||
聚簇索引也就是主键索引,叶子节点存储整行的数据,非叶子节点存储主键值和指向子节点的指针。
|
||||
非聚簇索引叶子节点存储主键,非叶子节点存储主键值和指向子节点的指针。
|
||||
因此,非聚簇索引查询需要回表查询
|
||||
|
||||
# 从索引性质看
|
||||
|
||||
有
|
||||
普通索引
|
||||
主键索引
|
||||
唯一索引
|
||||
联合索引
|
||||
全文索引
|
||||
空间索引
|
||||
30
src/content/posts/中间件/MySQL/MySQL联合索引失效情况.md
Normal file
30
src/content/posts/中间件/MySQL/MySQL联合索引失效情况.md
Normal file
@@ -0,0 +1,30 @@
|
||||
---
|
||||
title: MySQL联合索引失效情况
|
||||
published: 2025-09-15
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['MySQL','联合索引']
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# MySQL联合索引失效情况
|
||||
|
||||
|
||||
## 1. 不满足最左匹配原则
|
||||
|
||||
## 2. 在索引上使用函数或者运算
|
||||
|
||||
## 3. 索引列参与隐式类型转换
|
||||
|
||||
## 4. 使用NOT IN,!=,<>等否定操作符
|
||||
|
||||
## 5. 模糊匹配 like %xxx%
|
||||
|
||||
## 6.OR操作符
|
||||
如果在Where子句中使用了OR操作符,并且OR前的条件列是索引列,OR后的不是索引列,那么索引可能会失效。
|
||||
|
||||
## 7. 使用 not exists关键字,索引也会失效(本质上是Where查询范围太大)
|
||||
|
||||
## 8. 使用Order By 注意最左匹配,要加limit或者Where关键字,否则索引会失效
|
||||
50
src/content/posts/中间件/MySQL/什么是MySQL的主从同步机制.md
Normal file
50
src/content/posts/中间件/MySQL/什么是MySQL的主从同步机制.md
Normal file
@@ -0,0 +1,50 @@
|
||||
---
|
||||
title: 什么是MySQL的主从同步机制
|
||||
published: 2025-09-09
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['MySQL', '主从同步']
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# 什么是MySQL的主从同步机制
|
||||
|
||||
MySQL的主从同步机制是一种数据复制技术,用于将住数据库上的数据同步到一个或者多个从数据库中。
|
||||
主要是通过二进制日志 binlog 实现数据的复制。
|
||||
主数据库在执行写操作的时候,会把这些操作记录在binlog里面,然后推送给从数据库,从数据库重放对应的日志即可完成复制。
|
||||
|
||||
# MySQL主从复制类型
|
||||
|
||||
MySQL支持异步复制,同步复制,半同步复制
|
||||
|
||||
异步复制: 主库不需要等待从库的响应(性能高,一致性低)
|
||||
同步复制: 主库同步等待所有从库确认收到的数据(性能差,一致性高)
|
||||
半同步复制: 主库等待至少一个从库确认收到数据(性能折中,数据一致性比较高)
|
||||
|
||||
## 异步复制
|
||||
|
||||
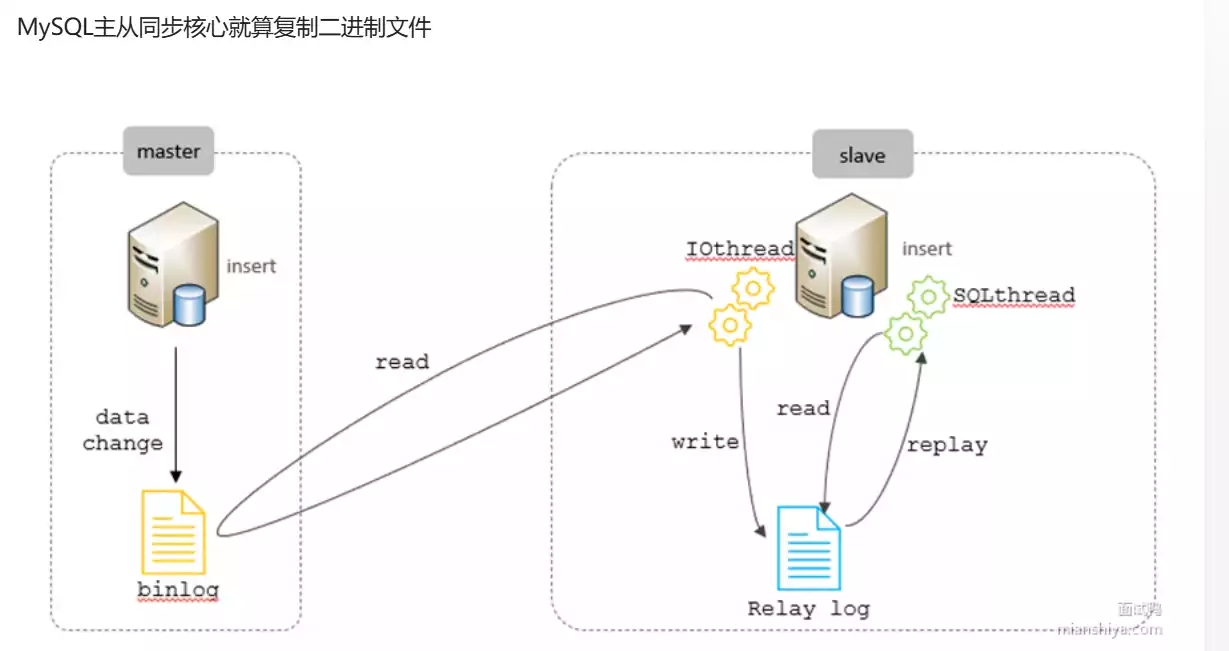
|
||||
|
||||
MySQL默认是异步复制。
|
||||
|
||||
|
||||
# 主从复制流程
|
||||
|
||||
1. 线程创建,从服务器创建一个IO线程,一个SQL线程,IO线程负责读取主服务器上的binlog,并写入到本地relay log中,SQL线程负责读取relay log中的日志,并执行到从服务器上
|
||||
2. 连接建立: 从服务器的IO线程与主服务器建立连接,主服务器的binlog dump线程和从服务器的IO线程进行交互
|
||||
3. 从服务器的IO线程告诉主服务器开始日志传送的对应位置
|
||||
4. 主服务器更新的时候把记录保存到binlog中
|
||||
5. 主服务器dump线程检测到binlog变化,从指定位置开始读取,从服务器进行拉取。
|
||||
6. 中继日志存储: 从服务器的IO线程把接收到的内容保存到relay log中
|
||||
7. 数据写入: 从服务器的SQL线程读取relay log中的内容,进行数据写入。
|
||||
|
||||
# 主从复制延迟
|
||||
|
||||
主从复制延迟是指主服务器和从服务器之间数据同步的时间差。
|
||||
主从复制延迟的原因有很多,例如网络延迟,主服务器和从服务器之间的硬件差异,主服务器和从服务器之间的操作系统差异,主服务器和从服务器之间的MySQL版本差异,主服务器和从服务器之间的MySQL配置差异等。
|
||||
|
||||
解决方法:
|
||||
优化网络
|
||||
提高从服务器性能
|
||||
利用MySQL并行复制功能提升效率,减少延迟。https://blog.csdn.net/weixin_42587823/article/details/144842206
|
||||
219
src/content/posts/中间件/MySQL/共享锁和排他锁区别.md
Normal file
219
src/content/posts/中间件/MySQL/共享锁和排他锁区别.md
Normal file
@@ -0,0 +1,219 @@
|
||||
---
|
||||
title: MySQL共享锁和排他锁的区别
|
||||
published: 2025-07-18
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [mysql锁]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: 'zh-cn'
|
||||
---
|
||||
|
||||
# 共享锁和排他锁的区别
|
||||
|
||||
MySQL中的**共享锁(Shared Lock,简称S锁)**和**排他锁(Exclusive Lock,简称X锁)**是InnoDB存储引擎用于并发控制的两种锁机制,主要区别在于锁的兼容性和使用场景。以下是两者的详细对比:
|
||||
|
||||
### 1. **定义**
|
||||
|
||||
- **共享锁(S锁)**:允许多个事务同时对同一数据加共享锁,用于读取数据,防止其他事务修改数据,但允许多个事务同时读取。
|
||||
- **排他锁(X锁)**:只允许一个事务对数据加锁,用于修改数据,阻止其他事务对同一数据加任何锁(包括共享锁和排他锁)。
|
||||
