feat: 新增多个Redis相关的文章,更新Footer和Navbar组件,优化配置文件,修改搜索文本
This commit is contained in:
18
src/content/posts/中间件/Redis/Redis为什么快.md
Normal file
18
src/content/posts/中间件/Redis/Redis为什么快.md
Normal file
@@ -0,0 +1,18 @@
|
||||
---
|
||||
title: Redis为什么快
|
||||
published: 2025-07-19
|
||||
description: ''
|
||||
image: 'https://blog.meowrain.cn/api/i/2025/07/19/p9zr81-1.webp'
|
||||
tags: [Redis, 中间件]
|
||||
category: '中间件 > Redis'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# Redis为什么快
|
||||
|
||||
1. 使用内存存储
|
||||
2. Redis采用了IO多路复用技术的事件驱动模型来处理客户端请求,执行Redis命令
|
||||
3. Redis6.0引入多线程机制,把网络和I/O处理放到多个线程中,减少了单线程的瓶颈,网络IO交给线程池处理,命令仍然在主线程中进行。充分利用CPU多核的优势,提升了性能。
|
||||
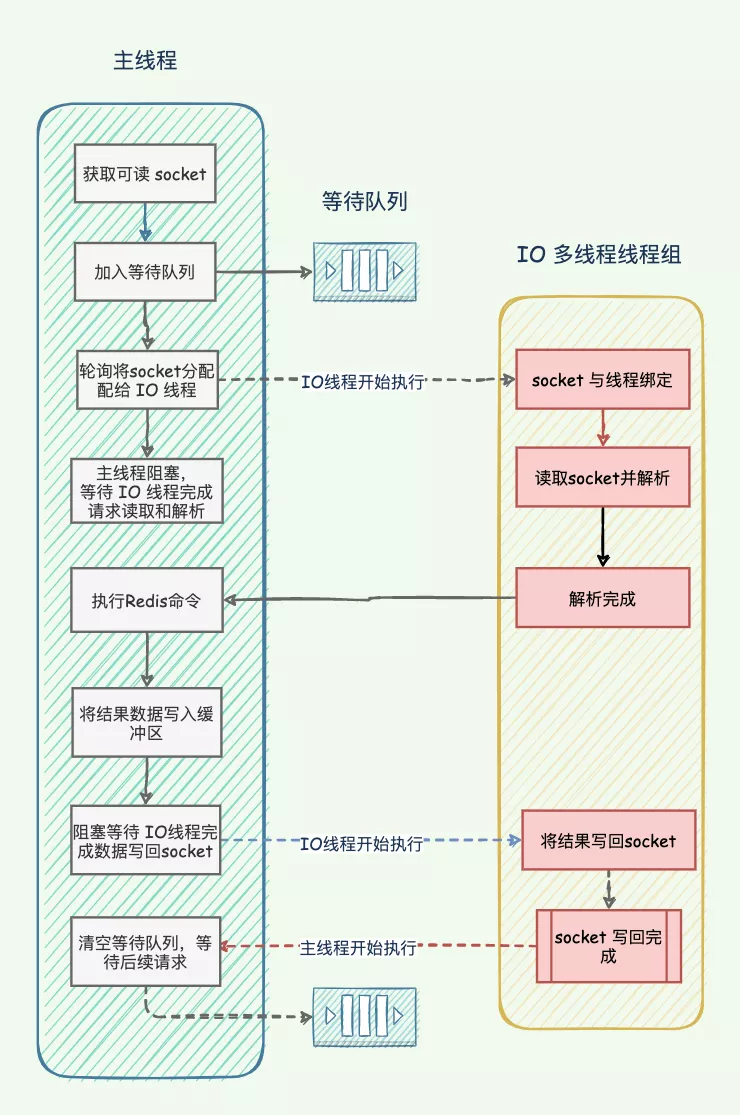
|
||||
4. Redis 对底层数据结构做了极致的优化,比如说 String 的底层数据结构动态字符串支持动态扩容、预分配冗余空间,能够减少内存碎片和内存分配的开销。
|
||||
102
src/content/posts/中间件/Redis/Redis有哪些数据类型.md
Normal file
102
src/content/posts/中间件/Redis/Redis有哪些数据类型.md
Normal file
@@ -0,0 +1,102 @@
|
||||
---
|
||||
title: Redis有哪些数据类型
|
||||
published: 2025-07-19
|
||||
description: ''
|
||||
image: 'https://blog.meowrain.cn/api/i/2025/07/19/p9zr81-1.webp'
|
||||
tags: [Redis, 中间件, Redis数据类型]
|
||||
category: '中间件 > Redis'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
# 官方文档
|
||||
|
||||
[Redis官方文档](https://redis.io/docs/latest/develop/data-types/)
|
||||
|
||||
|
||||

|
||||
|
||||
# 基本数据类型
|
||||
|
||||
Redis支持五种基本数据类型
|
||||
|
||||
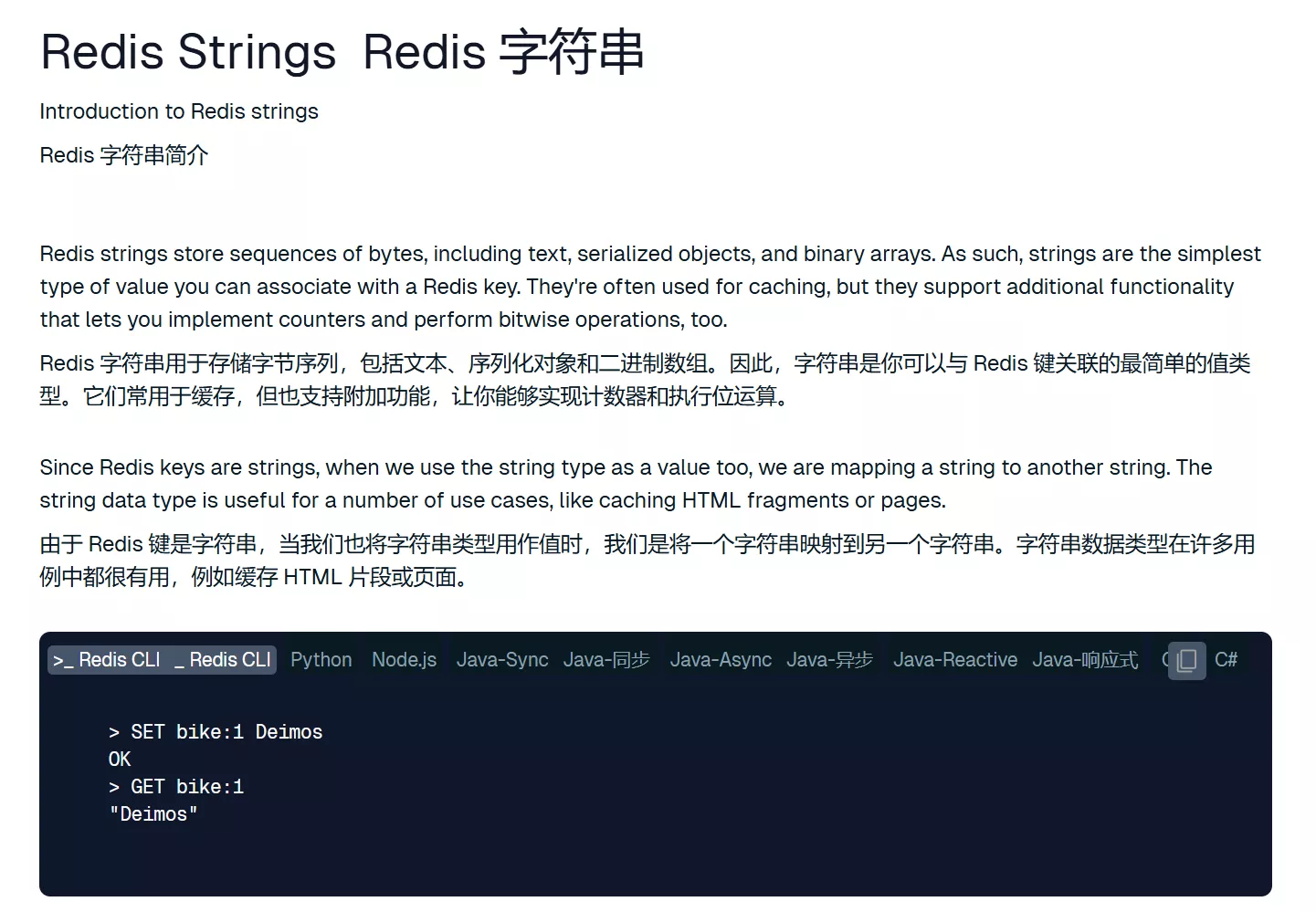
## 字符串
|
||||
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
字符串是最基本的数据类型,可以存储文本,数字或者二进制数据,最大的容量是512MB。适合缓存单个对象,比如验证码,token,计数器等。
|
||||
|
||||
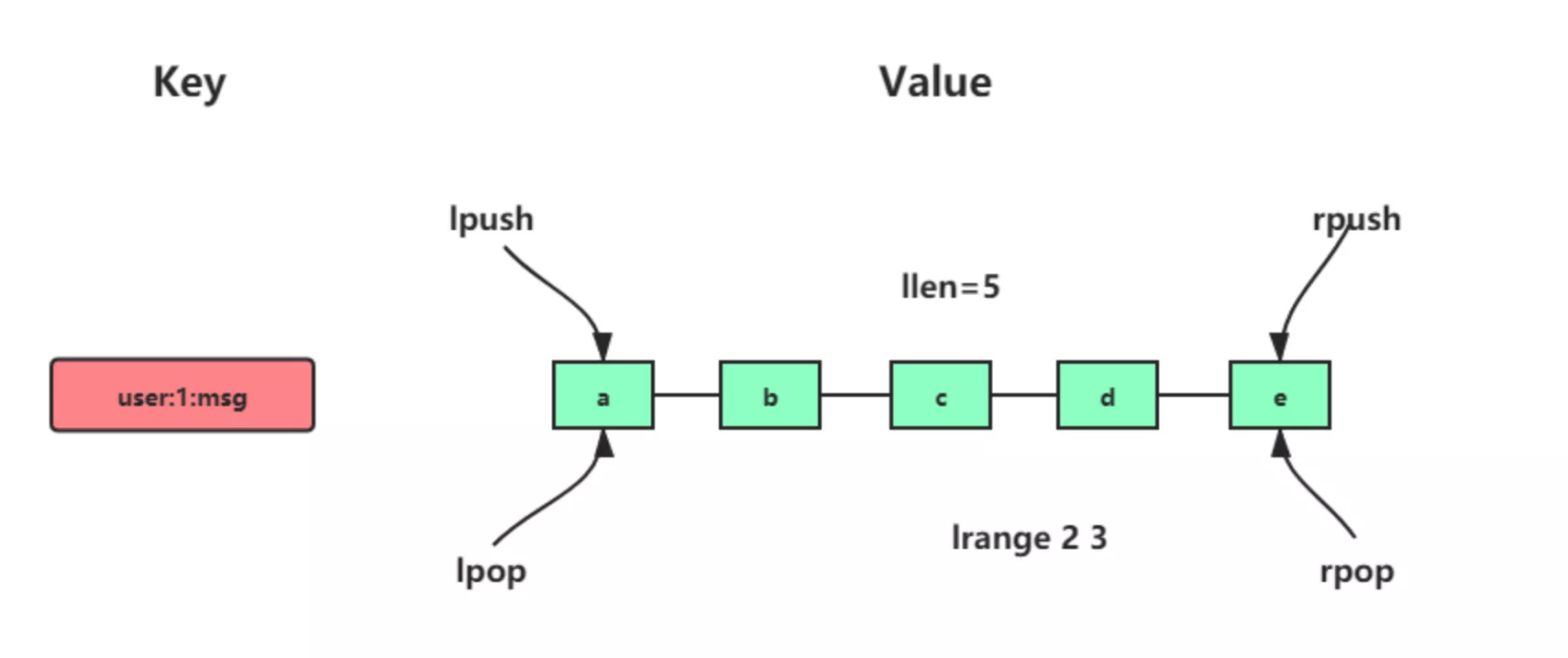
## 列表
|
||||
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
列表是一个有序的字符串集合,可以在头部或尾部插入元素,适合用于消息队列,任务调度等场景。
|
||||
|
||||
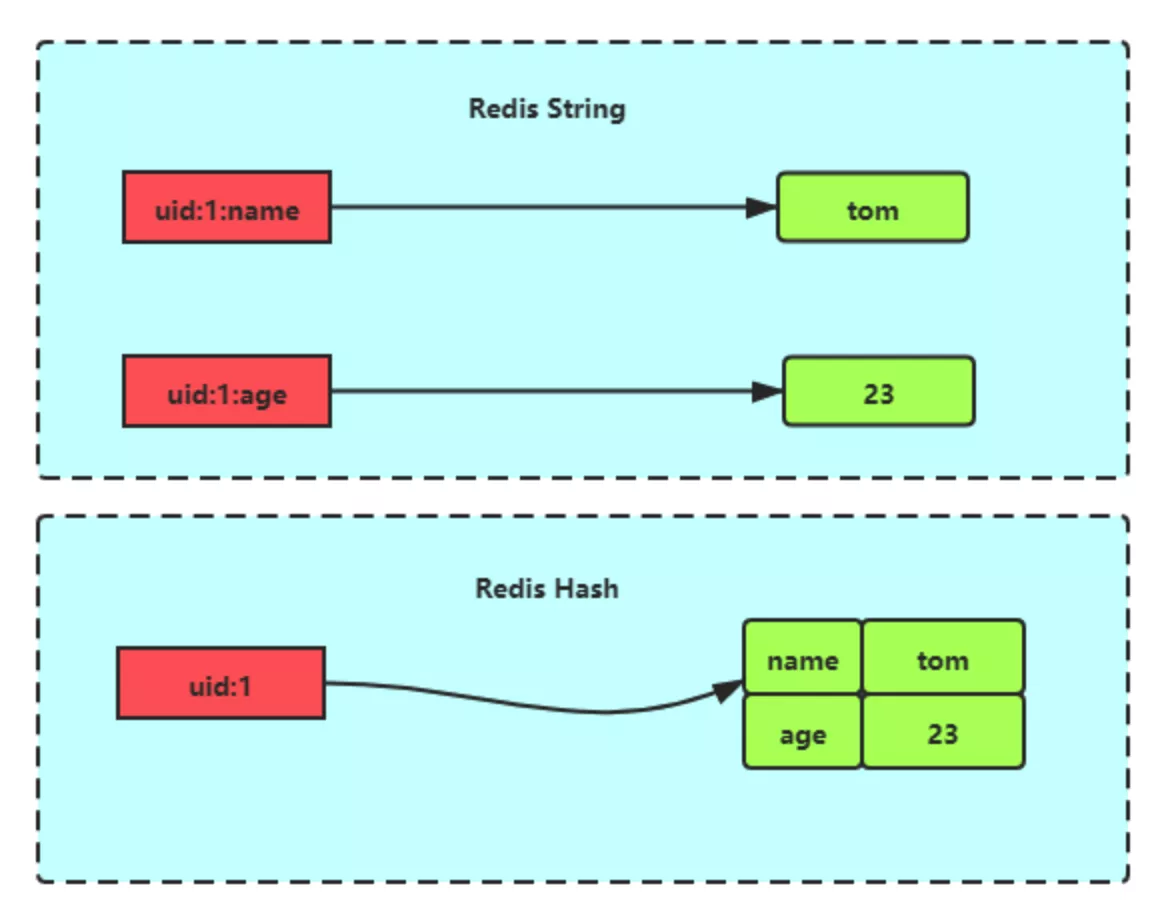
## 哈希
|
||||
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
哈希是一个键值对集合,适合用于存储对象。可以通过字段名快速访问字段值,支持对单个字段的操作,节省内存。
|
||||
|
||||
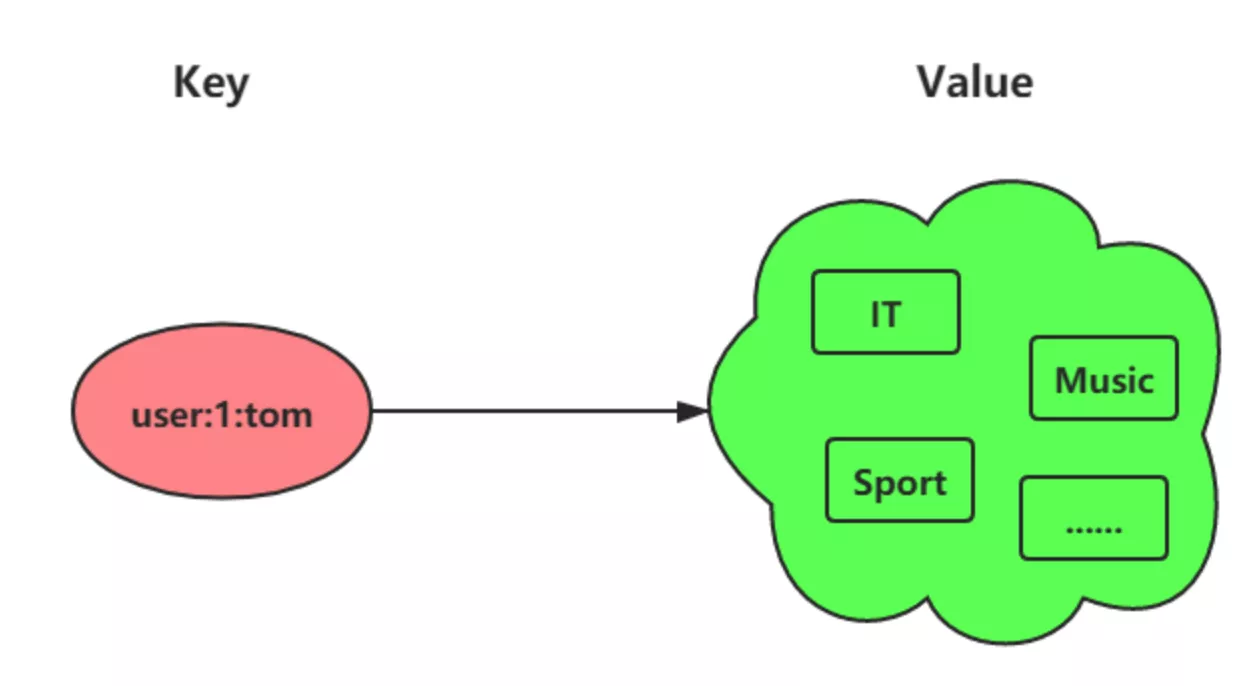
## 集合
|
||||
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
集合是一个无序的字符串集合,支持快速的成员查找,适合用于标签,好友关系等场景。
|
||||
可以进行集合运算,如交集,差集,并集等。
|
||||
平常拿来做一些去重操作。
|
||||
|
||||
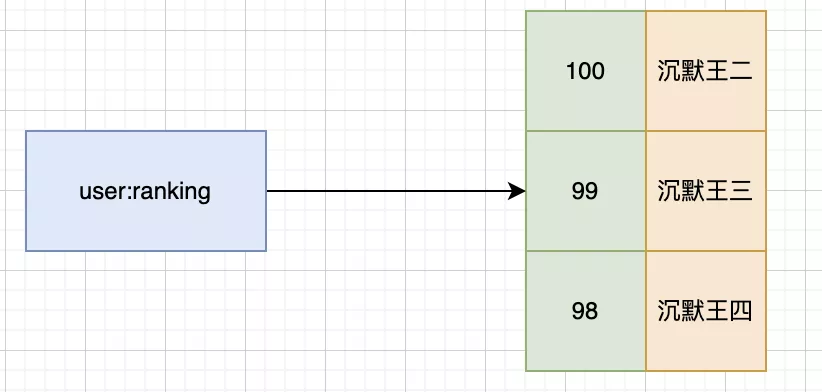
## 有序集合
|
||||
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
有序集合是一个有序的字符串集合,每个元素都有一个分数,支持根据分数进行范围查询,适合用于排行榜,消息队列等场景。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