|
||||
### 2. **锁的兼容性**
|
||||
|
||||
| 锁类型 | 共享锁(S锁) | 排他锁(X锁) |
|
||||
| ----------------- | ------------- | ------------- |
|
||||
| **共享锁(S锁)** | 兼容 | 不兼容 |
|
||||
| **排他锁(X锁)** | 不兼容 | 不兼容 |
|
||||
|
||||
- **共享锁**:多个事务可以同时持有同一数据的S锁,适合并发读取。
|
||||
- **排他锁**:一旦某事务持有X锁,其他事务无法对同一数据加S锁或X锁,必须等待锁释放。
|
||||
|
||||
### 3. **使用场景**
|
||||
|
||||
- **共享锁**:
|
||||
|
||||
- 用于只读操作,如`SELECT`查询。
|
||||
|
||||
- 典型场景:多个事务需要读取同一数据,但不修改(如报表查询)。
|
||||
|
||||
- 显式获取方式:`SELECT ... LOCK IN SHARE MODE`。
|
||||
|
||||
- 示例:
|
||||
允许多个事务同时读取`id = 1`的行,但阻止其他事务修改该行。
|
||||
|
||||
```sql
|
||||
SELECT * FROM users WHERE id = 1 LOCK IN SHARE MODE;
|
||||
|
||||
```
|
||||
|
||||
- **排他锁**:
|
||||
|
||||
- 用于写操作,如`UPDATE`、`DELETE`、`INSERT`。
|
||||
|
||||
- 典型场景:需要修改数据并确保数据一致性(如库存扣减、余额更新)。
|
||||
|
||||
- 显式获取方式:`SELECT ... FOR UPDATE`。
|
||||
|
||||
- 示例:
|
||||
锁定`id = 1`的行,阻止其他事务读取或修改,直到当前事务结束。
|
||||
|
||||
```sql
|
||||
SELECT * FROM users WHERE id = 1 FOR UPDATE;
|
||||
|
||||
```
|
||||
|
||||
### 4. **获取方式**
|
||||
|
||||
- **共享锁**:
|
||||
- 自动:某些情况下,InnoDB在`SELECT`查询时可能隐式加S锁(取决于隔离级别)。
|
||||
- 显式:`SELECT ... LOCK IN SHARE MODE`。
|
||||
- **排他锁**:
|
||||
- 自动:执行`UPDATE`、`DELETE`等写操作时,InnoDB自动为受影响的行加X锁。
|
||||
- 显式:`SELECT ... FOR UPDATE`。
|
||||
|
||||
### 5. **锁粒度**
|
||||
|
||||
- 两者都支持**行级锁**(InnoDB默认)和**表级锁**(如MyISAM或特定操作)。
|
||||
- 共享锁和排他锁在范围查询中可能涉及**间隙锁**或**下一键锁**(Next-Key Lock),用于防止幻读,具体取决于事务隔离级别(如`REPEATABLE READ`)。
|
||||
|
||||
### 6. **性能影响**
|
||||
|
||||
- **共享锁**:允许多个事务并发读取,适合读多写少的场景,阻塞较少。
|
||||
- **排他锁**:阻止其他事务读写,适合写操作,但可能导致阻塞和死锁,尤其在高并发场景下。
|
||||
|
||||
### 7. **典型应用场景对比**
|
||||
|
||||
- **共享锁**:多个用户同时查看商品库存、生成报表等。
|
||||
- **排他锁**:扣减库存、更新账户余额、防止并发修改导致数据不一致。
|
||||
|
||||
### 8. **死锁风险**
|
||||
|
||||
- **共享锁**:死锁风险较低,因为S锁之间兼容。
|
||||
- **排他锁**:死锁风险较高,多个事务竞争X锁可能导致互相等待,InnoDB会检测并回滚一个事务。
|
||||
|
||||
### 示例对比
|
||||
|
||||
假设有`products`表,字段包括`id`和`stock`:
|
||||
|
||||
```sql
|
||||
-- 事务A:读取库存(共享锁)
|
||||
BEGIN;
|
||||
SELECT stock FROM products WHERE id = 1 LOCK IN SHARE MODE;
|
||||
-- 其他事务可以同时读取,但不能修改
|
||||
COMMIT;
|
||||
|
||||
-- 事务B:扣减库存(排他锁)
|
||||
BEGIN;
|
||||
SELECT stock FROM products WHERE id = 1 FOR UPDATE;
|
||||
UPDATE products SET stock = stock - 1 WHERE id = 1;
|
||||
COMMIT;
|
||||
|
||||
```
|
||||
|
||||
- 事务A的共享锁允许其他事务读取`id = 1`的行,但阻止修改。
|
||||
- 事务B的排他锁阻止其他事务读取或修改`id = 1`的行,直到事务B结束。
|
||||
|
||||
### 总结
|
||||
|
||||
- **共享锁**适合读操作,允许多个事务并发读取,强调高并发读性能。
|
||||
- **排他锁**适合写操作,确保数据修改的独占性和一致性,但可能降低并发性能。
|
||||
- 在实际应用中,结合业务需求、索引优化和事务隔离级别(如`READ COMMITTED`或`REPEATABLE READ`)合理选择锁类型,以平衡一致性和性能。
|
||||
|
||||
# 排他锁
|
||||
|
||||
MySQL的排他锁(Exclusive Lock,简称X锁)是一种用于并发控制的锁机制,确保在同一时间只有一个事务可以修改特定数据,防止数据冲突和不一致。以下是对MySQL排他锁的详细讲解:
|
||||
|
||||
### 1. **什么是排他锁?**
|
||||
|
||||
排他锁是MySQL中用于写操作的锁类型。当一个事务对某行、表或数据对象加了排他锁后,其他事务无法对同一数据进行读(共享锁)或写(排他锁)操作,直到该锁被释放。这保证了数据修改的原子性和一致性。
|
||||
|
||||
- **特点**:
|
||||
- 排他锁与任何其他锁(包括共享锁和排他锁)都不兼容。
|
||||
- 持有排他锁的事务可以安全地修改数据,而不被其他事务干扰。
|
||||
- 常用于`UPDATE`、`DELETE`、`INSERT`等写操作。
|
||||
|
||||
### 2. **排他锁的工作机制**
|
||||
|
||||
在MySQL的InnoDB存储引擎中(默认支持事务和行级锁),排他锁主要通过以下方式实现:
|
||||
|
||||
- **行级锁**:锁住特定的行记录,只有被锁定的行无法被其他事务访问。
|
||||
- **表级锁**:在某些情况下(如表级操作或MyISAM引擎),锁住整个表。
|
||||
- **间隙锁(Gap Lock)和下一键锁(Next-Key Lock)**:用于防止幻读,锁定某个范围的索引记录(常见于范围查询)。