# 扩展数据类型
|
||||
|
||||
[redis3种特殊类型详解](https://pdai.tech/md/db/nosql-redis/db-redis-data-type-special.html#redis%E5%85%A5%E9%97%A8---%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B3%E7%A7%8D%E7%89%B9%E6%AE%8A%E7%B1%BB%E5%9E%8B%E8%AF%A6%E8%A7%A3)
|
||||
|
||||
## 位图bitmap
|
||||
|
||||
[详细文档](https://redis.io/docs/latest/develop/data-types/bitmaps/)
|
||||
|
||||

|
||||
|
||||
位图是一个特殊的字符串类型,用于存储二进制位。可以用来统计用户活跃度,签到等场景。
|
||||
|
||||
## 基数统计HyperLogLog
|
||||
|
||||
[详细文档](https://redis.io/docs/latest/develop/data-types/probabilistic/hyperloglogs/)
|
||||
|
||||

|
||||

|
||||
|
||||
基数统计通常用于统计不重复的元素数量,比如网站访问量,用户注册量等。
|
||||
|
||||
## 地理位置Geo
|
||||
|
||||
存储地理信息
|
||||
|
||||
## Bloom Filter
|
||||
|
||||
[详细文档](https://redis.io/docs/latest/develop/data-types/probabilistic/bloom-filter/)
|
||||
58
src/content/posts/中间件/Redis/什么是Redis.md
Normal file
58
src/content/posts/中间件/Redis/什么是Redis.md
Normal file
@@ -0,0 +1,58 @@
|
||||
---
|
||||
title: 什么是Redis
|
||||
published: 2025-07-19
|
||||
description: ''
|
||||
image: 'https://blog.meowrain.cn/api/i/2025/07/19/p9zr81-1.webp'
|
||||
tags: [Redis, 中间件]
|