|
||||
|
||||
当一个事务执行写操作(如`UPDATE`或`DELETE`)时,InnoDB会自动为受影响的行加排他锁。例如:
|
||||
|
||||
```sql
|
||||
UPDATE users SET age = 30 WHERE id = 1;
|
||||
|
||||
```
|
||||
|
||||
MySQL会对`id = 1`的行加排他锁,直到事务提交(`COMMIT`)或回滚(`ROLLBACK`)才会释放锁。
|
||||
|
||||
### 3. **排他锁的获取方式**
|
||||
|
||||
- **隐式获取**:通过DML操作(如`UPDATE`、`DELETE`)自动加锁。例如:
|
||||
|
||||
```sql
|
||||
UPDATE table_name SET column = value WHERE condition;
|
||||
|
||||
```
|
||||
|
||||
InnoDB会自动为受影响的行加排他锁。
|
||||
|
||||
- **显式获取**:使用`SELECT ... FOR UPDATE`语句显式加排他锁。例如:
|
||||
|
||||
```sql
|
||||
SELECT * FROM users WHERE id = 1 FOR UPDATE;
|
||||
|
||||
```
|
||||
|
||||
这会锁定`id = 1`的行,阻止其他事务读取或修改该行,直到当前事务结束。
|
||||
|
||||
### 4. **排他锁的兼容性**
|
||||
|
||||
排他锁与其他锁的兼容性如下:
|
||||
|
||||
- **排他锁与排他锁**:不兼容,两个事务不能同时对同一数据加X锁。
|
||||
- **排他锁与共享锁(S锁)**:不兼容,持有X锁的数据无法被其他事务加S锁读取。
|
||||
- **结果**:排他锁会导致其他事务等待(阻塞),直到锁释放。
|
||||
|
||||
### 5. **排他锁的场景**
|
||||
|
||||
- **数据修改**:如`UPDATE`、`DELETE`操作,确保数据一致性。
|
||||
- **防止并发冲突**:在高并发场景下,避免多个事务同时修改同一行导致数据不一致。
|
||||
- **悲观锁机制**:通过`SELECT ... FOR UPDATE`实现悲观锁,适合需要严格控制并发访问的业务场景(如库存扣减)。
|
||||
|
||||
示例(库存扣减):
|
||||
|
||||
```sql
|
||||
BEGIN;
|
||||
SELECT stock FROM products WHERE id = 1 FOR UPDATE;
|
||||
-- 假设查询到stock=10
|
||||
UPDATE products SET stock = stock - 1 WHERE id = 1;
|
||||
COMMIT;
|
||||
|
||||
```
|
||||
|
||||
`FOR UPDATE`加排他锁,确保在事务期间其他事务无法修改`id = 1`的记录。
|
||||
|
||||
### 6. **可能的问题**
|
||||
|
||||
- **死锁**:当多个事务互相等待对方持有的排他锁时,可能发生死锁。InnoDB会自动检测死锁并回滚一个事务。
|
||||
- **性能影响**:排他锁会阻塞其他事务,可能降低并发性能,尤其在高并发场景下。
|
||||
- **锁范围过大**:若锁住的范围过大(例如表锁或范围查询的间隙锁),可能导致更多事务阻塞。
|
||||
|
||||
### 7. **如何优化排他锁的使用**
|
||||
|
||||
- **尽量使用行级锁**:确保查询条件使用索引,避免锁住过多行。
|
||||
- **缩短事务时间**:尽快提交或回滚事务,减少锁的持有时间。
|
||||
- **避免死锁**:按照固定顺序访问资源(如按表或主键顺序加锁)。
|
||||
- **选择合适的隔离级别**:如降低隔离级别(从`REPEATABLE READ`到`READ COMMITTED`),减少间隙锁的使用。
|
||||
|
||||
### 8. **与共享锁的对比**
|
||||
|
||||
- **共享锁(S锁)**:允许多个事务同时读取数据,但不允许修改。常用于`SELECT ... LOCK IN SHARE MODE`。
|
||||
- **排他锁(X锁)**:只允许一个事务修改数据,阻塞其他读写操作。
|
||||
|
||||
### 总结
|
||||
|
||||
MySQL的排他锁是确保数据写操作一致性的重要机制,广泛用于事务性操作。通过合理设计查询和事务,可以最大程度减少锁冲突和性能问题。在高并发场景下,建议结合索引优化、事务管理以及合适的隔离级别来平衡一致性和性能。
|
||||
62
src/content/posts/中间件/MySQL/分库分表场景.md
Normal file
62
src/content/posts/中间件/MySQL/分库分表场景.md
Normal file
@@ -0,0 +1,62 @@
|
||||
---
|
||||
title: 分库分表场景
|
||||
published: 2025-09-13
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['中间件','MySQL','分库分表']
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
# 分库分表
|
||||
|
||||
## 什么场景分库
|
||||
- 当单个数据库支持的连接数不足以满足客户端需求
|
||||
- 数据量超过了单个数据库实例的处理能力
|
||||
|
||||
## 什么场景分表
|
||||
- 单表数据量太大
|
||||
- 单表存在较高的写入场景
|
||||
- 当表中存在大量的TEXT,LONGTEXT 或者BLOB字段
|
||||
|
||||
## 什么场景分库分表
|
||||
- 高并发写入场景: 当应用面临高并发的写入请求的时候,单库单表无法满足需求,需要进行分库分表。
|
||||
- 海量数据场景: 当数据量非常大的时候,单库单表无法满足需求,需要进行分库分表。
|
||||
|
||||
## 分库分表的优缺点
|
||||
### 优点
|
||||
- 提高系统的性能和可扩展性
|
||||
- 提高系统的可用性和可靠性
|
||||
- 提高系统的可维护性
|
||||
|
||||
### 缺点
|
||||
- 增加系统的复杂性
|
||||
- 增加系统的成本
|
||||
- 增加系统的维护成本
|
||||
|
||||
|
||||
## 分库分表如何设计
|
||||
|
||||
我们分库分表,是有分片键的,这个分片键怎么用的呢?
|
||||
分片键是用来决定一条数据应该存储在哪个库或者表中的字段,它直接影响数据的分布,查询效率和系统扩展性。
|
||||
|
||||
举个例子:
|
||||
1. Hash分片
|
||||
原理: 对分片键的值进行哈希运算,然后对库或者表取模
|
||||
适用场景: 数据访问随机性强,读写均衡
|
||||
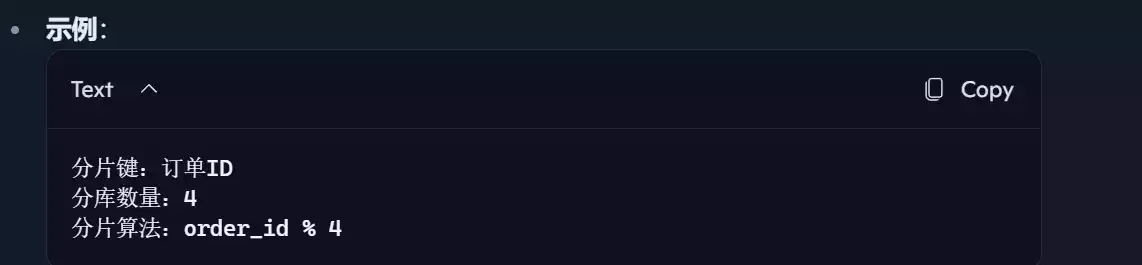
|
||||
|
||||
2. Range分片(范围分片)
|
||||
原理: 根据分片键的值范围划分数据
|
||||
使用场景: 时间序列数据,范围查询频繁
|
||||
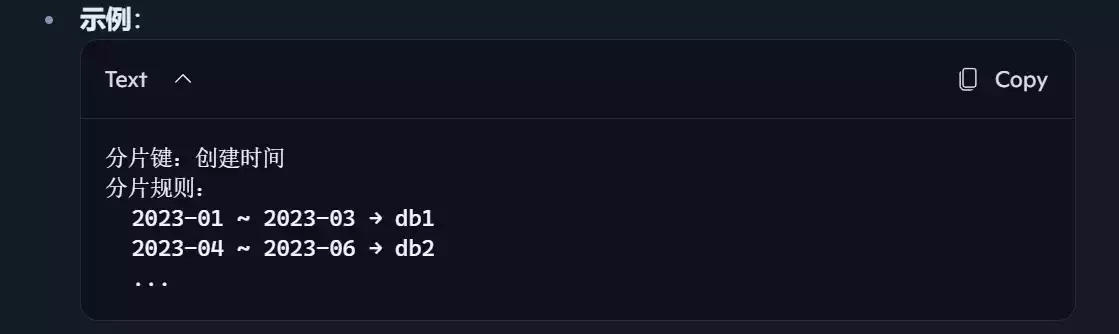
|
||||
|
||||
3. Lookup映射分片
|
||||
原理: 维护一个映射表,指定某个分片键值属于哪个分片
|
||||
使用场景: 分片键是枚举值,比如国家,地区等
|
||||
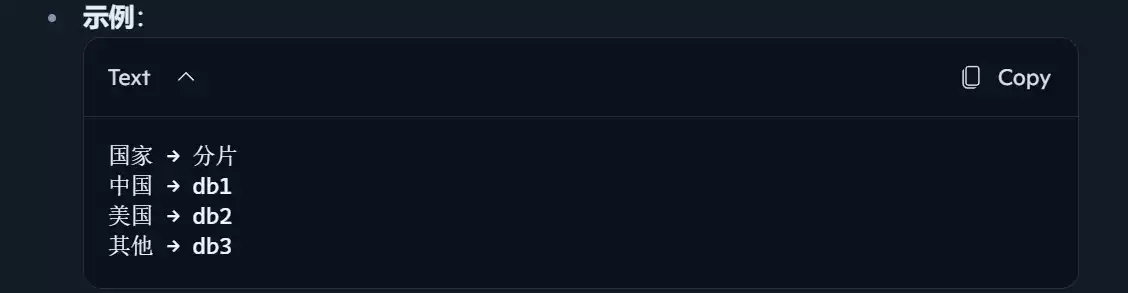
|
||||
|
||||
|
||||
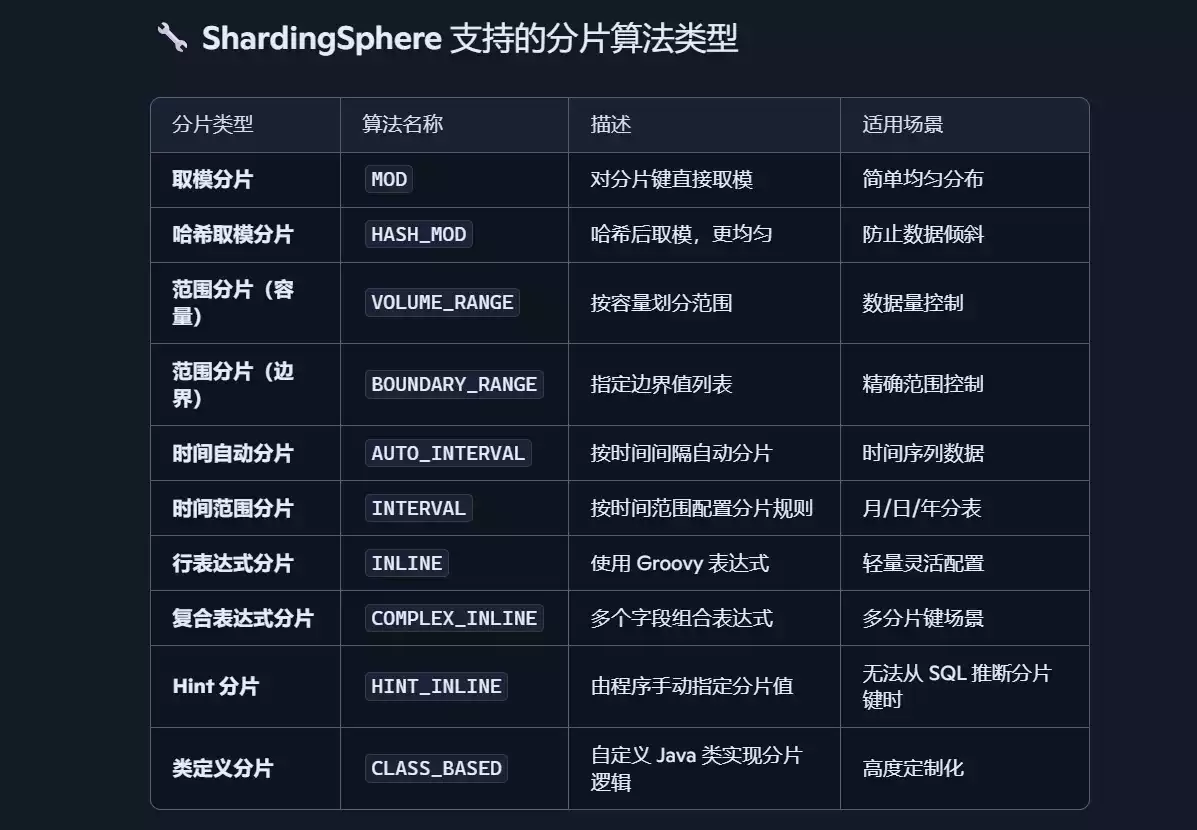
|
||||
26
src/content/posts/中间件/MySQL/如何处理MySQL的主从同步延迟.md
Normal file
26
src/content/posts/中间件/MySQL/如何处理MySQL的主从同步延迟.md
Normal file
@@ -0,0 +1,26 @@
|
||||
---
|
||||
title: 如何处理MySQL的主从同步延迟
|
||||
published: 2025-09-09
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['MySQL', '主从同步', '延迟']
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# 如何处理MySQL的主从同步延迟
|
||||
|
||||
当我们开启主从同步以后,这种延迟就是必然存在的,不论怎么优化都是没办法避免延迟的存在的,只能说去减少延迟的时间。
|
||||
|
||||
常见的解决方案:
|
||||
- 二次查询。如果说从库查不到数据,就去主库查一遍,用API封装这个逻辑就行,当作兜底策略。不过这样等于读的压力又转移到主库上去了,如果有人故意查询不存在的记录,那就会把查询的读请求都打到主库上了。
|
||||
- 强制把写之后立马读的操作转移到主库上(写后读主策略)。 写请求完成后,后续一段时间或者同一会话内的查询强制路由到主库,或者在从库追上指定位点前都读主。这个方法虽然简单可靠,能保证用户操作后的可见性,但是会增加主库的读压力,削弱负载分摊。
|
||||
- 关键业务读写都走主库。像我们用户注册这种,就可以读写主库,就不会出现说登录报用户不存在的问题了,这种访问量的频率也不高。
|
||||
- 使用缓存。 主库写入一行同步到缓存里面,这样查询的时候可以先查缓存,避免延迟,但是这样又有数据一致性问题了,我们就要去考虑数据库和缓存的数据一致性问题了。
|
||||
|
||||
|
||||
还有可能是 **主库的配置高,从库的配置低**,这样的话,也会导致主从同步延迟,我们可以提高从库的配置。
|
||||
|
||||
|
||||
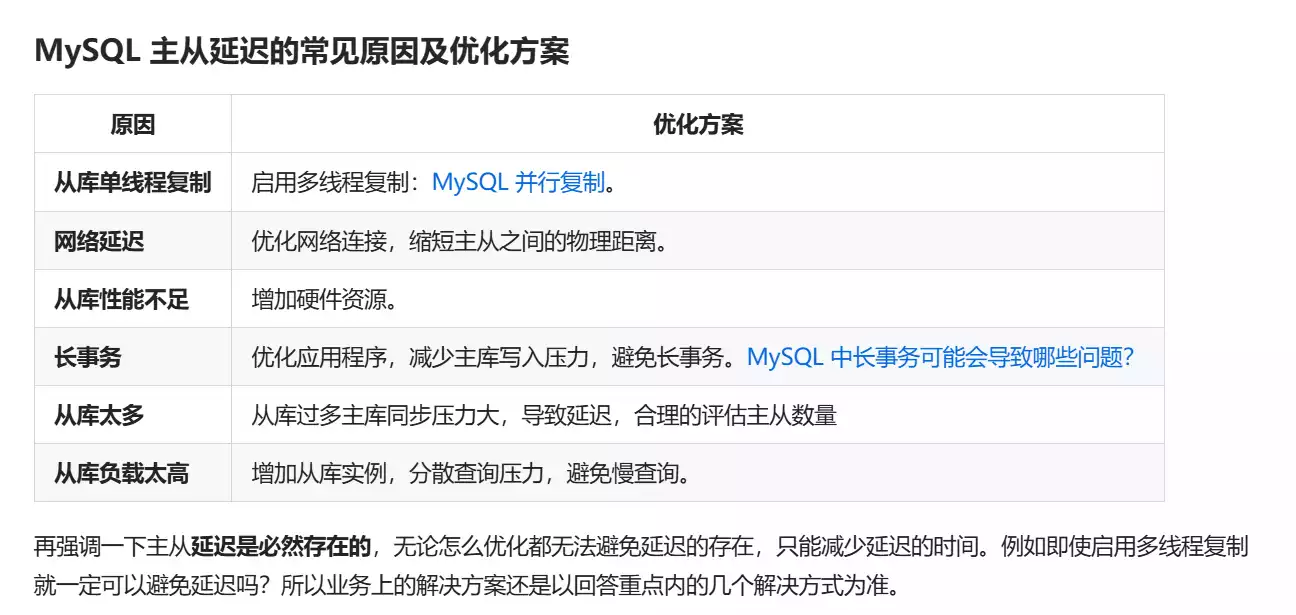
|
||||
313
src/content/posts/中间件/MySQL/搭建MySQL主从服务器.md
Normal file
313
src/content/posts/中间件/MySQL/搭建MySQL主从服务器.md
Normal file
@@ -0,0 +1,313 @@
|
||||
---
|
||||
title: 搭建MySQL主从服务器
|
||||
published: 2025-09-09
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['MySQL', '主从同步']
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# 买服务器
|
||||
|
||||
先买两台服务器,装ubuntu系统
|
||||
|
||||
# 安装mysql
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
# 修改配置,让两个服务器能够互相连接
|
||||

|
||||
|
||||
## 开启监听
|
||||
root@ecs-f95f-0002:/etc/mysql/mysql.conf.d# vim mysqld.cnf
|
||||
|
||||
|
||||
|
||||
修改从库
|
||||
|
||||
|
||||
root@ecs-f95f-0001:/etc/mysql/mysql.conf.d# sudo systemctl restart mysql
|
||||
root@ecs-f95f-0002:/etc/mysql/mysql.conf.d# sudo systemctl restart mysql
|
||||
|
||||
|
||||
重启一下主库和从库的mysql
|
||||
|
||||
|
||||
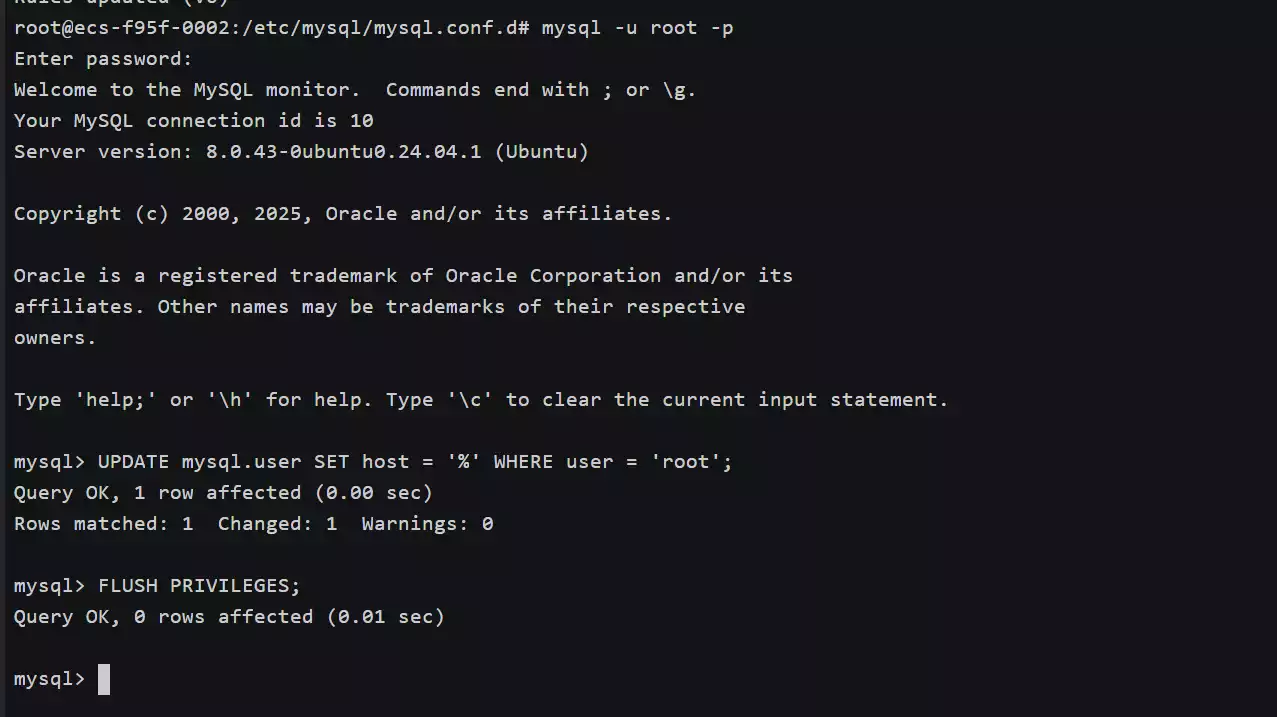
|
||||
|
||||
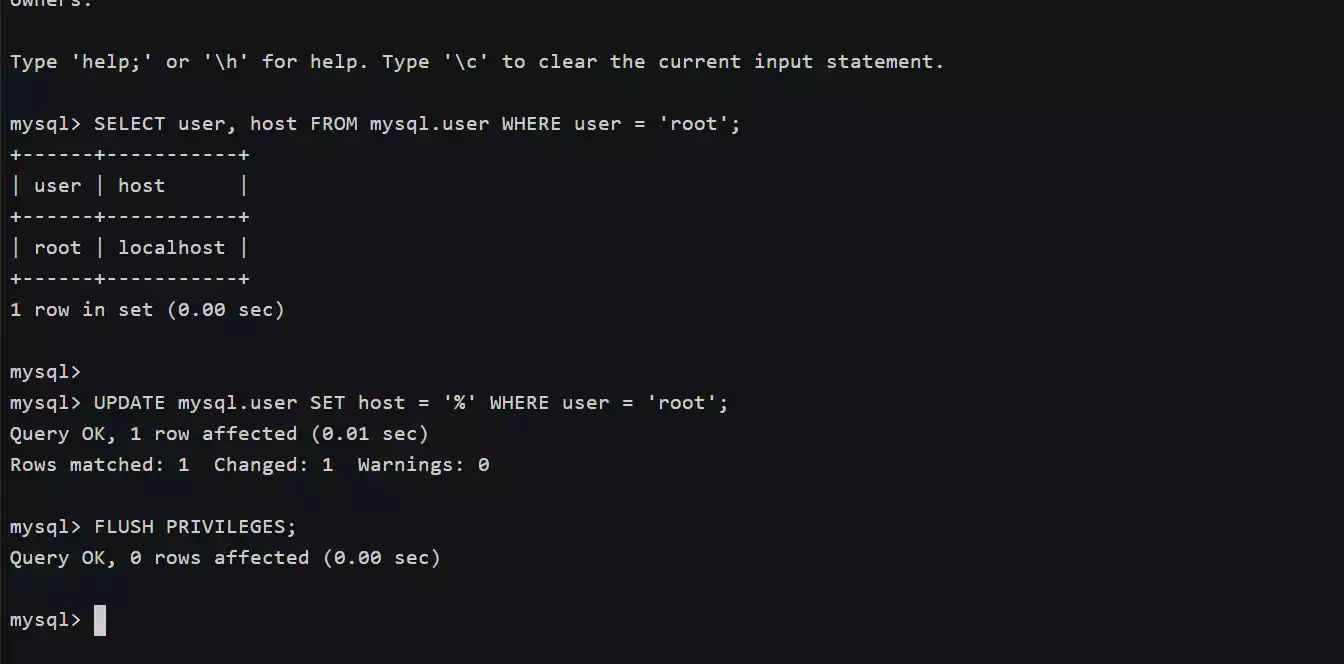
|
||||
|
||||
## 为root开启远程访问
|
||||
|
||||
mysql> ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'root';
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
mysql> FLUSH PRIVILEGES;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
启用密码验证
|
||||
|
||||
|
||||
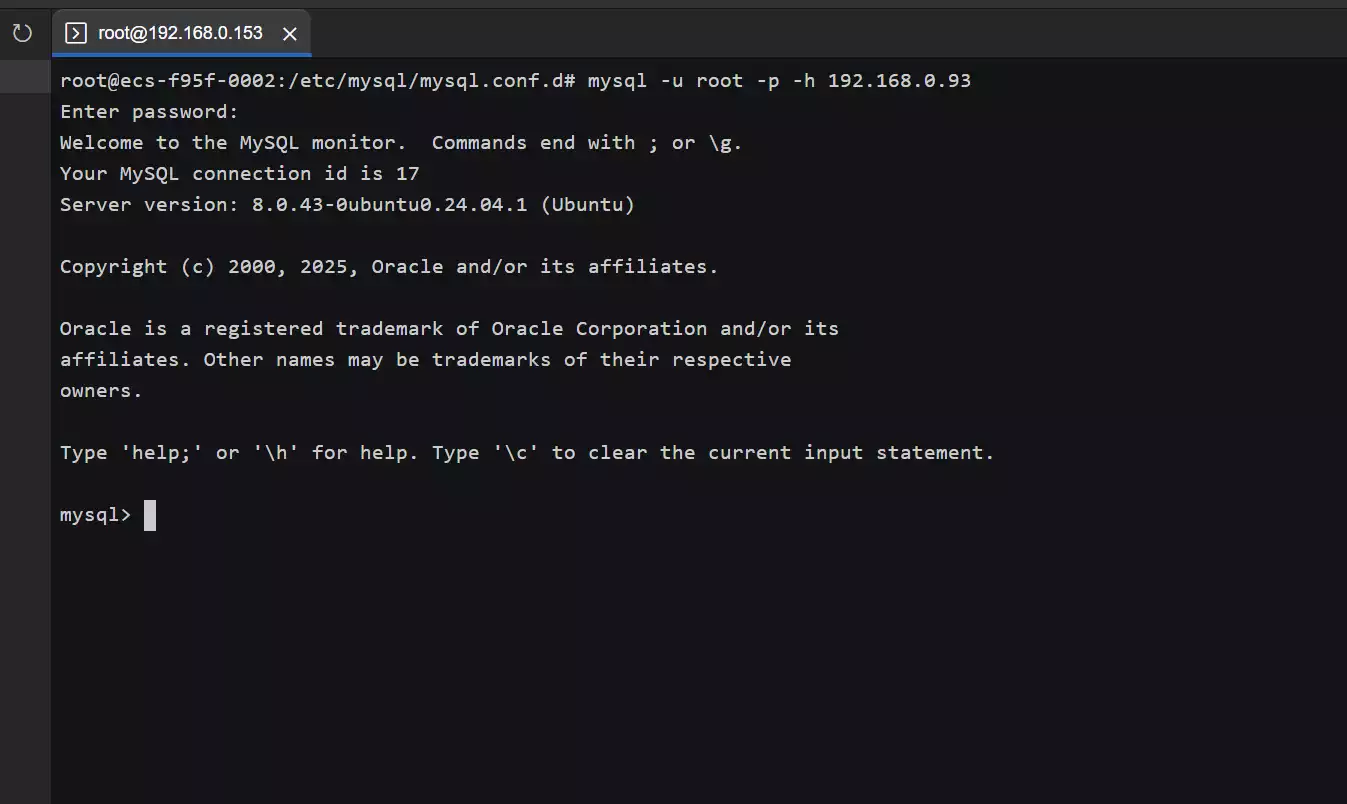
|
||||
|
||||
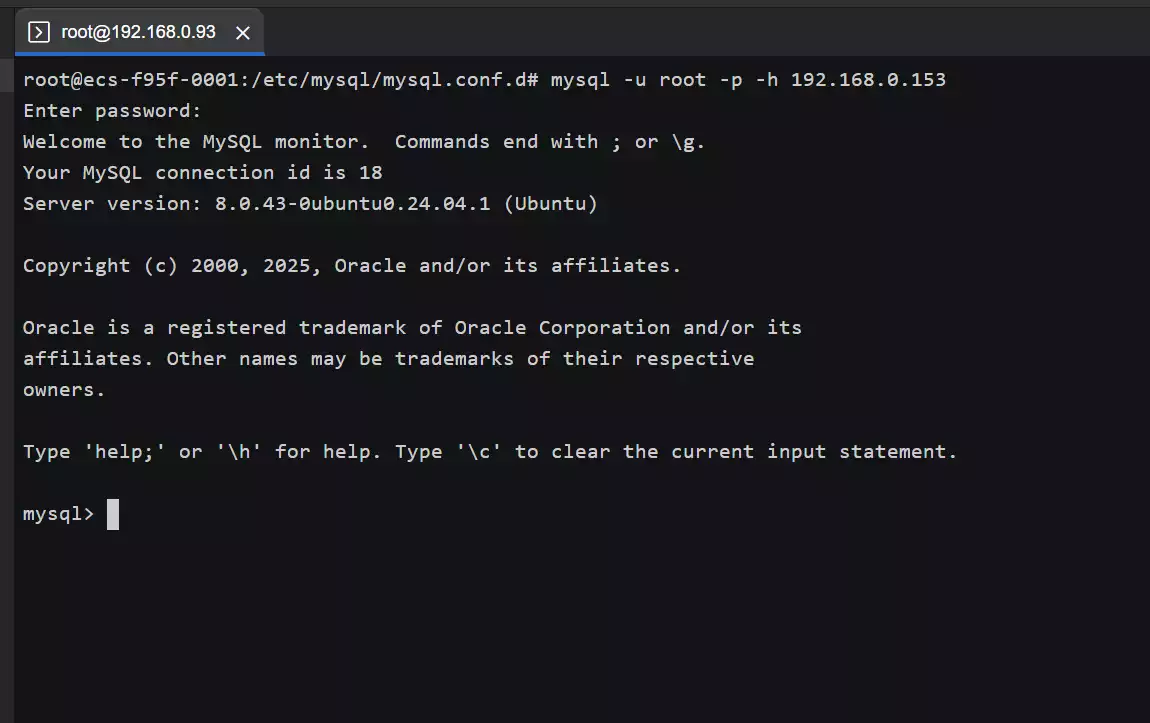
|
||||
|
||||
现在可以连接上了
|
||||
|
||||
|
||||
## 修改主库配置
|
||||
```
|
||||
[mysqld]
|
||||
server-id = 153
|
||||
# 启用二进制日志功能,这是复制的基础
|
||||
log-bin = /var/log/mysql/mysql-bin.log
|
||||
# (可选) 设置二进制日志的格式,建议使用ROW格式,可以更好地保证数据一致性
|
||||
binlog_format = ROW
|
||||
binlog_ignore_db = mysql
|
||||
|
||||
```
|
||||
|
||||
## 创建远程用户
|
||||
```sql
|
||||
-- 创建远程用户
|
||||
CREATE USER 'repl_user'@'%' IDENTIFIED WITH mysql_native_password BY 'remote';
|
||||
-- 给予复制权限
|
||||
GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'%';
|
||||
|
||||
-- 刷新权限
|