||||
category: '中间件 > Redis'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# 什么是Redis
|
||||
|
||||
Redis是一个开源的额高性能键值对存储系统,它可以用作数据库、缓存和消息代理。Redis支持多种数据结构,如字符串、哈希、列表、集合和有序集合等。
|
||||
主要特点是把数据存放在内存中,相比于直接访问磁盘的关系型数据库,读写速度会更快。
|
||||
|
||||
## Redis的特点
|
||||
|
||||
1. **高性能**:Redis可以每秒处理数百万个请求,读写速度非常快。
|
||||
2. **持久化**:Redis支持将数据持久化到磁盘,可以在重启后恢复数据。
|
||||
3. **丰富的数据结构**:支持字符串、哈希、列表、集合、有序集合等多种数据类型,适用于不同的应用场景。
|
||||
4. **原子操作**:Redis支持对数据的原子操作,保证数据的一致性。
|
||||
5. **分布式**:支持主从复制、分片和高可用集群,适合大规模应用。
|
||||
6. **发布/订阅**:支持发布/订阅模式,可以实现消息通知和实时数据更新。
|
||||
7. **Lua脚本**:支持Lua脚本,可以在服务器端执行复杂的操作,减少网络传输延迟。
|
||||
8. **事务支持**:支持事务操作,可以保证一组命令要么全部执行成功,要么全部不执行。
|
||||
9. **地理位置支持**:支持地理位置数据,可以进行地理位置查询和计算。
|
||||
10. **多种客户端支持**:提供多种编程语言的客户端库,如Java、Python、Node.js等
|
||||
11. **易于部署和使用**:Redis的安装和配置相对简单,社区活跃,有丰富的文档和教程。
|
||||
|
||||
# 使用场景
|
||||
|
||||
Redis常用于以下场景:
|
||||
|
||||
1. **缓存**:可以用来缓存数据库查询结果,减少数据库负载,提高
|
||||
2. **会话存储**:可以用来存储用户会话信息,支持高并发访问。
|
||||
3. **实时数据分析**:可以用来存储实时数据,如用户行为分析
|
||||
4. **消息队列**:可以用作消息队列系统,支持发布/订阅模式。
|
||||
5. **排行榜**:可以用来实现排行榜功能,支持有序集合数据结构。
|
||||
6. **分布式锁**:可以用来实现分布式锁,支持高并发场景下的资源控制。
|
||||
7. **地理位置服务**:可以用来存储地理位置信息,支持地理位置查询。
|