||||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
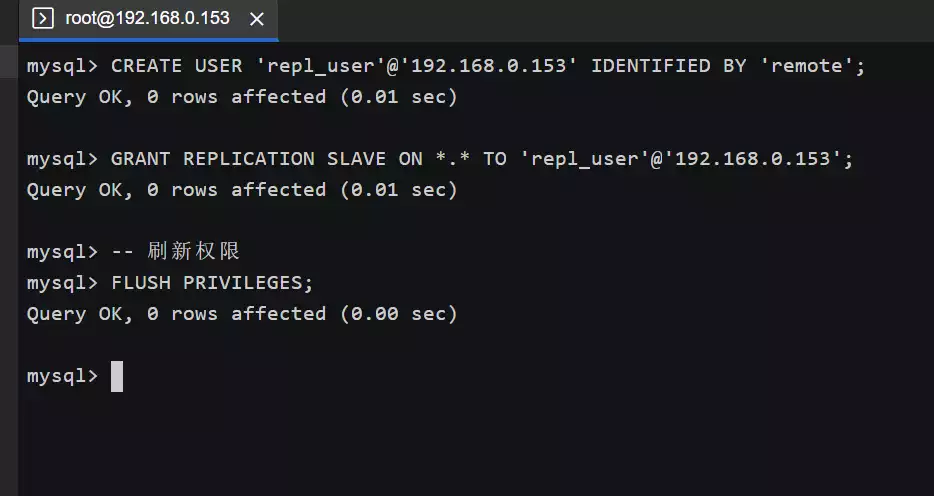
|
||||
|
||||
```sql
|
||||
-- 锁定所有表,防止新的数据写入,确保数据一致性
|
||||
FLUSH TABLES WITH READ LOCK;
|
||||
|
||||
-- 查看主服务器状态
|
||||
SHOW MASTER STATUS;
|
||||
```
|
||||
|
||||
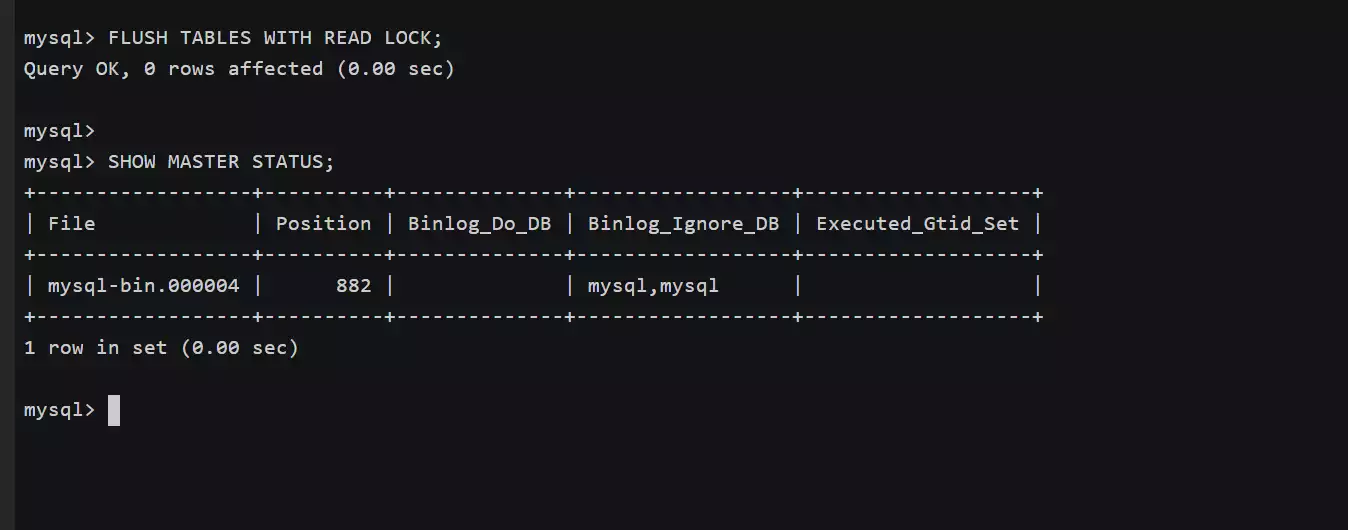
|
||||
|
||||
|
||||
## 备份主数据库,传到从服务器
|
||||
|
||||
```bash
|
||||
mysqldump -u root -p --all-databases --source-data > ./master_backup.sql
|
||||
```
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
创建密钥
|
||||
```bash
|
||||
ssh-keygen -t rsa -b 4096
|
||||
```
|
||||
|
||||
密钥创建好以后,把公钥放到从服务器
|
||||
```bash
|
||||
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.93
|
||||
```
|
||||
|
||||
|
||||
|
||||
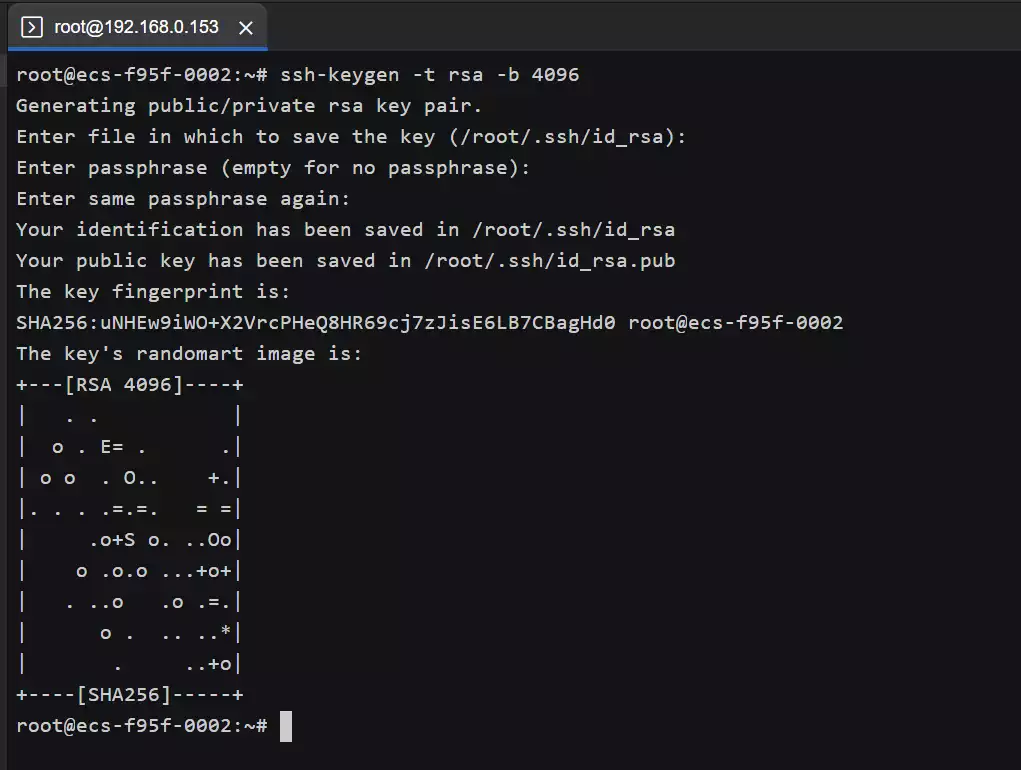
|
||||
|
||||
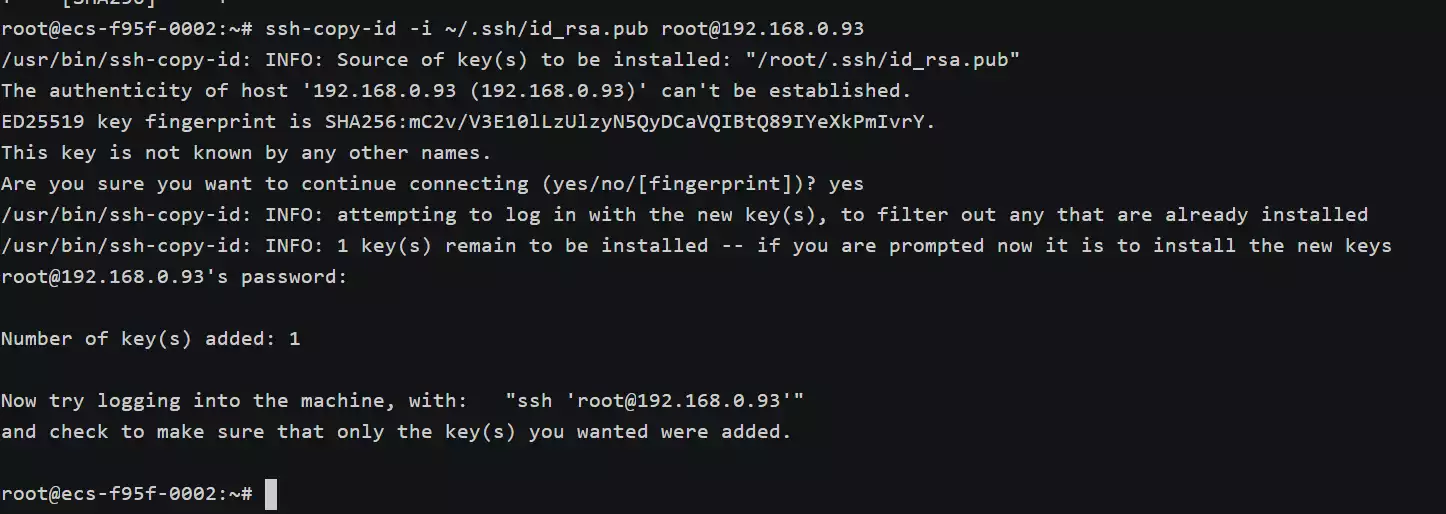
|
||||
|
||||
```
|
||||
Host mysql-slave
|
||||
HostName 192.168.0.93
|
||||
User root
|
||||
Port 22
|
||||
IdentityFile ~/.ssh/id_rsa
|
||||
```
|
||||
|
||||
|
||||
|
||||
从服务器配置:
|
||||
```bash
|
||||
ssh-keygen -t rsa -b 4096
|
||||
```
|
||||
```bash
|
||||
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.153
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```
|
||||
Host mysql-master
|
||||
HostName 192.168.0.153
|
||||
User root
|
||||
Port 22
|
||||
IdentityFile ~/.ssh/id_rsa
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
从主服务器上把备份好的数据库传到从库上
|
||||
```
|
||||
root@ecs-f95f-0002:~# scp master_backup.sql mysql-slave:~
|
||||
master_backup.sql
|
||||
```
|
||||
|
||||
从库已经可以看到了
|
||||
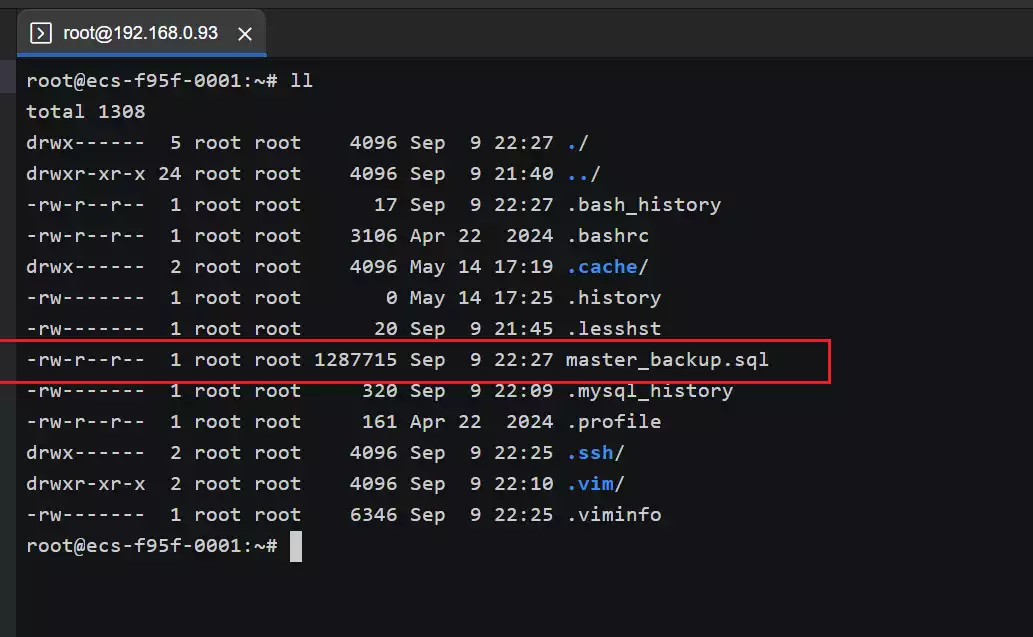
|
||||
|
||||
导入
|
||||
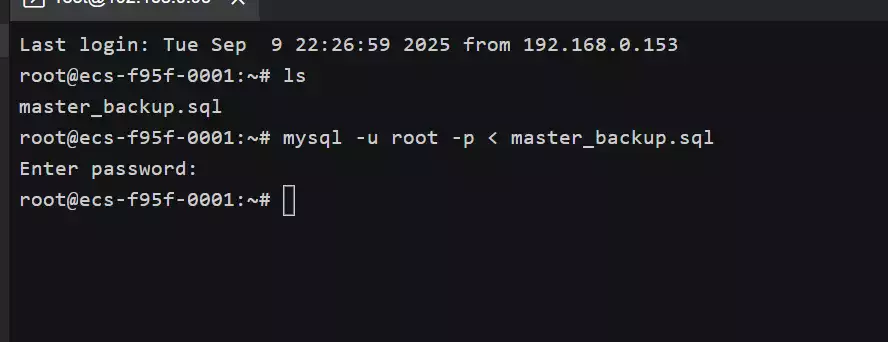
|
||||
|
||||
|
||||
主库解锁
|
||||
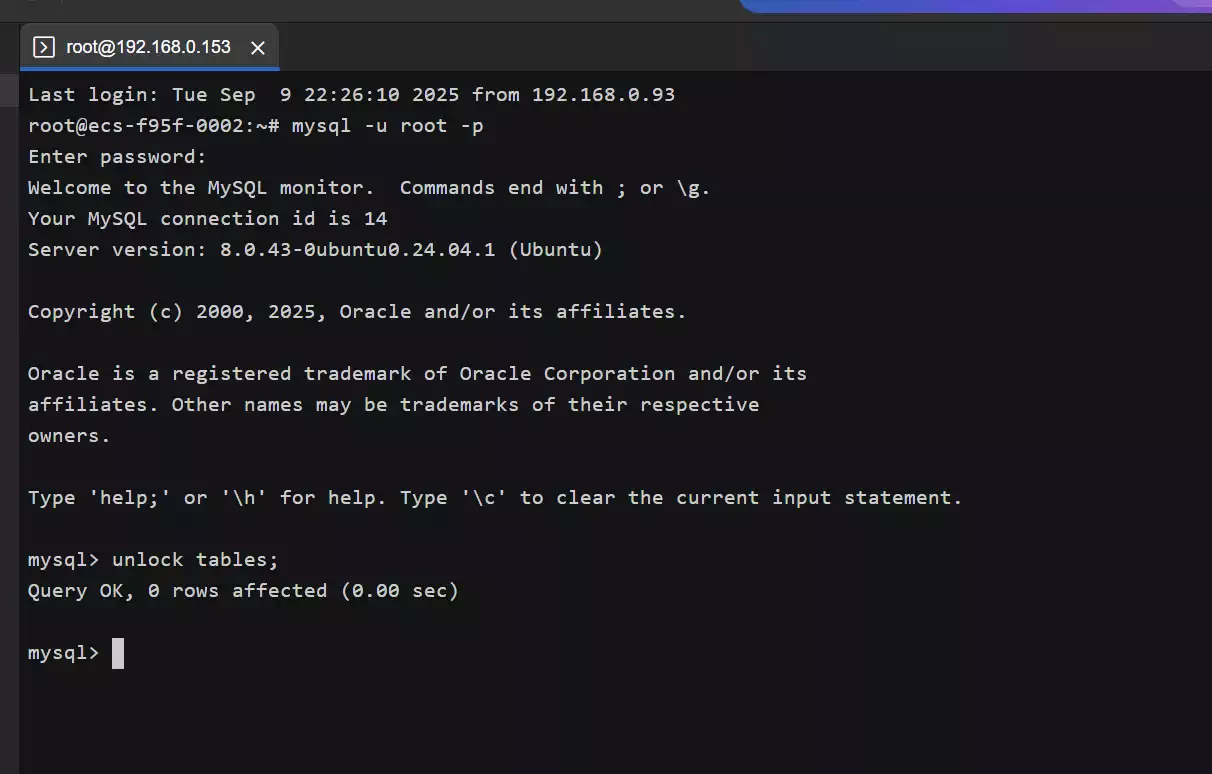
|
||||
|
||||
|
||||
从库mysql配置文件
|
||||
```
|
||||
[mysqld]
|
||||
server-id = 93
|
||||
relay-log = /var/log/mysql/mysql-relay-bin
|
||||
read-only = 1
|
||||
# (可选但推荐) 记录从服务器的数据更改到自己的二进制日志,以便将来可以作为其他从服务器的主服务器
|
||||
log-bin = /var/log/mysql/mysql-bin.log
|
||||
```
|
||||
|
||||
重启从库并且登录从库
|
||||
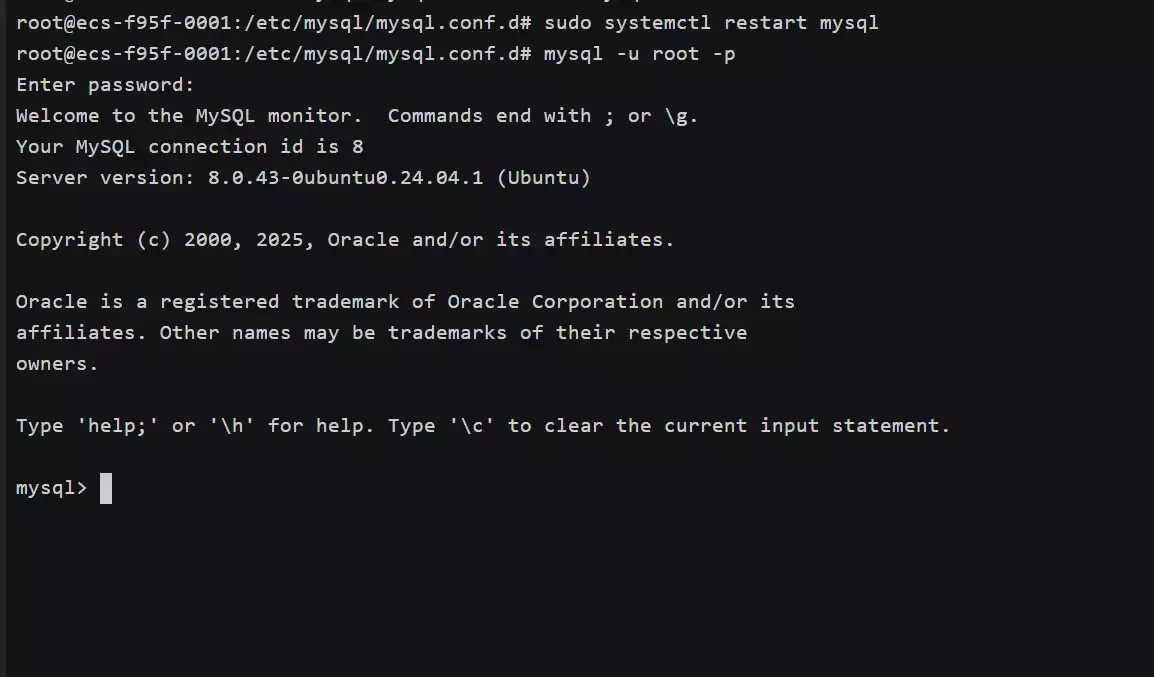
|
||||
|
||||
```sql
|
||||
stop slave;
|
||||
CHANGE MASTER TO
|
||||
MASTER_HOST = '192.168.0.153',
|
||||
MASTER_USER = 'repl_user',
|
||||
MASTER_PASSWORD = 'remote',
|
||||
MASTER_LOG_FILE = 'mysql-bin.000005',
|
||||
MASTER_LOG_POS = 157;
|
||||
START SLAVE;
|
||||
```
|
||||
|
||||
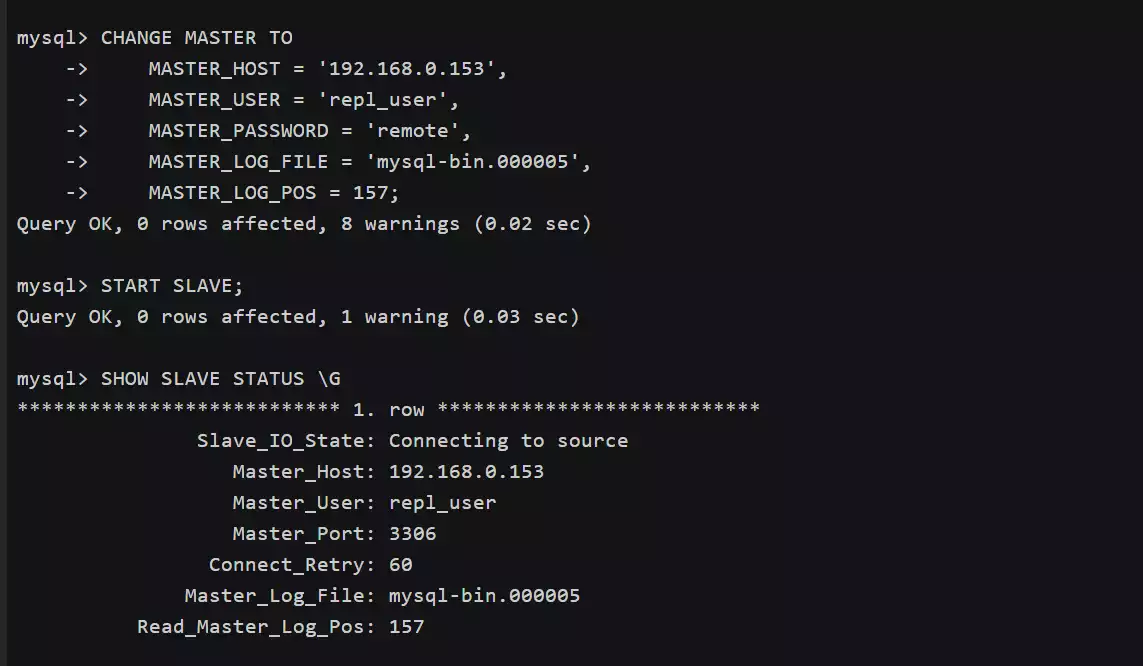
|
||||
|
||||
```
|
||||
|
||||
mysql> show slave status \G;
|
||||
*************************** 1. row ***************************
|
||||
Slave_IO_State: Waiting for source to send event
|
||||
Master_Host: 192.168.0.153
|
||||
Master_User: repl_user
|
||||
Master_Port: 3306
|
||||
Connect_Retry: 60
|
||||
Master_Log_File: mysql-bin.000005
|
||||
Read_Master_Log_Pos: 1826
|
||||
Relay_Log_File: mysql-relay-bin.000002
|
||||
Relay_Log_Pos: 326
|
||||
Relay_Master_Log_File: mysql-bin.000005
|
||||
Slave_IO_Running: Yes
|
||||
Slave_SQL_Running: Yes
|
||||
Replicate_Do_DB:
|
||||
Replicate_Ignore_DB:
|
||||
Replicate_Do_Table:
|
||||
Replicate_Ignore_Table:
|
||||
Replicate_Wild_Do_Table:
|
||||
Replicate_Wild_Ignore_Table:
|
||||
Last_Errno: 0
|
||||
Last_Error:
|
||||
Skip_Counter: 0
|
||||
Exec_Master_Log_Pos: 1826
|
||||
Relay_Log_Space: 536
|
||||
Until_Condition: None
|
||||
Until_Log_File:
|
||||
Until_Log_Pos: 0
|
||||
Master_SSL_Allowed: No
|
||||
Master_SSL_CA_File:
|
||||
Master_SSL_CA_Path:
|
||||
Master_SSL_Cert:
|
||||
Master_SSL_Cipher:
|
||||
Master_SSL_Key:
|
||||
Seconds_Behind_Master: 0
|
||||
Master_SSL_Verify_Server_Cert: No
|
||||
Last_IO_Errno: 0
|
||||
Last_IO_Error:
|
||||
Last_SQL_Errno: 0
|
||||
Last_SQL_Error:
|
||||
Replicate_Ignore_Server_Ids:
|
||||
Master_Server_Id: 153
|
||||
Master_UUID: 014654cd-8d83-11f0-b940-fa163e8fe780
|
||||
Master_Info_File: mysql.slave_master_info
|
||||
SQL_Delay: 0
|
||||
SQL_Remaining_Delay: NULL
|
||||
Slave_SQL_Running_State: Replica has read all relay log; waiting for more updates
|
||||
Master_Retry_Count: 86400
|
||||
Master_Bind:
|
||||
Last_IO_Error_Timestamp:
|
||||
Last_SQL_Error_Timestamp:
|
||||
Master_SSL_Crl:
|
||||
Master_SSL_Crlpath:
|
||||
Retrieved_Gtid_Set:
|
||||
Executed_Gtid_Set:
|
||||
Auto_Position: 0
|
||||
Replicate_Rewrite_DB:
|
||||
Channel_Name:
|
||||
Master_TLS_Version:
|
||||
Master_public_key_path:
|
||||
Get_master_public_key: 0
|
||||
Network_Namespace:
|
||||
1 row in set, 1 warning (0.00 sec)
|
||||
|
||||
ERROR:
|
||||
No query specified
|
||||
```
|
||||
|
||||
|
||||
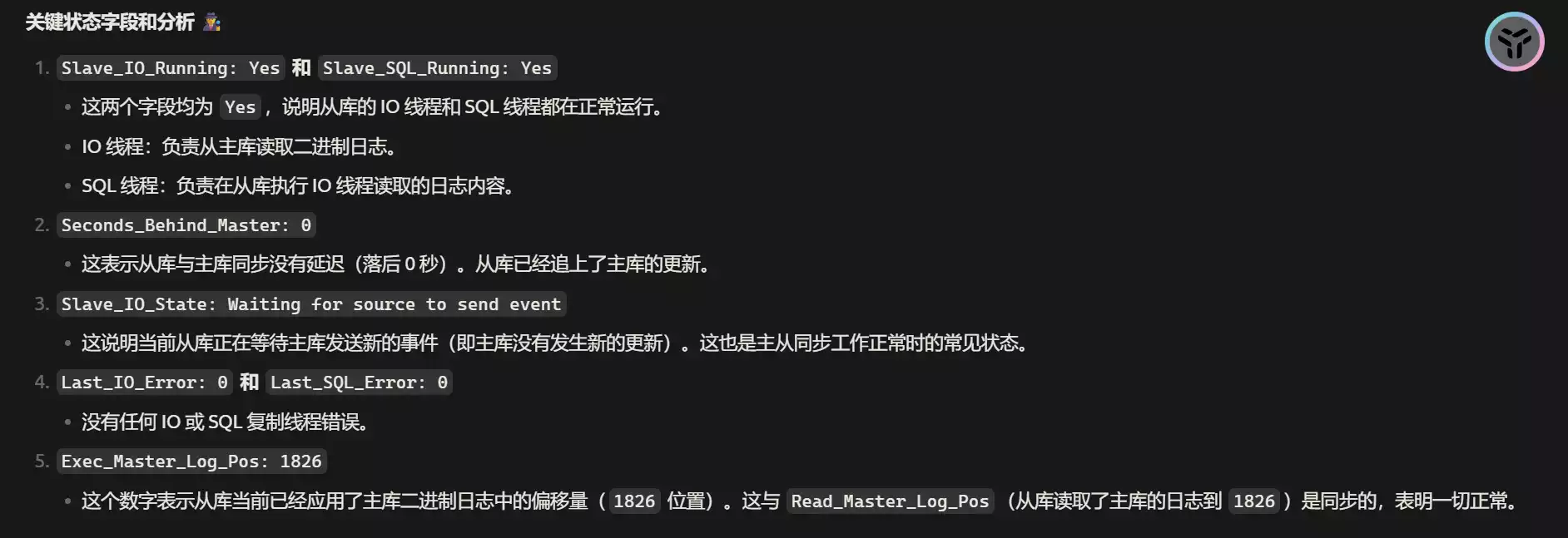
|
||||
|
||||
在主库里面
|
||||
创建库,表,插入数据
|
||||
```sql
|
||||
-- 创建 UTF8MB4 数据库
|
||||
CREATE DATABASE testdb
|
||||
CHARACTER SET utf8mb4
|
||||
COLLATE utf8mb4_general_ci;
|
||||
|
||||
use testdb;
|
||||
CREATE TABLE user_data (
|
||||
id INT AUTO_INCREMENT PRIMARY KEY, -- 主键,自动递增
|
||||
username VARCHAR(255) NOT NULL, -- 用户名,最大长度255
|
||||
comment TEXT CHARACTER SET utf8mb4 -- 评论,支持存储表情符号和其他Unicode字符
|
||||
) ENGINE=InnoDB CHARSET=utf8mb4;
|
||||
|
||||
-- 插入常规数据
|
||||
INSERT INTO user_data (username, comment) VALUES ('Alice', 'Hello, world!');
|
||||
|
||||
-- 插入带表情符号的数据
|
||||
INSERT INTO user_data (username, comment) VALUES ('Bob', 'This is fun! 😊');
|
||||
|
||||
-- 插入中文字符
|
||||
INSERT INTO user_data (username, comment) VALUES ('Charlie', '你好,世界!');
|
||||
|
||||
-- 插入混合内容
|
||||
INSERT INTO user_data (username, comment) VALUES ('David', '中文+Emoji 🌟😄');
|
||||
|
||||
```
|
||||
|
||||
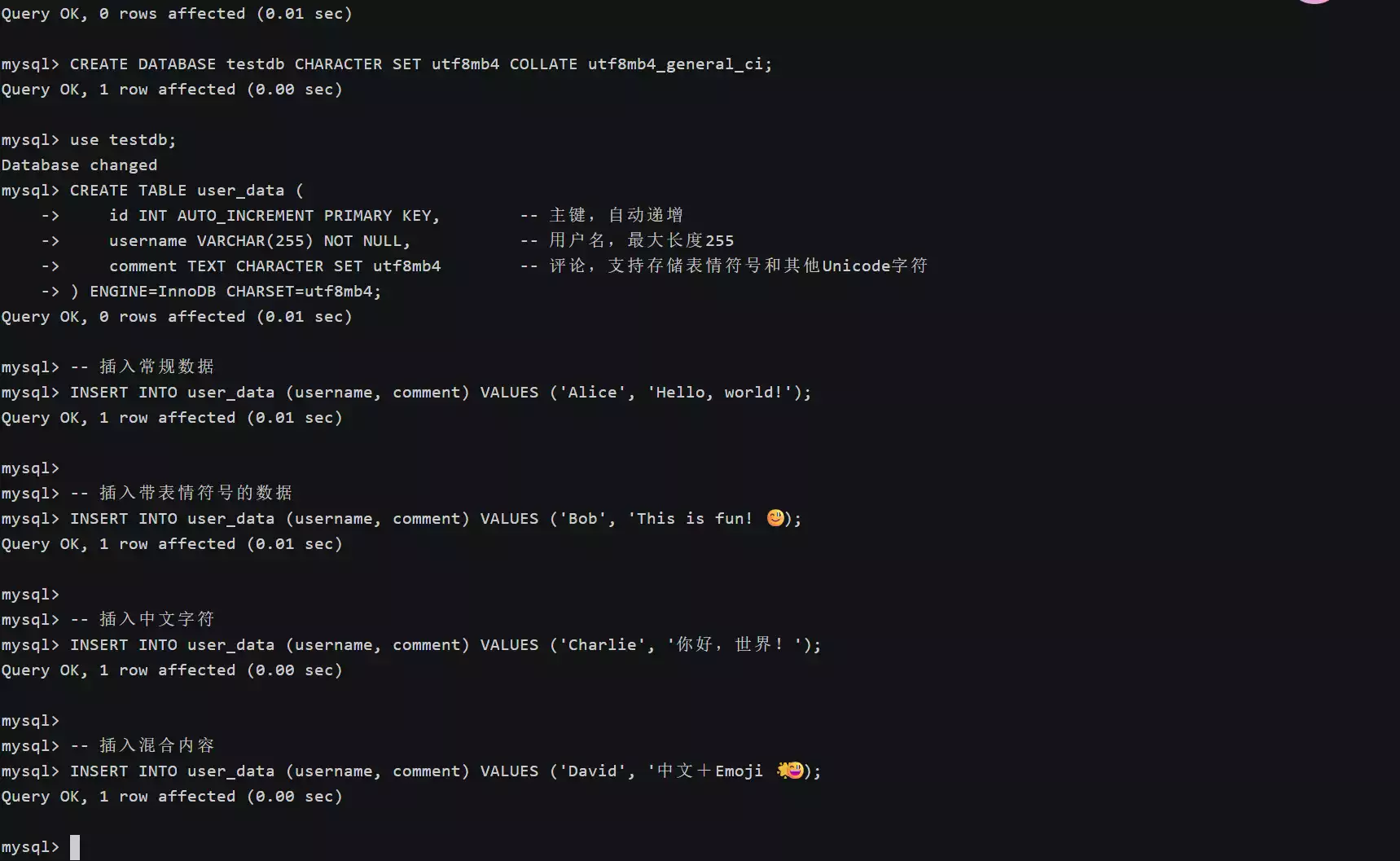
|
||||
|
||||
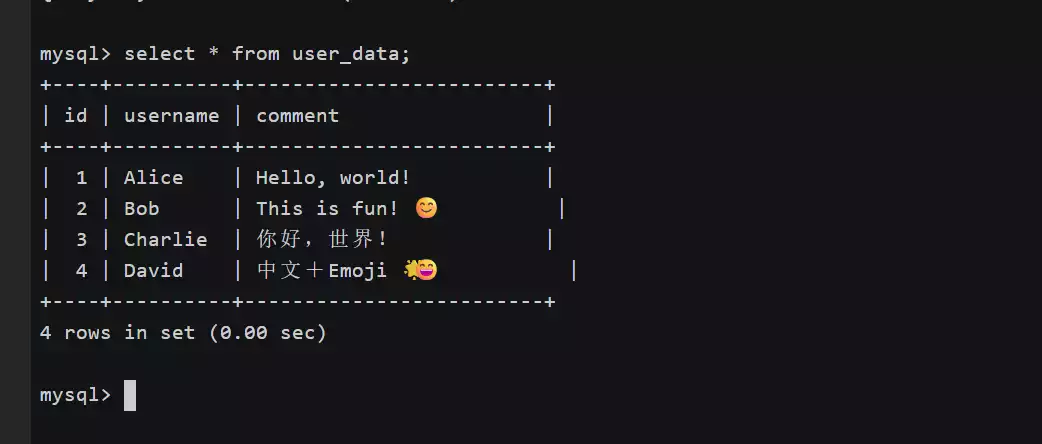
|
||||
|
||||
接下来我们看看从库状态
|
||||
|
||||
|
||||
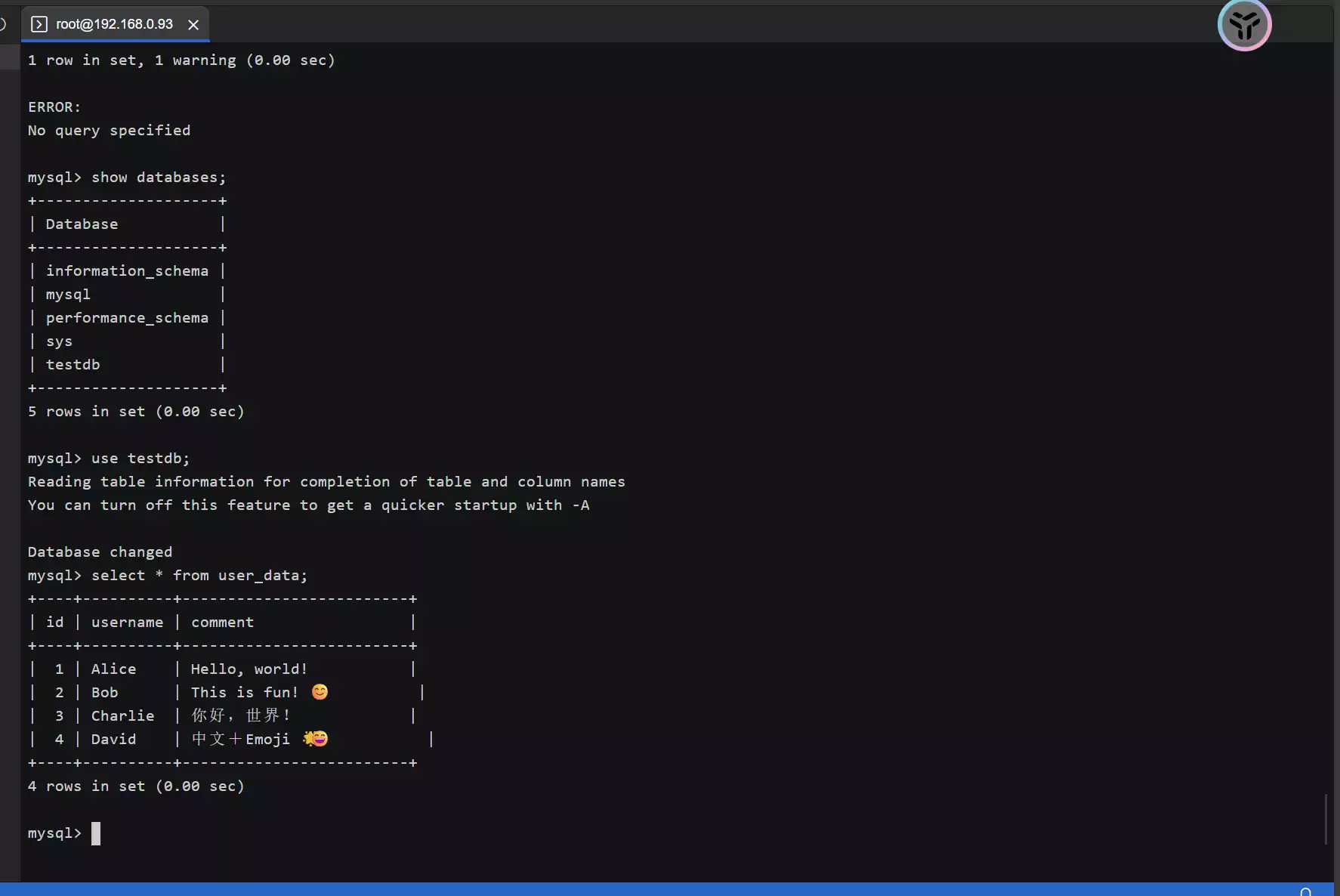
|
||||
69
src/content/posts/中间件/MySQL/数据库ACID四大特性.md
Normal file
69
src/content/posts/中间件/MySQL/数据库ACID四大特性.md
Normal file
@@ -0,0 +1,69 @@
|
||||
---
|
||||
title: 数据库ACID四大特性
|
||||
published: 2025-08-07
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [ACID,四大特性]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
# 什么是ACID四大特性
|
||||
A : Atomicity(原子性)
|
||||
C : Consistency(一致性)
|
||||
I : Isolation(隔离性)
|
||||
D : Durability(持久性)
|
||||
|
||||

|
||||
|
||||
# Atomicity(原子性)
|
||||
这里要先讲一下什么是事务: 简单说,事务就是一组原子性的SQL执行单元。如果数据库引擎能够成功地对数据库应 用该组査询的全部语句,那么就执行该组SQL。如果其中有任何一条语句因为崩溃或其 他原因无法执行,那么所有的语句都不会执行。要么全部执行成功(commit),要么全部执行失败(rollback)。
|
||||
|
||||
**原子性指的是一个事务中所有操作要么全部成功要么全部失败。**
|
||||
|
||||
# Consistency(一致性)
|
||||
数据库的一致性指的是: 每个事务必须使数据库从一个合法的状态,转变到另一个合法的状态,并且在事务执行前后,数据库的各种完整性约束都得以保持。
|
||||
|
||||
什么是完整性约束呢?