||||
8. **计数器**:可以用来实现计数器功能,如网站访问量统计。
|
||||
|
||||
# Redis分布式部署的方式
|
||||
|
||||
Redis的分布式部署方式主要有以下几种:
|
||||
|
||||
1. **主从复制(Master-Slave Replication)**:通过设置主节点和多个从节点,实现数据的复制和备份。主节点负责写操作,从节点负责读操作,可以提高读性能和数据安全性。
|
||||
2. **分片(Sharding)**:将数据分布到多个Redis实例中,每个实例存储一部分数据。可以通过哈希算法将数据分配到不同的实例,实现数据的水平扩展。常用的分片方式有一致性哈希(Consistent Hashing)和范围分片(Range Sharding)。
|
||||
3. **Redis集群(Redis Cluster)**:Redis官方提供的集群模式,支持自动分片和故障转移。Redis集群可以将数据分布到多个节点上,每个节点存储一部分数据,并且支持动态扩容和缩容。集群模式下,客户端可以通过集群节点的地址直接访问数据,无需额外的代理层。
|
||||
4. **Sentinel模式**:Redis Sentinel是Redis的高可用解决方案,可以监控Redis实例的状态,并在主节点发生故障时自动进行故障转移。Sentinel可以与主从复制结合使用,提供高可用性和自动恢复能力。
|
||||
|
||||
# 和MySQL的区别
|
||||
|
||||
Redis不是关系型数据库,而是一个键值对存储系统。
|
||||
Redis把数据存放在内存中,读写速度非常快,而MySQL是基于磁盘的关系型数据库,读写速度相对较慢。
|
||||
|
||||
实际开发中,会把Redis作为缓存层,存储一些热点数据,减少对MySQL的访问压力,提高系统性能。
|
||||
47
src/content/posts/操作系统/IO多路复用技术.md
Normal file
47
src/content/posts/操作系统/IO多路复用技术.md
Normal file
@@ -0,0 +1,47 @@
|
||||
---
|
||||
title: IO多路复用技术
|
||||
published: 2025-07-19
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [IO,操作系统]
|
||||
category: '操作系统'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# 参考资料
|
||||
|
||||