|
||||
完整性约束是指数据库中数据的规则和限制,比如主键约束、外键约束、唯一性约束等。
|
||||
主键约束: 确保每条记录都有唯一标识。
|
||||
外键约束: 确保数据之间的引用关系正确。
|
||||
唯一性约束: 确保某列的值在表中是唯一的
|
||||
|
||||
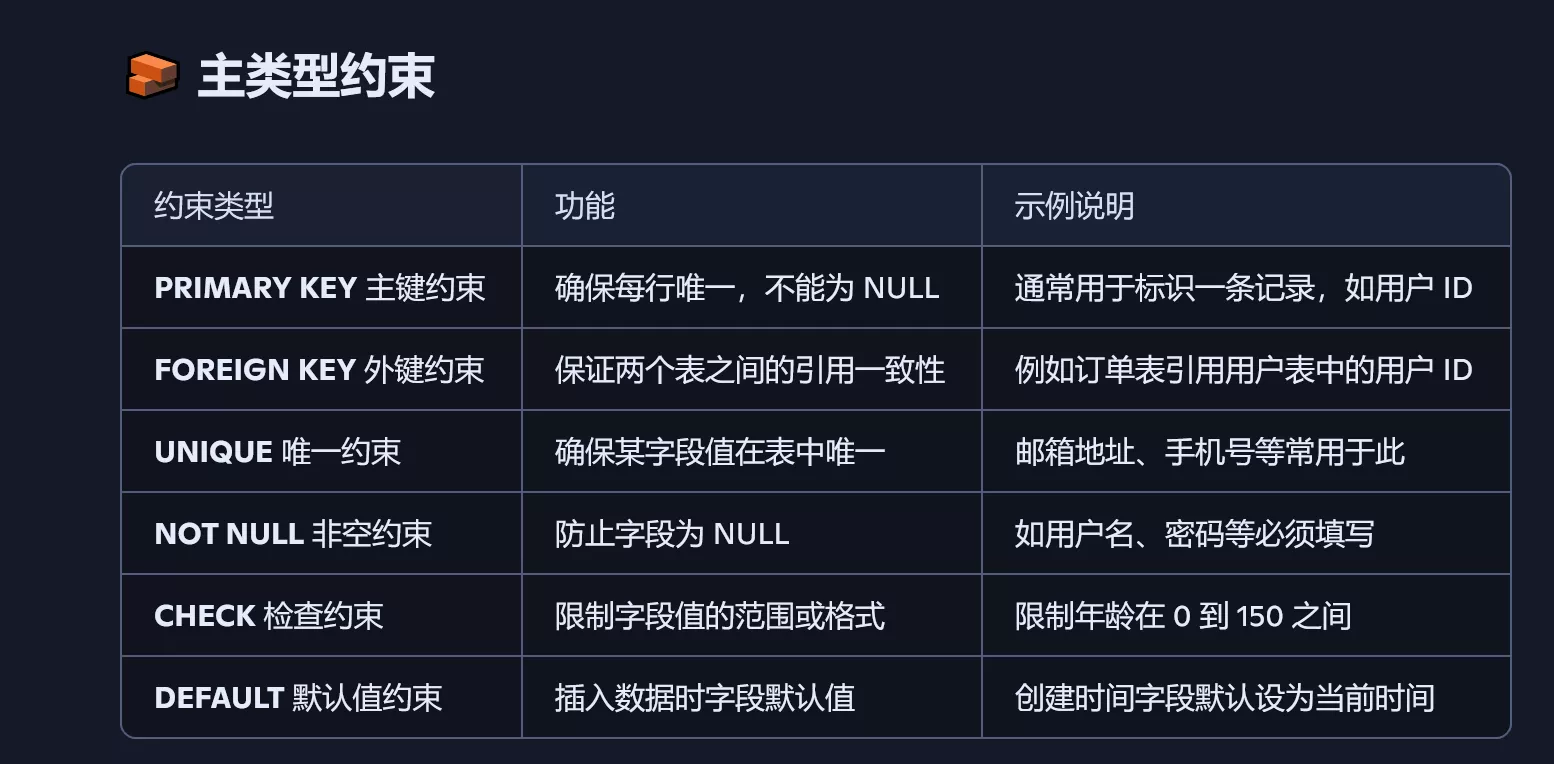
|
||||
|
||||
举个例子:
|
||||
当我们向订单表插入一条记录的时候,如果指定的`customer_id`在客户表中不存在,那么这个事务就不应该被提交,因为这会破坏数据的一致性。因此,外键约束会阻止事务提交,确保数据库的一致性。抛出外键约束异常
|
||||
|
||||
|
||||
# Isolation(隔离性)
|
||||
数据库的隔离性指的是: 每个事务的执行都应该是独立的,互不干扰。即使多个事务同时执行,也不会影响彼此的结果。
|
||||
隔离性确保了事务之间的独立性,防止了脏读、不可重复读和幻读等问题。
|
||||
|
||||
如果没有隔离性,在多个用户并发访问数据库的情况下,可能会出现以下问题:
|
||||
- 脏读(Dirty Read):
|
||||
一个事务读取到另一个事务尚未提交的修改,如果该事务回滚,那么读取到的就是无效数据。
|
||||
- 不可重复读(Non-repeatable Read):
|
||||
一个事务在同一事务内多次读取同一数据,却得到不同的结果,这是因为其他事务修改并提交了数据。
|
||||
- 幻读(Phantom Read):
|
||||
一个事务在同一事务内多次执行相同的查询,但是每次查询返回的结果集不同,这是因为其他事务插入或删除了数据。
|
||||
|
||||
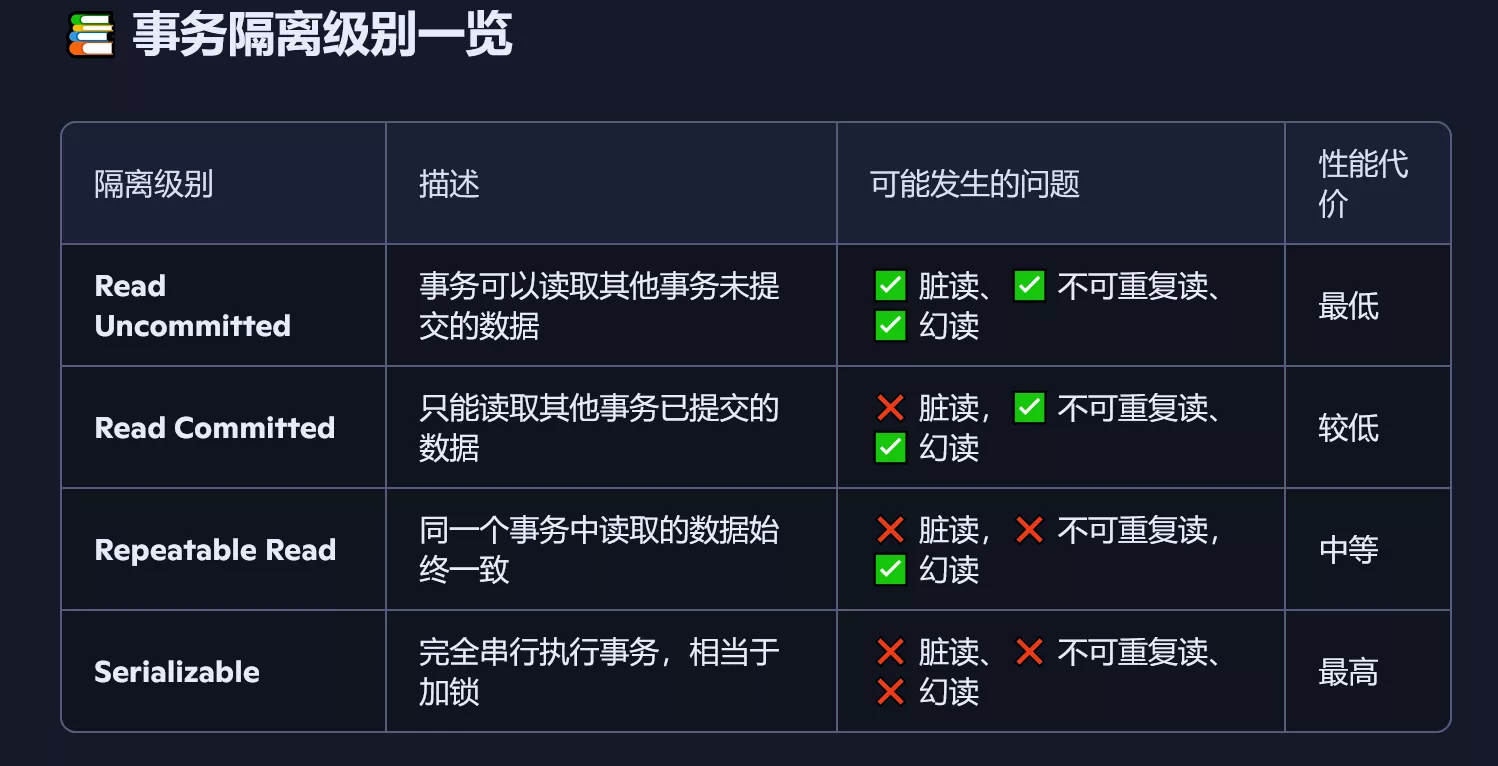
|
||||
|
||||
事务隔离级别:
|
||||
- 读未提交 >> 事务可以读取其他事务未提交的数据,可能会导致脏读。
|
||||
- 读已提交 >> 事务只能读取已提交的数据,防止脏读。
|
||||
- 可重复读 >> 事务在执行期间多次读取同一数据,结果保持一致,防止不可重复读。
|
||||
- 串行化 >> 事务完全隔离,按顺序执行,防止幻读。
|
||||
|
||||
|
||||
数据库的默认隔离级别是**可重复读(Repeatable Read)**,它可以防止脏读和不可重复读,但可能会出现幻读。(也就是无法避免读取数据的时候,其他事务提交新的数据或者删除数据,导致查询的结果集发生变化。
|
||||
|
||||
> 之前老把幻读和不可重复读搞混,现在再讲一下,所谓幻读,就是说读取数据过程中,另外一个数据库事务插入或者删除了数据,导致查询的数据结果集发生变化。而不可重复读是指在同一个事务中多次读取同一个数据,期间其他事务修改了数据,导致数据结果集不一致。
|
||||
|
||||
每个隔离级别都提供了不同程度的隔离性和性能,具体选择取决于应用场景和需求。
|
||||
# Durability(持久性)
|
||||
数据库的持久性指的是: 一旦事务提交,对数据库的修改就会永久保存,即使系统崩溃也不会丢失。
|
||||
持久性确保了数据的可靠性和稳定性,即使在系统故障或崩溃后,已提交的事务数据仍然可以恢复。
|
||||
41
src/content/posts/中间件/Nginx/Nginx编译安装.md
Normal file
41
src/content/posts/中间件/Nginx/Nginx编译安装.md
Normal file
@@ -0,0 +1,41 @@
|
||||
---
|
||||
title: Nginx编译安装
|
||||
published: 2025-07-18
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [Nginx编译安装]
|
||||
category: '中间件 > Nginx'
|
||||
draft: false
|
||||
lang: 'zh-cn'
|
||||
---
|
||||
|
||||
|
||||
# nginx编译安装
|
||||
|
||||
```
|
||||
wget https://nginx.org/download/nginx-1.28.0.tar.gz
|
||||
tar -zxvf ninx-1.28.0.tar.gz
|
||||
sudo apt install -y build-essential libtool zlib1g-dev openssl libpcre3 libpcre3-dev libssl-dev libgeoip-dev
|
||||
sudo apt install libpcre2-dev
|
||||
|
||||
# 常用模块配置
|
||||
./configure \
|
||||
--prefix=/usr/local/nginx \
|
||||
--pid-path=/var/run/nginx/nginx.pid \
|
||||
--lock-path=/var/lock/nginx.lock \
|
||||
--error-log-path=/var/log/nginx/error.log \
|
||||
--http-log-path=/var/log/nginx/access.log \
|
||||
--with-http_gzip_static_module \
|
||||
--http-client-body-temp-path=/var/temp/nginx/client \
|
||||
--http-proxy-temp-path=/var/temp/nginx/proxy \
|
||||
--http-fastcgi-temp-path=/var/temp/nginx/fastcgi \
|
||||
--http-uwsgi-temp-path=/var/temp/nginx/uwsgi \
|
||||
--http-scgi-temp-path=/var/temp/nginx/scgi \
|
||||
--with-stream \
|
||||
--with-http_ssl_module \
|
||||
--with-stream_ssl_preread_module # 新增:支持 ssl_preread 指令
|
||||
|
||||
make
|
||||
make install
|
||||
|
||||
```
|
||||
102
src/content/posts/中间件/Postgresql/postgresql一些容易混淆的概念.md
Normal file
102
src/content/posts/中间件/Postgresql/postgresql一些容易混淆的概念.md
Normal file
@@ -0,0 +1,102 @@
|
||||
---
|
||||
title: postgresql一些容易混淆的概念
|
||||
published: 2025-07-21
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [PostgreSQL, PostgreSQL容易混淆的概念]
|
||||
category: '中间件 > PostgreSQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
# PostgreSQL一些容易混淆的概念
|
||||
|
||||
https://www.cnblogs.com/noodlesmars/p/11850559.html
|
||||
|
||||
# Schema
|
||||
|
||||
在数据库创建的同时,就已经默认为数据库创建了一个模式--public,这也是该数据库的默认模式。所有为此数据库创建的对象(表、函数、试图、索引、序列等)都是创建在这个模式中的
|
||||
|
||||
一个数据库包含一个或多个Schema,一个Schema包含一个或多个表,一个表包含一个或多个字段,一个字段包含一个或多个值。
|
||||
我拿我们熟悉的MySQL数据库举例子,MySQL数据库中,数据库就是Schema,表就是Table,字段就是Column,值就是Value。
|
||||
但是在PgSQL中,数据库不是像MySQL那样的数据库了,它下面可以放很多Schema,而Schema下面才是Table,字段就是Column,值就是Value。
|
||||
|
||||
打个比方,mysql的database就是一个书柜,table是一个个的抽屉,column是抽屉里的书,value就是书的内容。
|
||||
但是在pgsql中,database是一个书房,schema是一个个书柜,table是一个个抽屉,column是抽屉里的书,value就是书的内容。
|
||||
|
||||
---
|
||||
PostgreSQL 的分层结构 (Database -> Schema -> Table) 的优势:
|
||||
|
||||
更好的逻辑隔离和组织: 在一个数据库内部,您可以使用 Schema 来对表、视图、函数等数据库对象进行逻辑分组。这对于大型项目、多租户应用或需要区分不同模块的数据非常有用。例如,在一个 my_app_db 数据库中,您可以有 public Schema (默认)、users Schema、orders Schema、analytics Schema 等。
|
||||
避免命名冲突: 不同的 Schema 可以包含同名的表。例如,users.accounts 和 orders.accounts 可以是两个完全不同的表,而不会冲突。这在 MySQL 中是不可能的,因为所有表都直接位于数据库下。
|
||||
权限管理: 您可以对 Schema 设置权限,控制用户对特定 Schema 内对象的访问,这提供了更细粒度的权限控制。
|
||||
数据迁移和管理: 在某些情况下,可以更容易地在 Schema 级别进行数据迁移或管理。
|
||||
MySQL 的扁平结构 (Database -> Table) 的特点:
|
||||
|
||||
简单直观: 对于小型项目或初学者来说,MySQL 的结构可能更直接和易于理解,因为没有额外的 Schema 层。
|
||||
兼容性: 许多其他数据库系统(如 SQL Server)也支持 Schema,但其概念可能与 PostgreSQL 更接近,而与 MySQL 的“数据库即 Schema”有所不同。
|
||||
|
||||
---
|
||||
|
||||
|
||||
|
||||
|
||||
# User & Role
|
||||
|
||||
在PostgreSQL中,存在两个容易混淆的概念:角色/用户。之所以说这两个概念容易混淆,是因为对于PostgreSQL来说,这是完全相同的两个对象。唯一的区别是在创建的时候:
|
||||
|
||||
1.我用下面的psql创建了角色custom:
|
||||
```sql
|
||||
CREATE ROLE custom PASSWORD 'custom';
|
||||
```
|
||||
|
||||
接着我使用新创建的角色custom登录,PostgreSQL给出拒绝信息:
|
||||
FATAL:role 'custom' is not permitted to log in.