|
||||
|
||||
# 为什么要有IO多路复用技术?
|
||||
|
||||
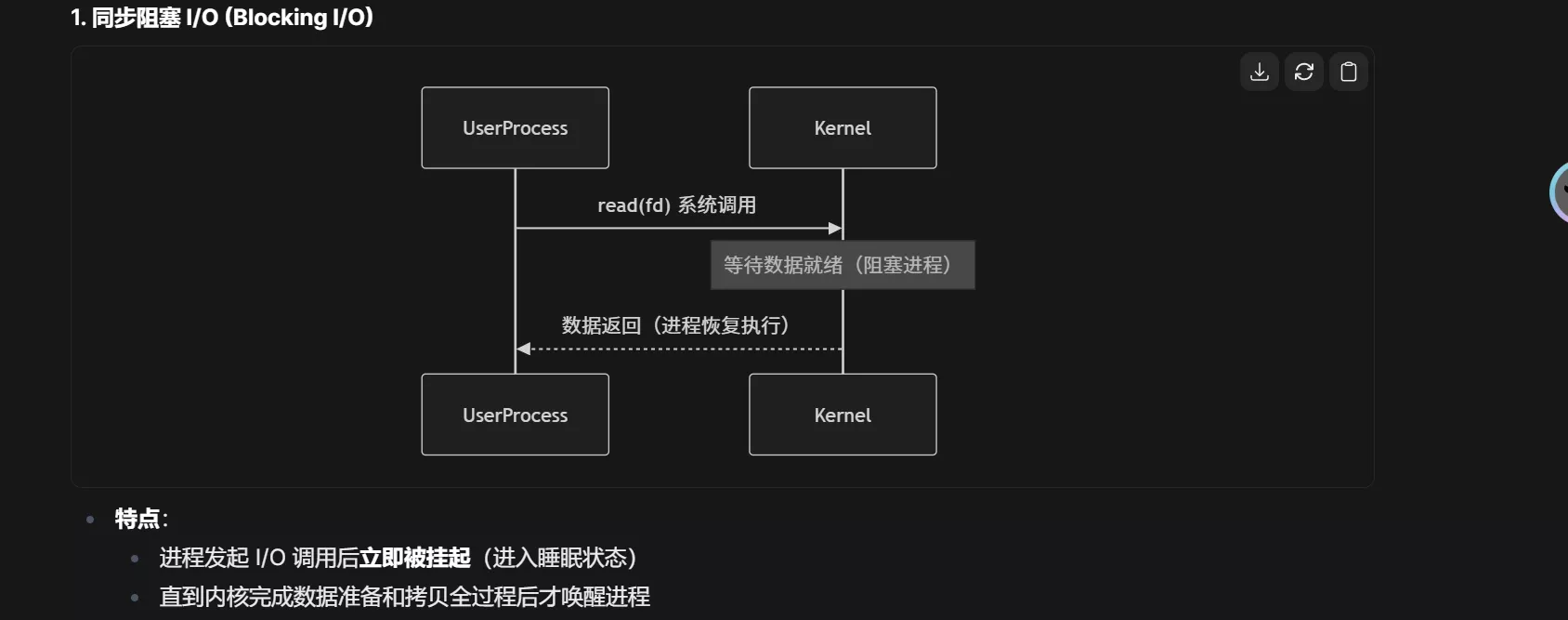
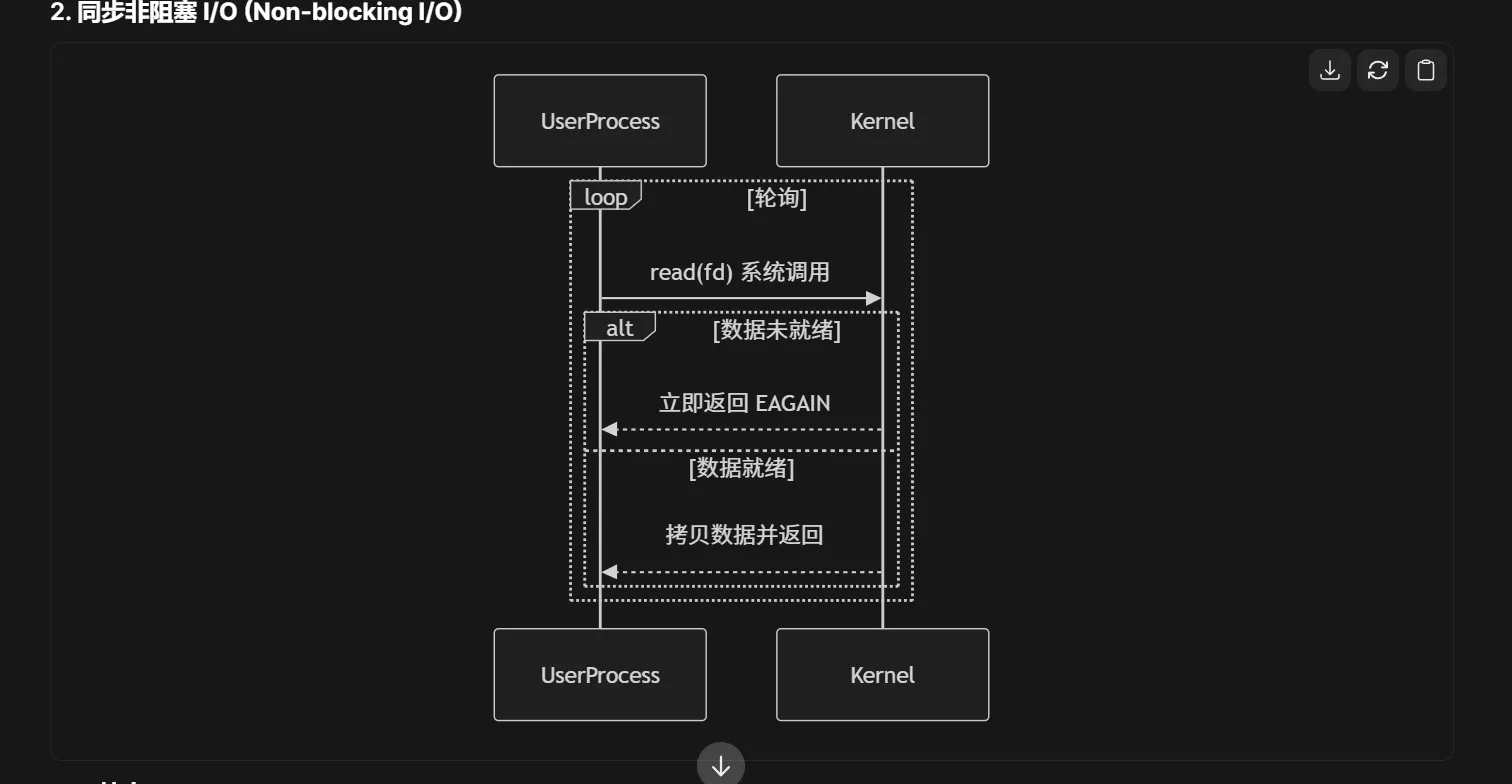
在没有 I/O 多路复用(如 select/poll/epoll)时,同步 I/O 确实主要分为以下两种模式:
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
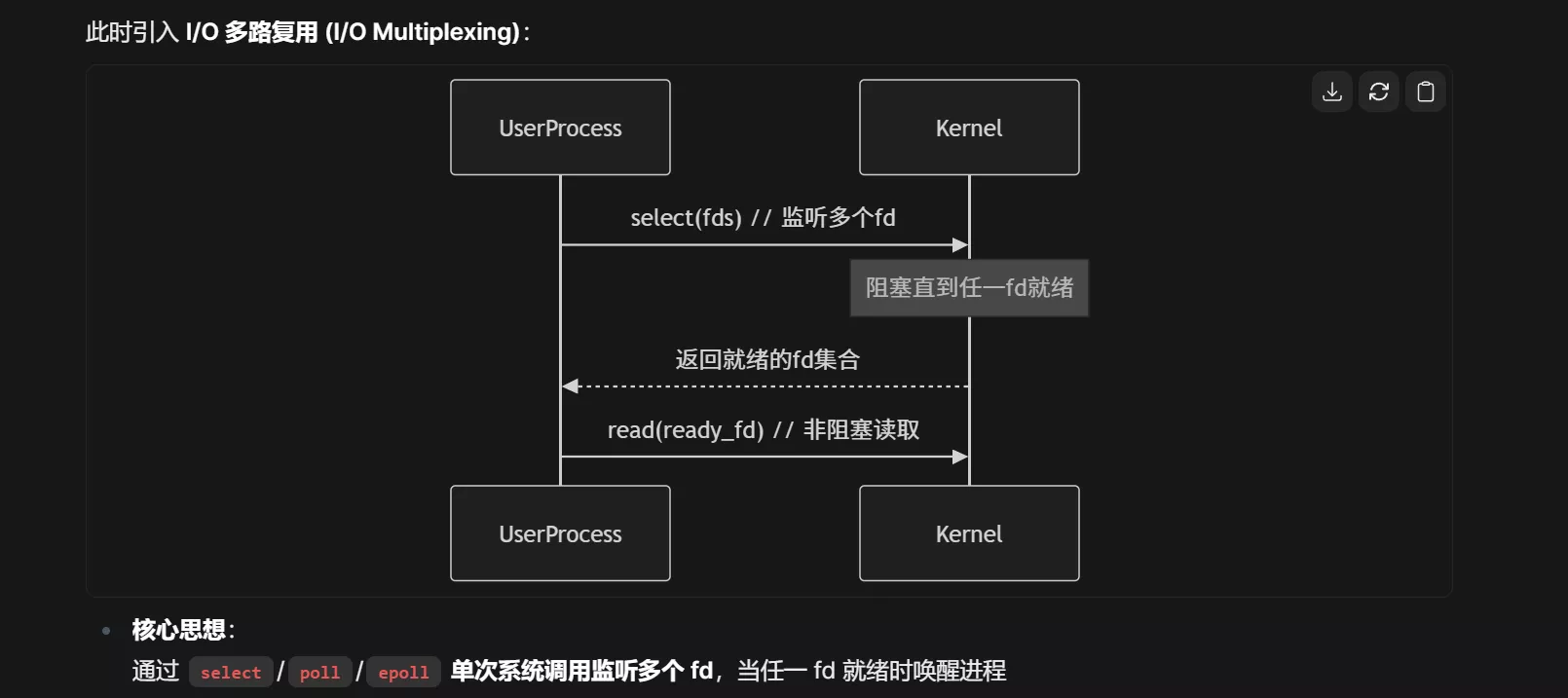
当处理 大量并发连接 时,上述两种同步模型存在致命缺陷:
|
||||
|
||||