|
||||
|
||||
说明该角色没有登录权限,系统拒绝其登录
|
||||
|
||||
2.我又使用下面的psql创建了用户guest:
|
||||
```sql
|
||||
CREATE USER guest PASSWORD 'guest';
|
||||
```
|
||||
接着我使用guest登录,登录成功
|
||||
|
||||
> 难道这两者有区别吗?查看文档,又这么一段说明:
|
||||
```sql
|
||||
CREATE USER is the same as CREATE ROLE except that it implies LOGIN. ----CREATE USER除了默认具有LOGIN权限之外,其他与CREATE ROLE是完全相同的。
|
||||
```
|
||||
|
||||
|
||||
# 表空间
|
||||
表空间是数据库中一个逻辑上的存储单元,它将数据库的物理存储位置(磁盘上的目录或文件)抽象出来,供数据库对象(如表、索引、大对象等)使用。
|
||||
|
||||
简单来说,你可以把表空间想象成数据库在磁盘上的一个个“存储分区”或“数据仓库”。数据库管理员 (DBA) 可以创建这些“仓库”,并指定它们实际位于哪个硬盘、哪个目录下。
|
||||
|
||||
核心要点:
|
||||
|
||||
逻辑与物理的桥梁: 表空间是连接数据库逻辑结构(Schema、表)与物理存储(文件系统)的桥梁。
|
||||
存储位置的抽象: 它不存储数据本身,而是定义了数据应该存储在哪个物理位置。
|
||||
管理单元: 它是 DBA 管理和优化存储资源的基本单位。
|
||||
|
||||
创建表空间 (CREATE TABLESPACE)
|
||||
这是定义一个新的存储位置的第一步。您需要指定表空间的名称和它在文件系统上的物理路径。
|
||||
|
||||
```sql
|
||||
-- 示例 1: 创建一个用于快速访问数据的表空间 (假设路径在 SSD 上)
|
||||
CREATE TABLESPACE fast_data_ts LOCATION '/mnt/ssd_data/pg_tablespaces/fast_data';
|
||||
|
||||
-- 示例 2: 创建一个用于归档或不常用数据的表空间 (假设路径在 HDD 上)
|
||||
CREATE TABLESPACE archive_data_ts LOCATION '/mnt/hdd_data/pg_tablespaces/archive_data';
|
||||
|
||||
-- 示例 3: 创建一个用于索引的专用表空间
|
||||
CREATE TABLESPACE index_ts LOCATION '/mnt/ssd_data/pg_tablespaces/indexes';
|
||||
|
||||
```
|
||||
|
||||
|
||||
重要提示:
|
||||
|
||||
LOCATION 指定的路径必须是绝对路径。
|
||||
PostgreSQL 服务器进程必须对该路径拥有读写权限。
|
||||
在创建表空间之前,您需要手动在文件系统上创建这些目录(例如:mkdir -p /mnt/ssd_data/pg_tablespaces/fast_data)。
|
||||
17
src/content/posts/中间件/Redis/RedisString底层.md
Normal file
17
src/content/posts/中间件/Redis/RedisString底层.md
Normal file
@@ -0,0 +1,17 @@
|
||||
---
|
||||
title: RedisString底层
|
||||
published: 2025-09-12
|
||||
description: ' RedisString底层 '
|
||||
image: ''
|
||||
tags: ['Redis', '中间件','RedisString底层']
|
||||
category: '中间件 > Redis'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# RedisString底层
|
||||
|
||||
RedisString底层是使用SDS(Simple Dynamic String)实现的,SDS是一个动态字符串,可以动态扩容。
|
||||
|
||||
|
||||
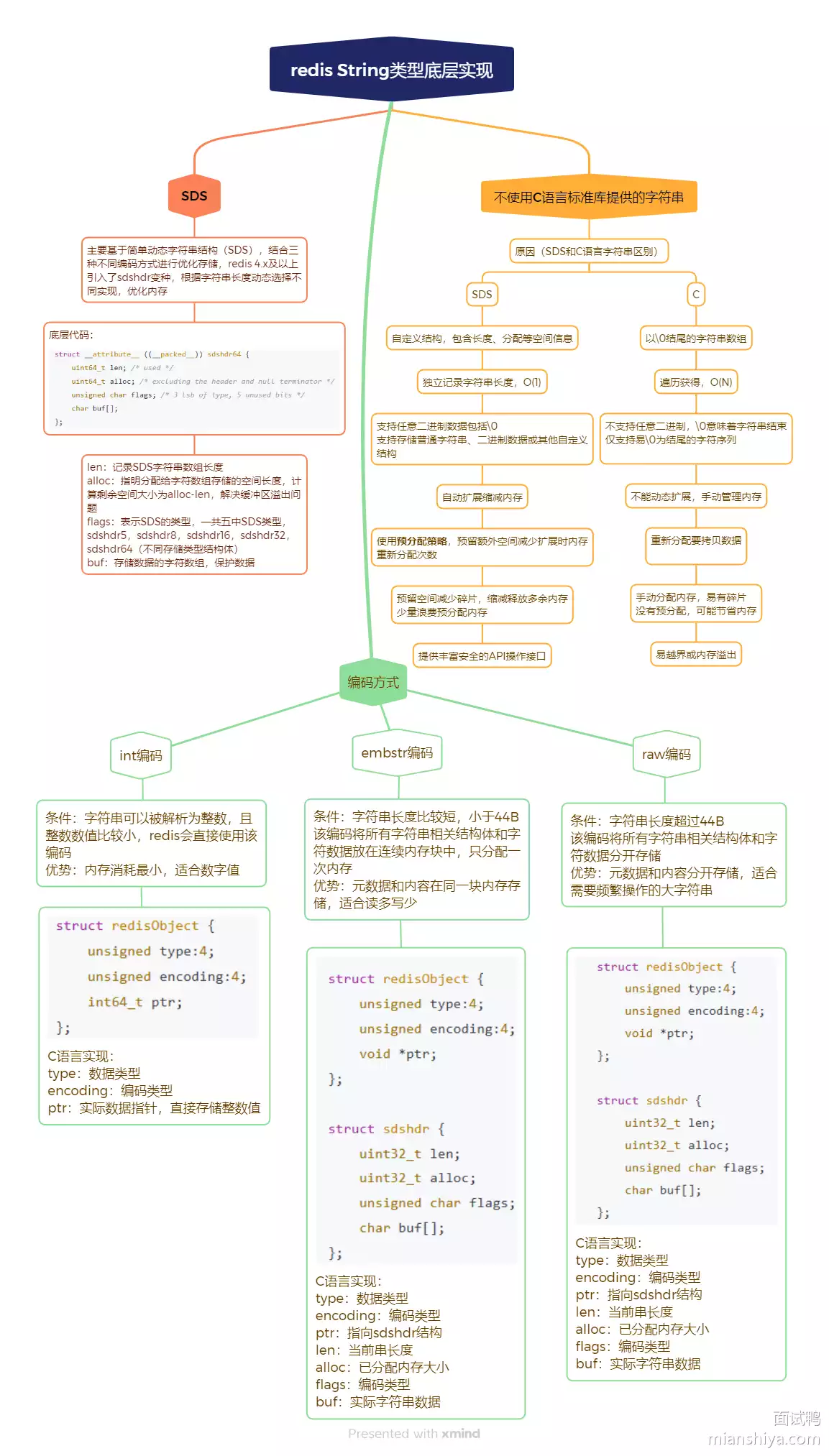
|
||||
27
src/content/posts/中间件/Redis/RedisZset实现原理.md
Normal file
27
src/content/posts/中间件/Redis/RedisZset实现原理.md
Normal file
@@ -0,0 +1,27 @@
|
||||
---
|
||||
title: RedisZset实现原理
|
||||
published: 2025-09-11
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['Redis']
|
||||
category: '中间件 > Redis'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# Redis ZSet实现原理
|
||||
|
||||
是一种由跳表和哈希表组成的数据结构。ZSet结合了集合的特性和排序功能,能存储具有唯一性的成员,并且根据成员的分数进行排序。
|
||||
|
||||
由
|
||||
- 跳表: 用于存储数据的排序和快速查找
|
||||
- 哈希表: 用于存储成员和它分数的映射,提供快速查找
|
||||
|
||||
|
||||
当元素数量较少的时候,Redis采用压缩列表来节省内存。
|
||||
元素个数<=zset-max-ziplist-entries,并且每个元素的值小于zset-max-ziplist-value
|
||||
|
||||
如果任何一个条件都不满足,Zset采用跳表加哈希表作为底层实现。
|
||||
|
||||
|
||||
|
||||
173
src/content/posts/中间件/Redis/Redisson延时队列架构.md
Normal file
173
src/content/posts/中间件/Redis/Redisson延时队列架构.md
Normal file
@@ -0,0 +1,173 @@
|
||||
---
|
||||
title: Redisson延时队列架构
|
||||
published: 2025-07-27
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['Redis','Redisson','延时队列']
|
||||
category: '中间件 > Redis'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
延时队列是一种特殊的消息队列,消息在发送后不会立即被消费,而是等待指定的时间后才被消费者处理。就像设置了一个"闹钟",到时间才响。
|
||||
|
||||
# 阻塞队列 RBlockingDeque - 阻塞双端队列
|
||||
特点:
|
||||
- 双端: 可以从两端插入和取出元素
|
||||
- 阻塞: 当队列为空的时候,取元素会阻塞等待
|
||||
- 线程安全: 多个线程可以安全操作
|
||||
|
||||
|
||||
```java
|
||||
// 特点:
|
||||
// - 双端:可以从两端插入和取出元素
|
||||
// - 阻塞:当队列为空时,取元素会阻塞等待
|
||||
// - 线程安全:多个线程可以安全操作
|
||||
|
||||
RBlockingDeque<String> deque = redissonClient.getBlockingDeque("myDeque");
|
||||
deque.offerFirst("头部元素");
|
||||
deque.offerLast("尾部元素");
|
||||
String element = deque.takeFirst(); // 阻塞获取
|
||||
|
||||
```
|
||||
|
||||
# RDelayedQueue - 延时队列
|
||||
|
||||
特点:
|
||||
- 自动延时:消息在指定时间后自动变为可消费状态
|
||||
- 精确控制:可以精确控制每个消息的延时时间
|
||||
- Redis实现:基于Redis的有序集合(ZSet)实现
|
||||
|
||||
```java
|
||||
|
||||
RDelayedQueue<String> delayedQueue = redissonClient.getDelayedQueue(deque);
|
||||
delayedQueue.offer("消息内容", 30, TimeUnit.SECONDS); // 30秒后可消费
|
||||
```
|
||||
|
||||
## 完整实现示例
|
||||
|
||||
### 生产者端(消息发送)
|
||||
```java
|
||||
@Service
|
||||
public class DelayQueueProducer {
|
||||
|
||||
@Autowired
|
||||
private RedissonClient redissonClient;
|
||||
|
||||
public void sendDelayedMessage(String message, long delaySeconds) {
|
||||
try {
|
||||
// 创建队列
|
||||
RBlockingDeque<String> blockingDeque = redissonClient
|
||||
.getBlockingDeque("DELAY_QUEUE_EXAMPLE");
|
||||
RDelayedQueue<String> delayedQueue = redissonClient
|
||||
.getDelayedQueue(blockingDeque);
|
||||
|
||||
// 发送延时消息
|
||||
delayedQueue.offer(message, delaySeconds, TimeUnit.SECONDS);
|
||||
|
||||
System.out.println("发送延时消息: " + message +
|
||||
", 延时: " + delaySeconds + "秒");
|
||||
} catch (Exception e) {
|
||||
log.error("发送延时消息失败", e);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 消费者端(消息处理)
|
||||
```java
|
||||
@Component
|
||||
public class DelayQueueConsumer {
|
||||
|
||||
@Autowired
|
||||
private RedissonClient redissonClient;
|
||||
|
||||
@PostConstruct
|
||||
public void startConsumer() {
|
||||
// 启动独立线程消费延时消息
|
||||
new Thread(this::consumeMessages, "DelayQueueConsumer").start();
|
||||
}
|
||||
|
||||
private void consumeMessages() {
|
||||
try {
|
||||
RBlockingDeque<String> blockingDeque = redissonClient
|
||||
.getBlockingDeque("DELAY_QUEUE_EXAMPLE");
|
||||
|
||||
while (!Thread.currentThread().isInterrupted()) {
|
||||
// 阻塞获取消息(自动等待延时到期)
|
||||
String message = blockingDeque.take();
|
||||
System.out.println("消费延时消息: " + message);
|
||||
|
||||
// 处理业务逻辑
|
||||
processMessage(message);
|
||||
}
|
||||
} catch (InterruptedException e) {
|
||||
Thread.currentThread().interrupt();
|
||||
log.info("消费者线程被中断");
|
||||
} catch (Exception e) {
|
||||
log.error("消费消息异常", e);
|
||||
}
|
||||
}
|
||||
|
||||
private void processMessage(String message) {
|
||||
// 实际的业务处理逻辑
|
||||
System.out.println("处理业务消息: " + message);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 底层实现原理
|
||||
|
||||
### Redis数据结构使用
|
||||
```bash
|
||||
# Redisson使用以下数据结构:
|
||||
# 1. 有序集合(ZSet) - 存储延时消息和到期时间
|
||||
ZADD delay_queue 1640995200 "message1" # 到期时间戳作为score
|
||||
|
||||
# 2. 列表(List) - 存储已到期可消费的消息
|
||||
LPUSH ready_queue "message1"
|
||||
|
||||
# 3. 定时任务 - 定期检查到期消息
|
||||
# Redisson内部使用定时任务扫描ZSet,将到期消息移动到List
|
||||
```
|
||||
|
||||
### 延时检查机制
|
||||
```java
|
||||
// Redisson内部逻辑(简化版)
|
||||
public class DelayedQueueChecker {
|
||||
public void checkExpiredMessages() {
|
||||
long now = System.currentTimeMillis();
|
||||
|
||||
// 从有序集合中获取已到期的消息
|
||||
Set<String> expiredMessages = redisTemplate
|
||||
.opsForZSet()
|
||||
.rangeByScore("delay_queue", 0, now);
|
||||
|
||||
for (String message : expiredMessages) {
|
||||
// 移动到可消费队列
|
||||
redisTemplate.opsForList().leftPush("ready_queue", message);
|
||||
redisTemplate.opsForZSet().remove("delay_queue", message);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
## 使用场景
|
||||
|
||||
```java
|
||||
// 1. 订单超时处理
|
||||
public void handleOrderTimeout(String orderId) {
|
||||
delayedQueue.offer(orderId, 30, TimeUnit.MINUTES);
|
||||
}
|
||||
|
||||
// 2. 优惠券到期提醒
|
||||
public void couponExpireReminder(String couponId) {
|
||||
delayedQueue.offer(couponId, 24, TimeUnit.HOURS);
|
||||
}
|
||||
|
||||
// 3. 消息重试机制
|
||||
public void messageRetry(String messageId) {
|
||||
delayedQueue.offer(messageId, 5, TimeUnit.SECONDS); // 5秒后重试
|
||||
}
|
||||
```
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user