阻塞 I/O:需要 1 线程/连接 → 线程切换开销大(C10K 问题)
|
||||
非阻塞 I/O:CPU 空转轮询 → 资源浪费严重
|
||||
|
||||
|
||||

|
||||
|
||||
# IO多路复用技术
|
||||
|
||||
IO多路复用是一种允许单个进程同时监视多个文件描述符的技术,使得程序能高效处理多个并发连接而无需创建大量线程。
|
||||
|
||||
## **select/poll/epoll**
|
||||
|
||||
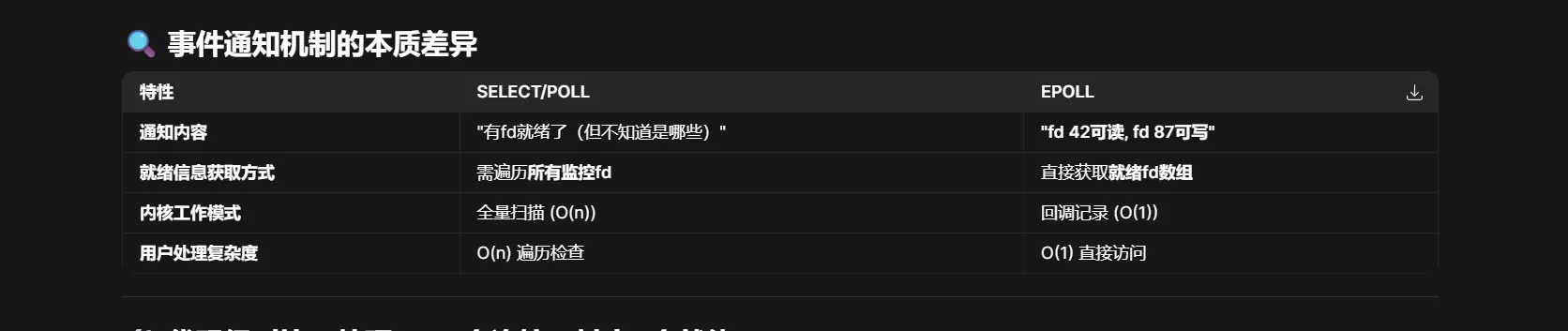
select 的缺点是单个进程能监视的文件描述符数量有限,一般为 1024 个,且每次调用都需要将文件描述符集合从用户态复制到内核态,然后遍历找出就绪的描述符,性能较差。
|
||||
|
||||
poll 的优点是没有最大文件描述符数量的限制,但是每次调用仍然需要将文件描述符集合从用户态复制到内核态,依然需要遍历,性能仍然较差。
|
||||
|
||||
epoll 是 Linux 特有的 IO 多路复用机制,支持大规模并发连接,使用事件驱动模型,性能更高。其工作原理是将文件描述符注册到内核中,然后通过事件通知机制来处理就绪的文件描述符,不需要轮询,也不需要数据拷贝,更没有数量限制,所以性能非常高。
|
||||
|
||||
epoll使用了事件驱动模型
|
||||
|
||||
|
||||
Reference in New Issue
Block a user